Case study
The use case where streaming pipelines in Mage outperform Spark Structured Streaming involves processing streaming data with high efficiency and low latency. Specifically, the example provided involves a company that needed to transform stream data and write it to MongoDB. Using Spark Structured Streaming on Databricks for this task, the company experienced an average latency of 1.2 to 1.9 seconds, and for larger size messages, the latency could go up to 3 to 4 seconds. This level of latency was not optimal for their requirements, which necessitated a more efficient solution. Upon switching to Mage’s streaming pipelines, they were able to significantly reduce the latency of their data processing and writing operations to MongoDB. They achieved a latency of less than 200 milliseconds, even for larger size messages. This represents a substantial improvement over their previous setup with Spark Structured Streaming, making Mage’s streaming pipelines a better choice for their specific use case.Performance difference
Spark Streaming processes data in micro-batches, which inherently introduces a delay as data is collected over a period before being processed. This micro-batching approach, while effective for many use cases, is not truly real-time. Mage’s performance advantage over Spark Streaming in real-time data processing scenarios include focus on real-time streaming (as opposed to micro-batching), simpler configuration and setup process, and reduced need for performance tuning. It’s designed with streaming pipelines that can handle data in real-time, reducing latency significantly for applications that require immediate data processing and insights.Benefits
The key benefits of using Mage’s streaming pipelines in this context include:- Reduced latency
- Mage’s streaming pipelines provided a drastic reduction in latency, from seconds to milliseconds, which is crucial for real-time data processing and analytics applications.
- Simplicity and efficiency
- Mage’s approach to streaming pipelines allows for a more straightforward and efficient data processing workflow, reducing the complexity and overhead associated with managing Spark Structured Streaming jobs.
- Scalability and flexibility
- Mage’s streaming pipelines are designed to be scalable and flexible, accommodating varying data volumes and processing requirements without significant adjustments to the infrastructure.
Introduction
Each streaming pipeline has three components:- Source: The data stream source to consume message from.
- Transformer: Write python code to transform the message before writing to destination.
- Sink (destination): The data stream destination to write message to.
In version
0.8.80 or greater.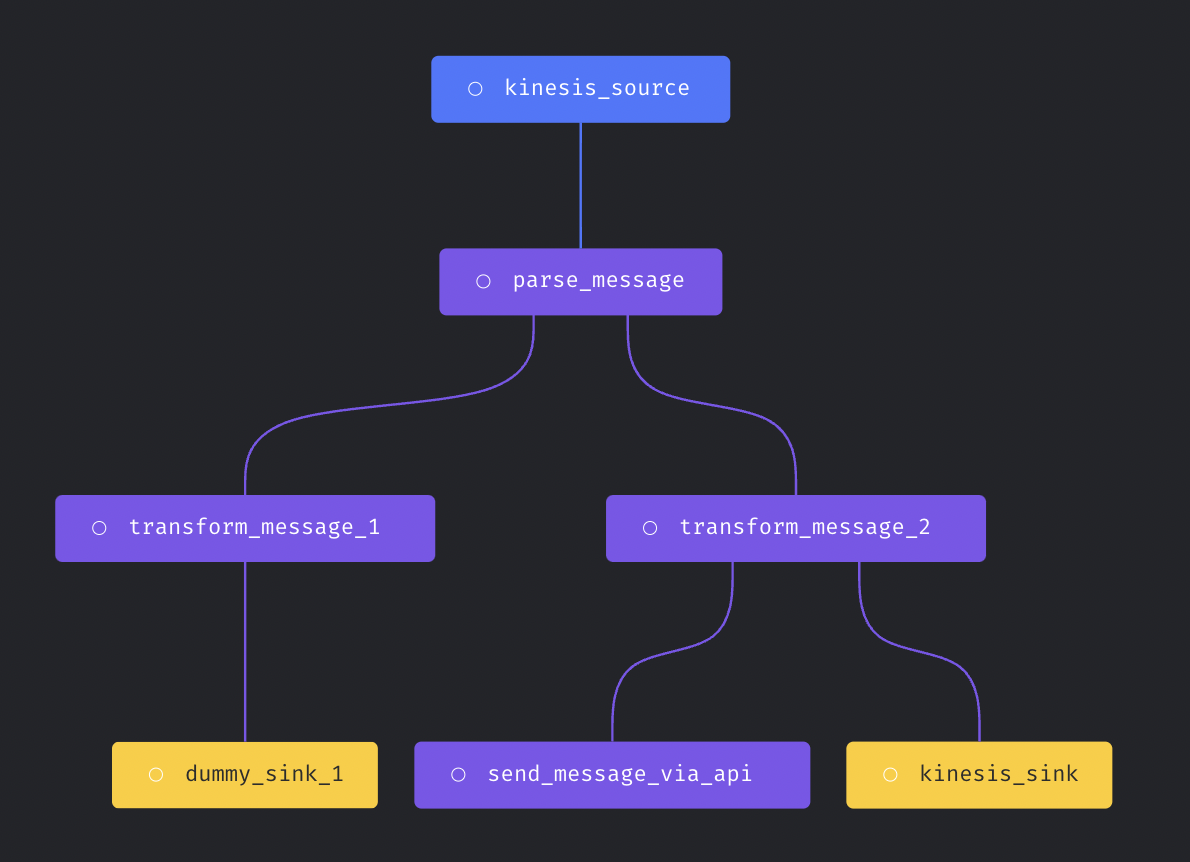
Supported sources
Supported sinks (destinations)
- Amazon S3
- BigQuery
- ClickHouse
- DuckDB
- Dummy
- Elasticsearch
- Kafka
- Kinesis
- MongoDB
- Microsoft SQL Server
- MySQL
- Opensearch
- Postgres
- Redshift
- Snowflake
- Trino
Test pipeline execution
After finishing configuring the streaming pipeline, you can click the buttonExecution pipeline to test streaming pipeline execution.
Run pipeline in production
Create the trigger in triggers page to run streaming pipelines in production.Executor count
If you want to run multiple executors at the same time to scale the streaming pipeline execution, you can set theexecutor_count variable
in the pipeline’s metadata.yaml file. Here is an example:
Executor type
When running Mage on Kubernetes cluster, you can also configure streaming pipeline to be run on separate k8s pods by settingexecutor_type
field in the pipeline’s metadata.yaml to k8s.
Example config: