Overview
Mage allows you to reuse blocks across multiple pipelines within the same project, enabling you to build modular, maintainable data pipelines. When you reuse a block, any changes made to that block will automatically apply to all pipelines that use it.Benefits of reusing blocks
- Code efficiency - Write once, use many times
- Consistency - Ensure the same logic is applied across all pipelines
- Maintenance - Update logic in one place and it applies everywhere
- Modularity - Build complex pipelines from smaller, reusable components
- Testing - Test block logic once and reuse with confidence
Reuse Scenarios and Methods
How block sharing works
When you create a block in one pipeline, you can reference that same block in other pipelines. The block file exists in the project’s file system and can be imported by any pipeline within the same project.Block sharing indicators
When viewing a pipeline, you’ll see indicators showing which blocks are shared:- Shared blocks display a symbol like
<> 2 pipelinesin the block header - Non-shared blocks show no additional symbols
- The number indicates how many pipelines are using that block
Viewing pipelines using a block
To see which pipelines are using a specific block:- Click on a block in the pipeline editor
- Open block settings - Click the settings icon in the right side panel
- View “Pipelines using this block” - See a list of all pipelines that reference this block
- Check project paths - See which project each pipeline belongs to
Methods to reuse blocks
Drag and drop from file browser
This is the most intuitive way to reuse blocks across pipelines:- Open the file browser on the Pipeline Editor page
- Navigate to the block you want to reuse in the file browser
- Click and hold the block file
- Drag the block file onto the center of the page (the Notebook area)
- Release the button and the block will be added to the pipeline
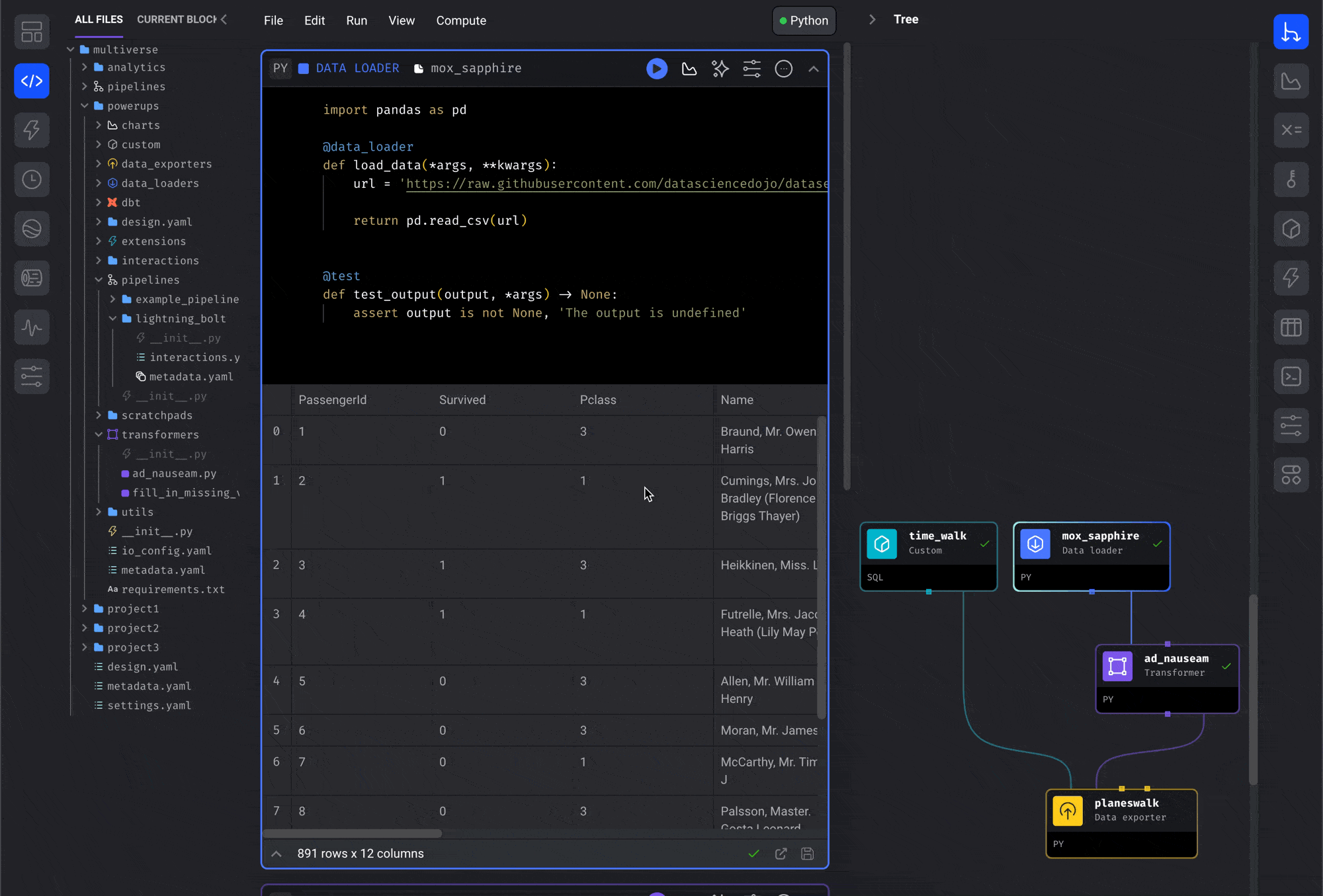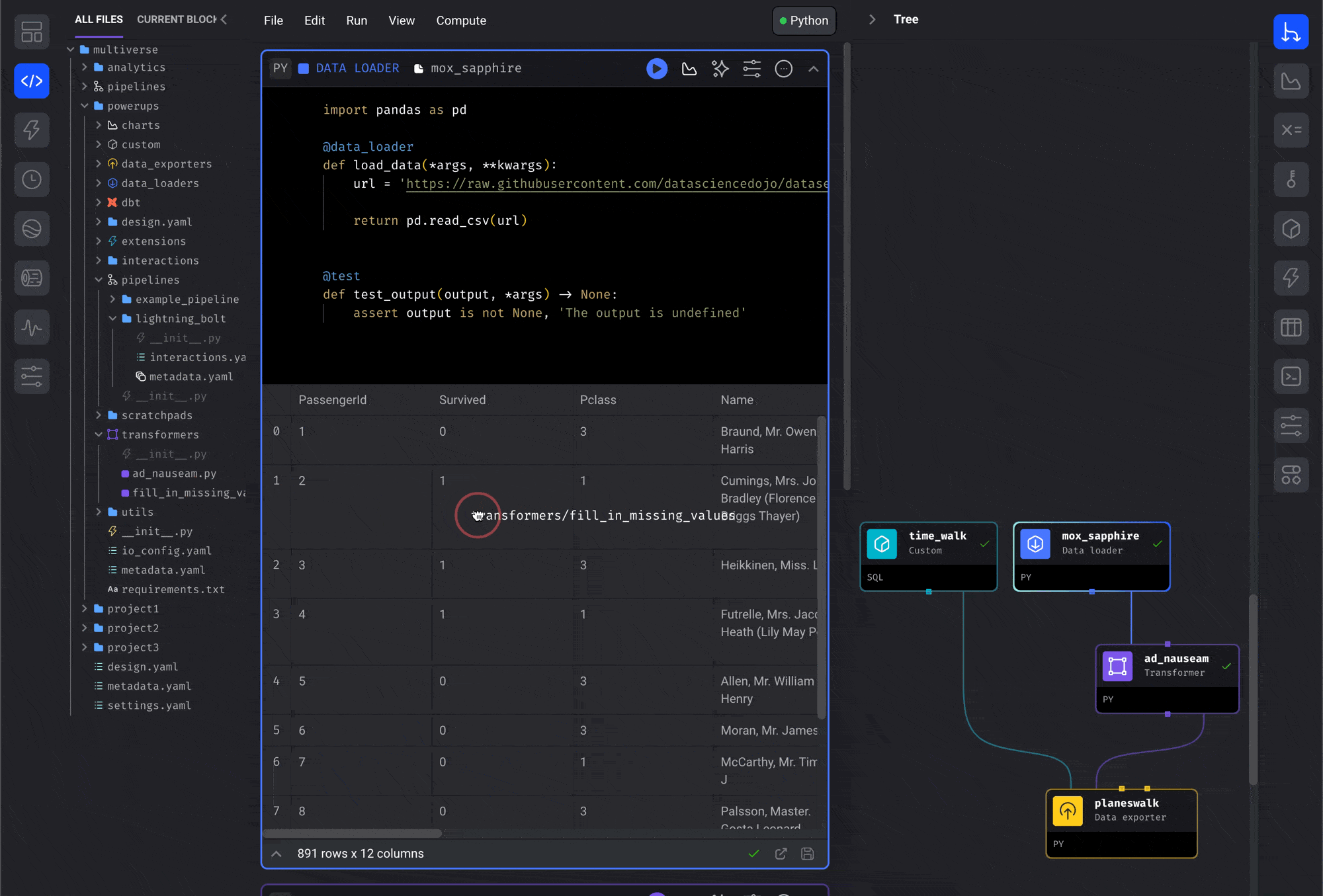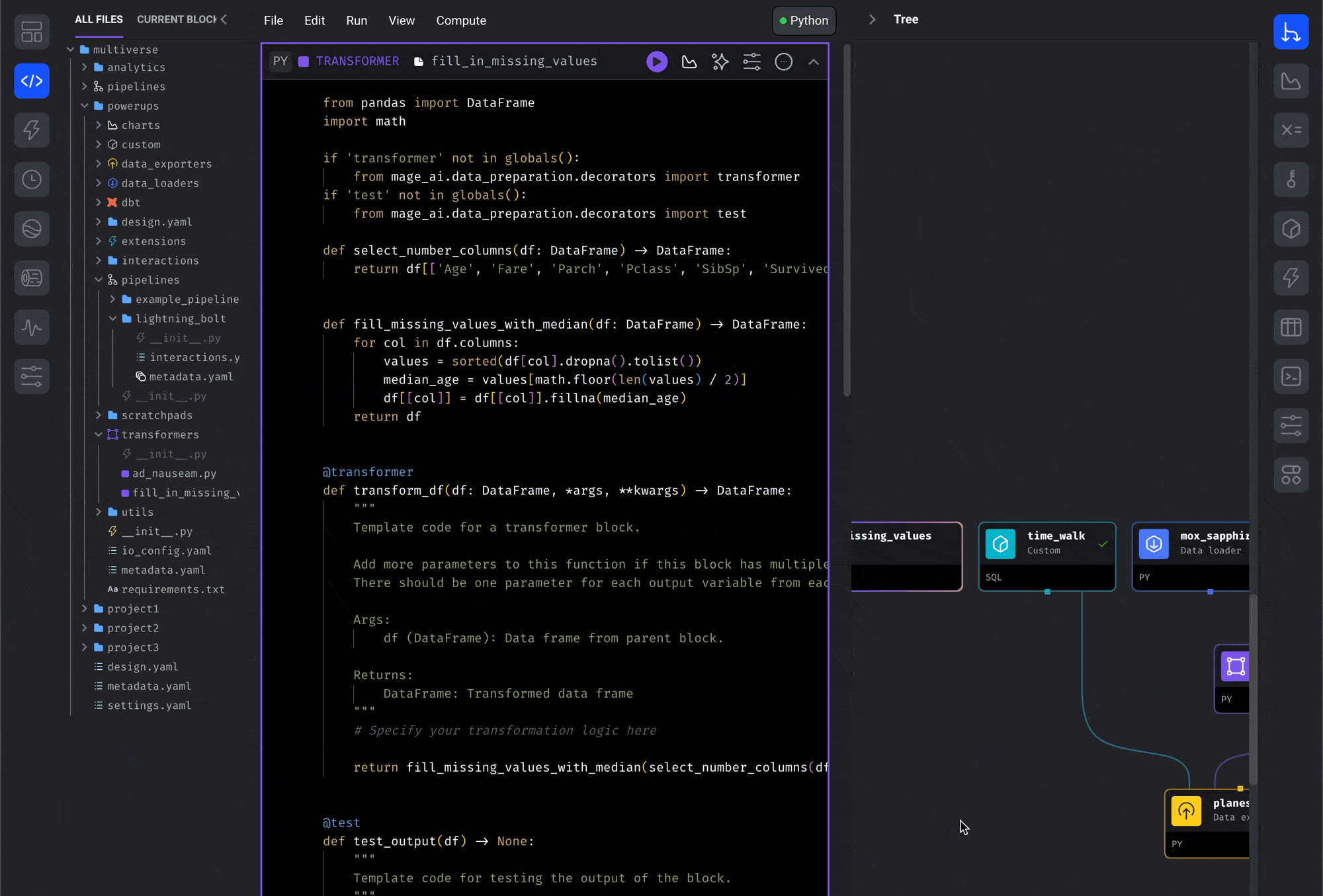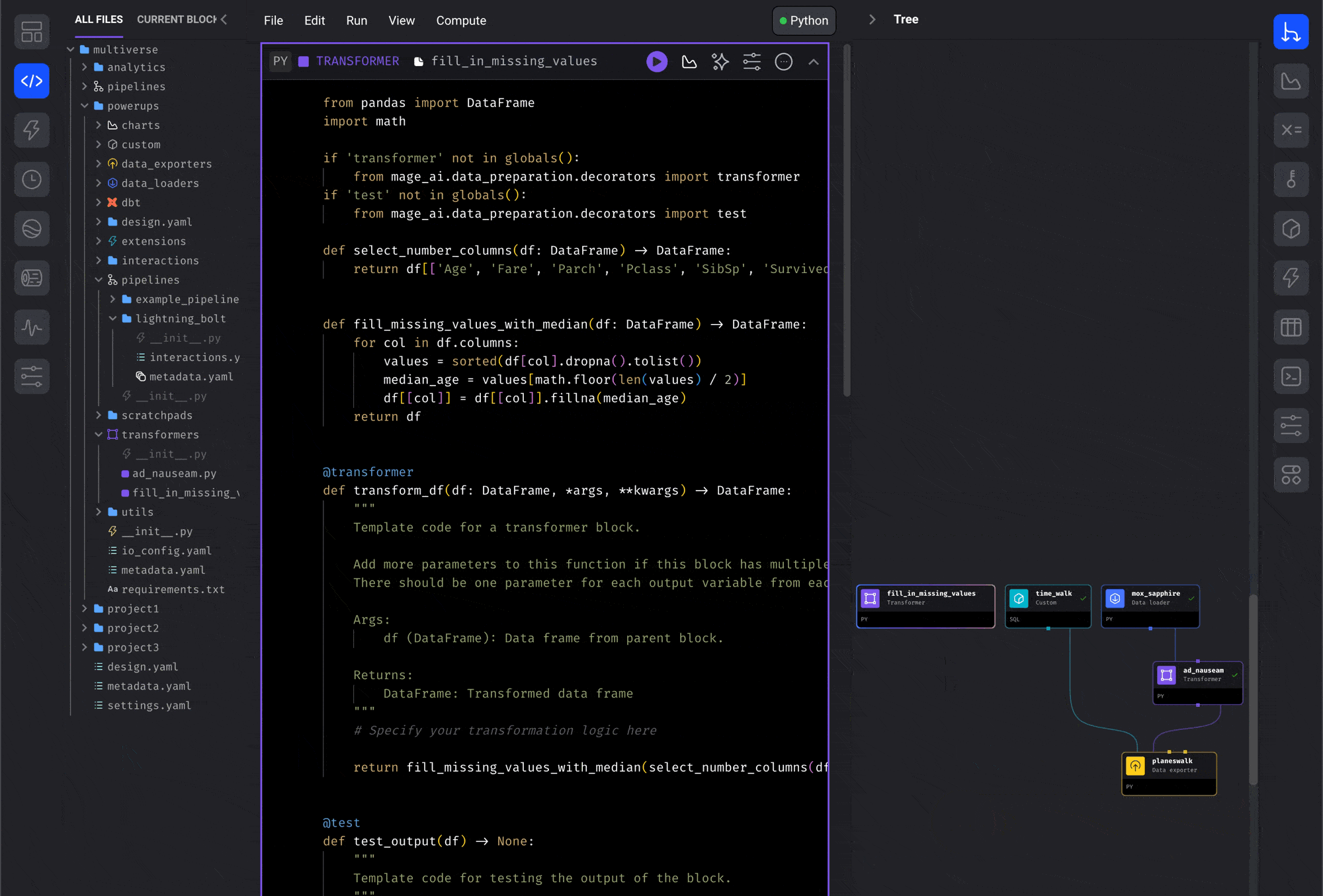
callbacks,conditionals,custom,data_exporters,data_loadersdbt,dbts,markdowns,scratchpads,sensors,transformers
Mage OSS: Version 0.9.64 or greater is required to add callback and conditional blocks from the file browser.Mage Pro: Callback and conditional blocks are supported by default in all versions.
Use the search block bar
Search for existing blocks across all your projects:- Click in the search bar at the bottom of the pipeline editor
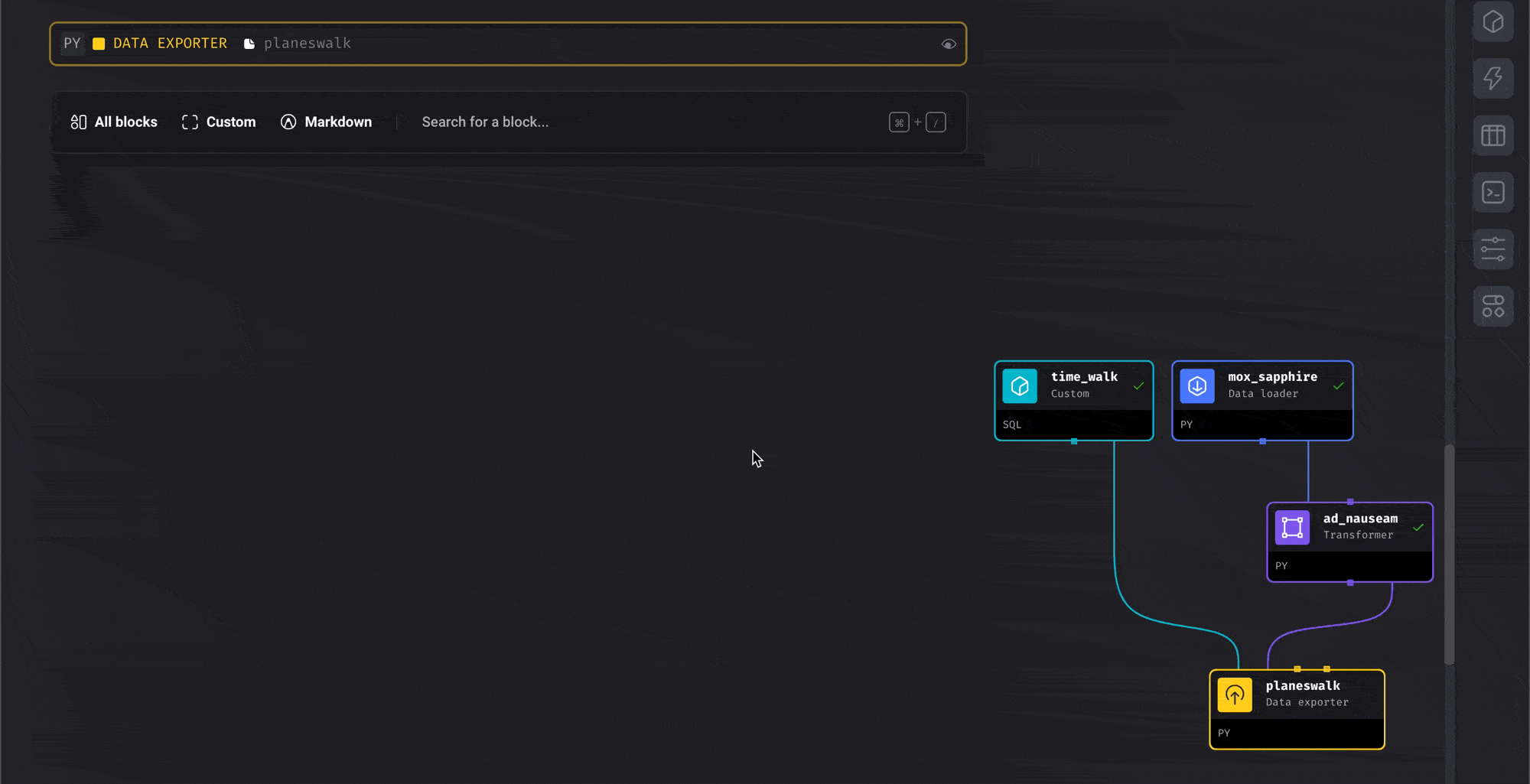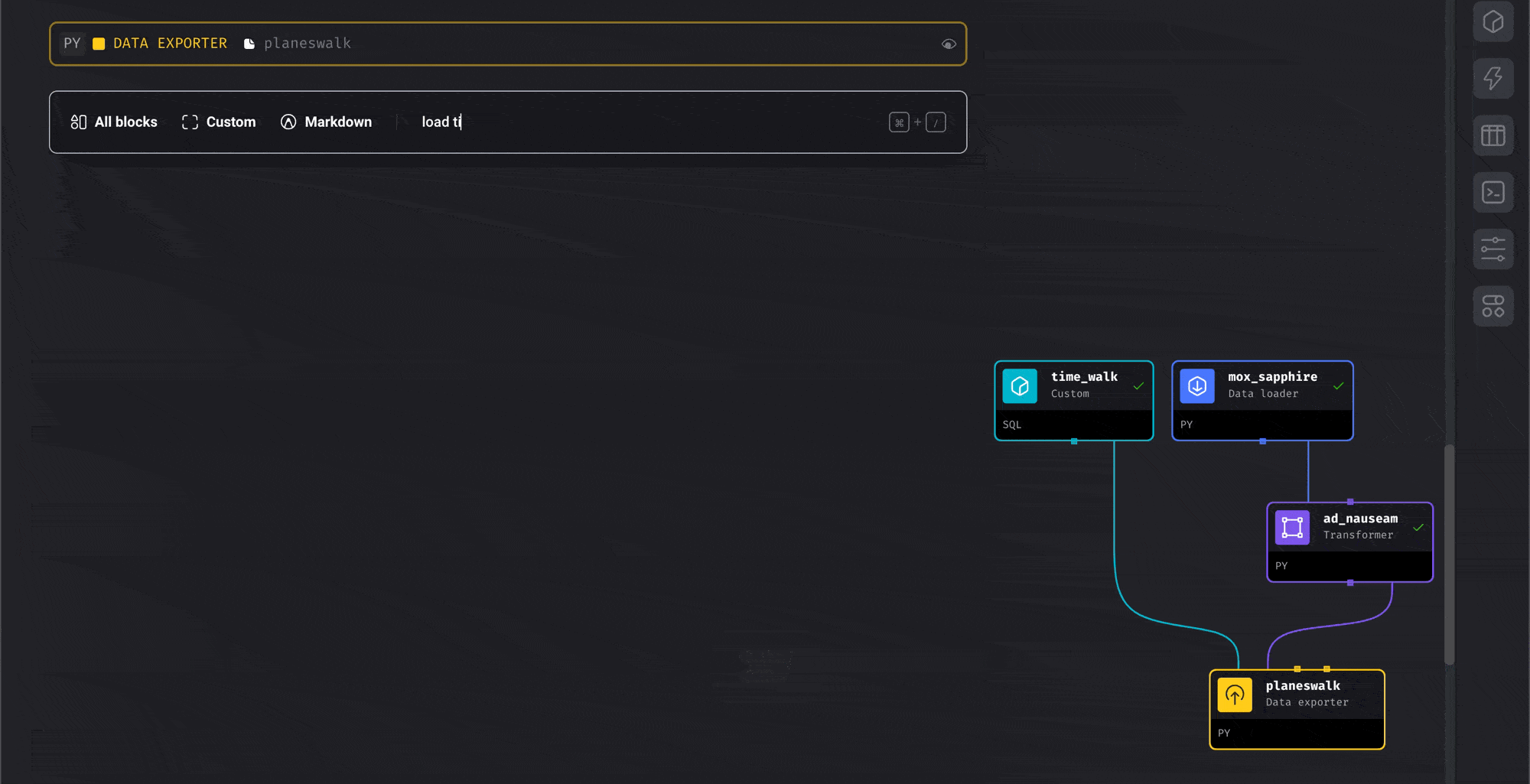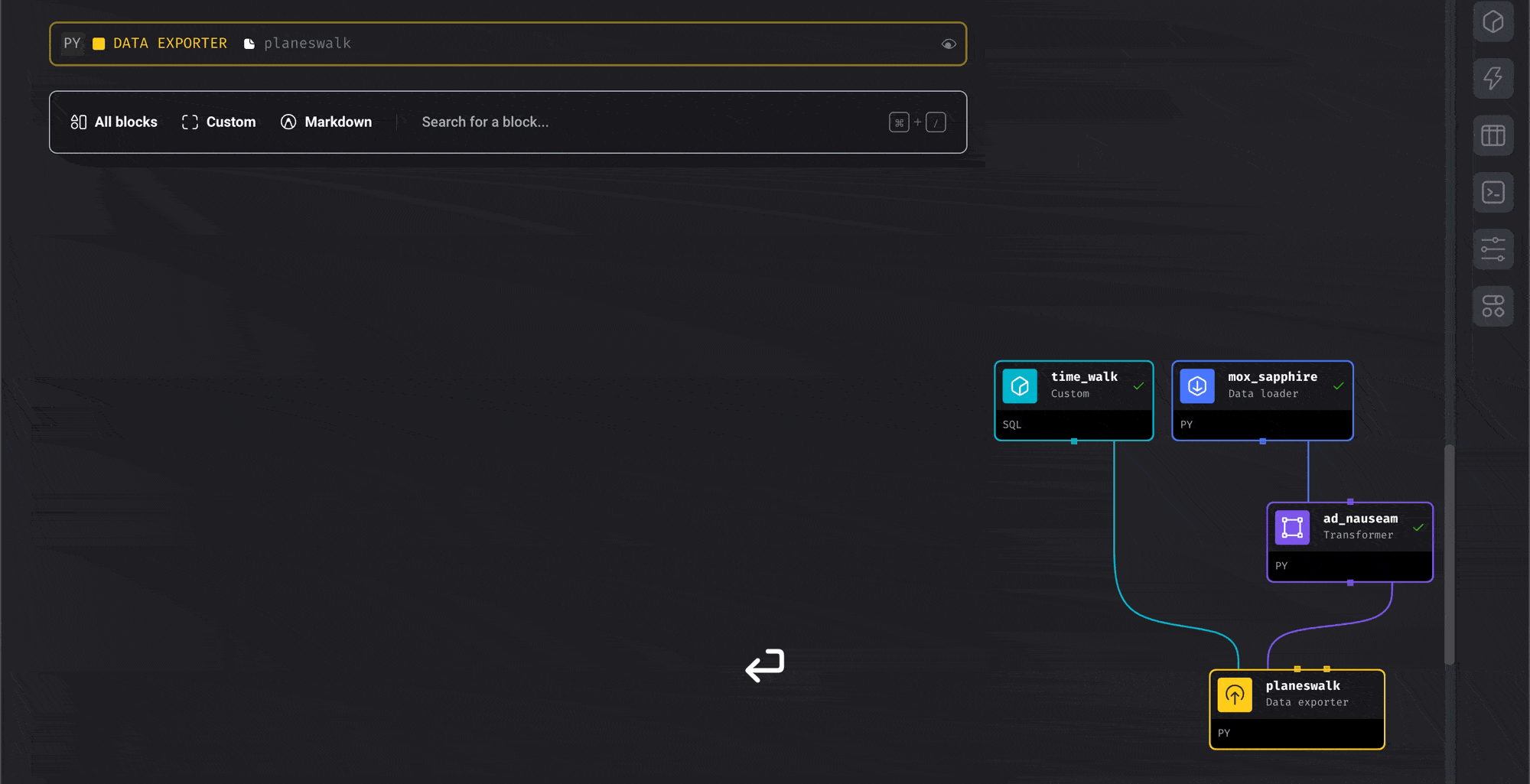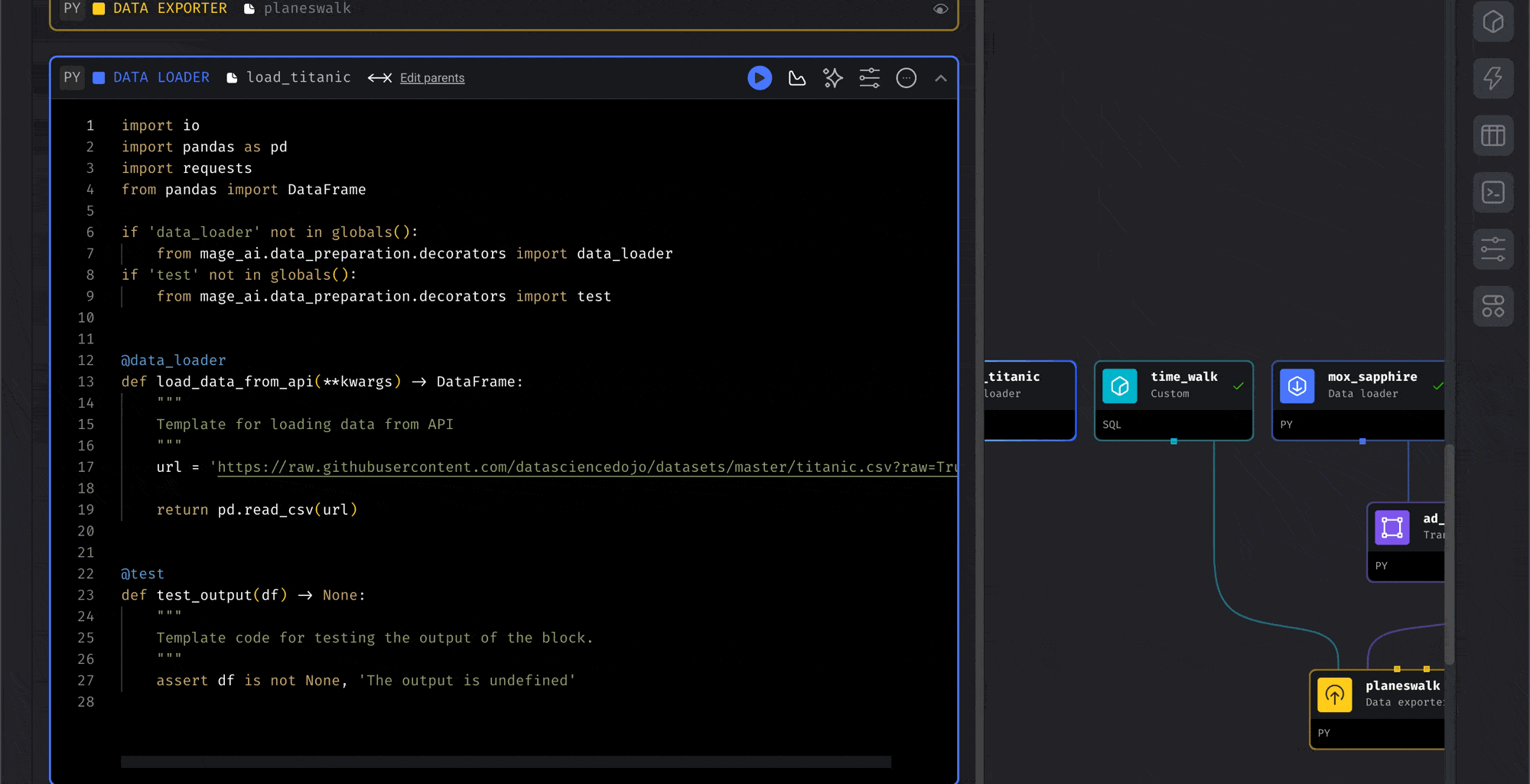
- Type keywords to search for existing blocks (e.g., “load titanic”)
- Browse the search results showing blocks from different projects
- Click on a block from the dropdown to add it to your pipeline
- The block will be added to your current pipeline
Mage OSS: The “Add new block v2” feature must be enabled in project settings and is available in standard (batch) pipelines. If recently enabled, Mage must be restarted for blocks to be indexed.Mage Pro: This feature is enabled by default and available in all pipeline types.
Replicate blocks within a pipeline
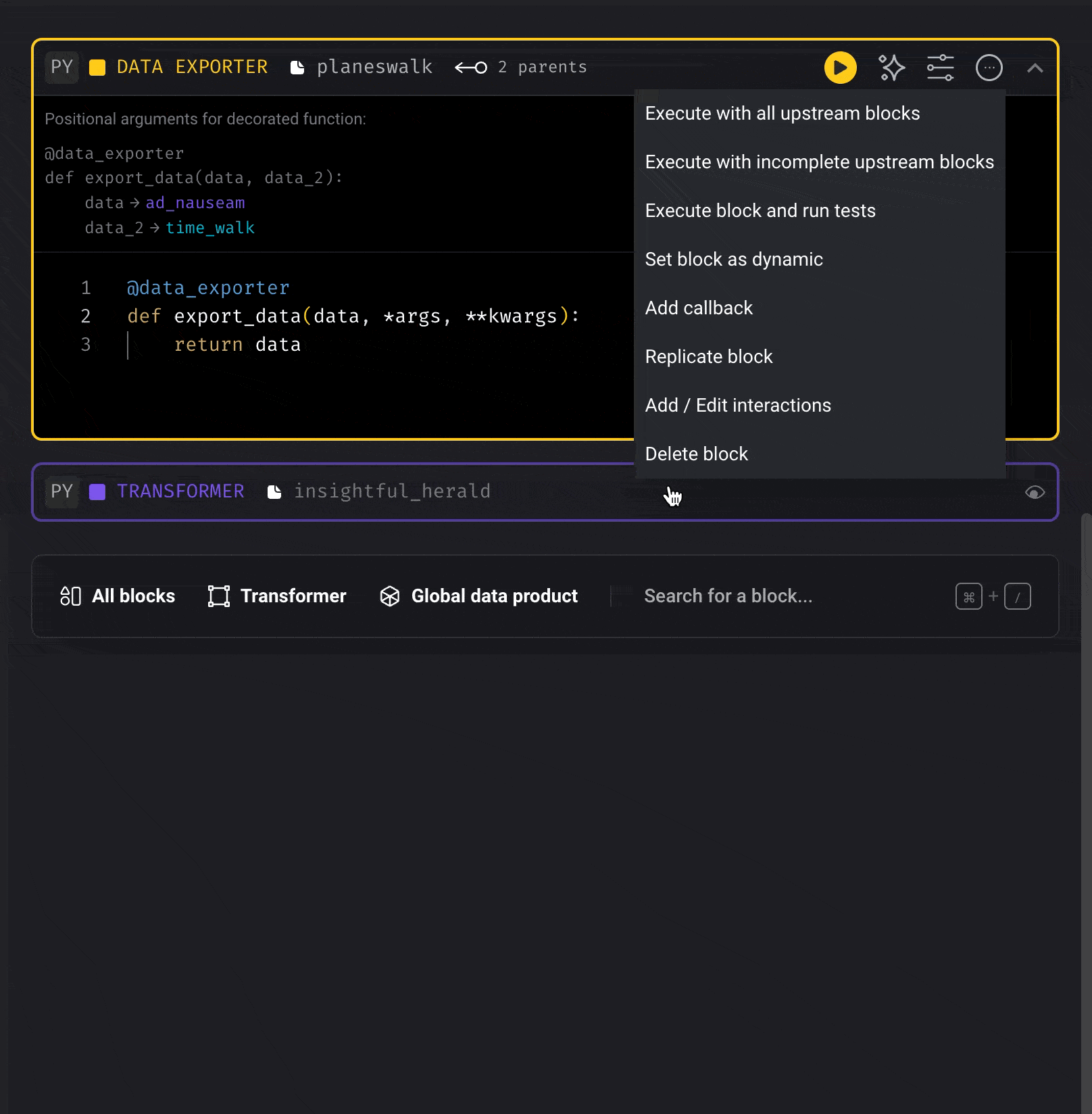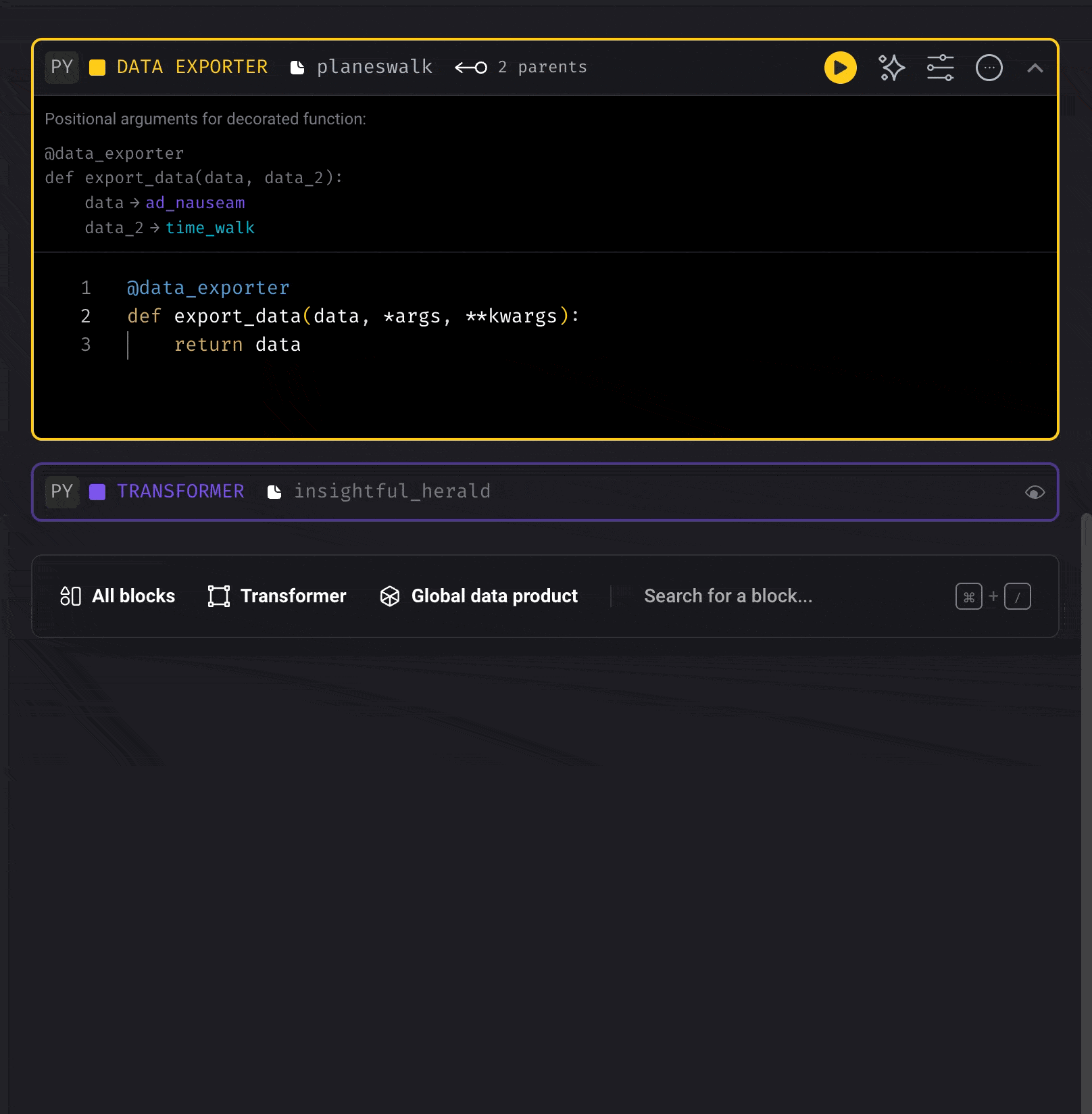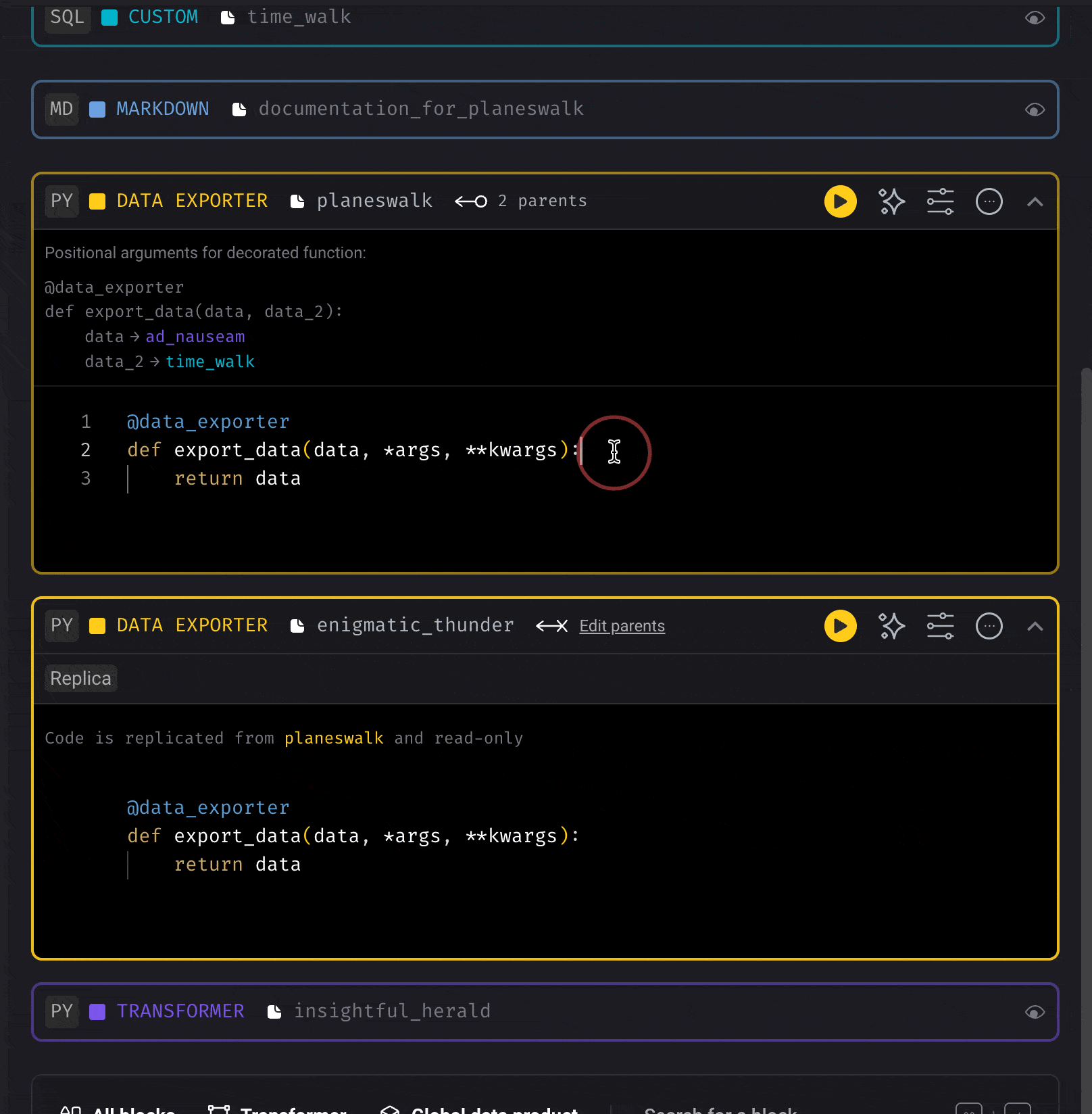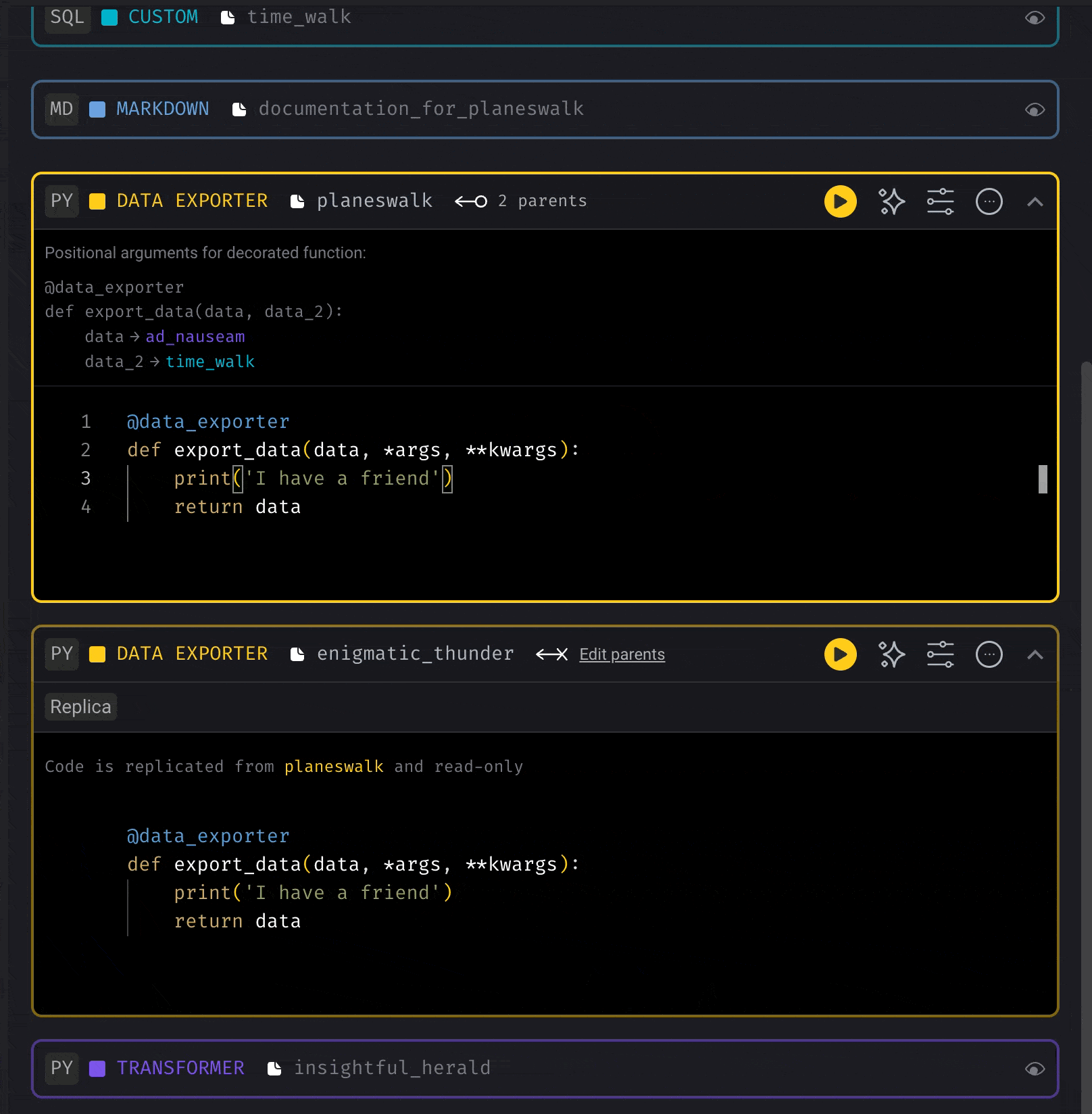
To reuse a block within the same pipeline (create a copy):- Click the triple dot icon in the top right corner of the block you want to replicate
- Select “Replicate block” from the dropdown menu
- Name the new replica block (optional)
- Customize the new block as needed for your specific use case
- Connect the blocks in your pipeline flow as required
- Similar data sources - Load from different tables with similar structure
- Multiple transformations - Apply similar logic to different data streams
- Parallel processing - Process the same data with different parameters
- Testing variations - Compare different approaches side by side
Other ways to reuse code
Create utility files and import in blocks
For shared functions and logic that don’t need to be full blocks:- Create a utility file in your project (e.g.,
default_repo/utils/data_processing.py) - Write reusable functions in the utility file
- Import the functions in your blocks using standard Python imports
Use block templates
Create reusable block templates for common patterns:- Navigate to Templates - Click “Templates” in the left navigation menu
- Create new template - Click “New block template” button
- Define template properties - Set template UUID, block type, and language
- Edit template content - Write the template code with placeholders
- Save template - Click “Save template” to create the template
Reusing blocks across projects
Block templates across projects (Mage Pro)
Mage Pro feature: Mage Pro supports configuring a central template library that shares templates across projects, allowing you to create and share reusable block templates across multiple projects in your organization.
- Navigate to Templates - Click “Templates” in the left navigation menu
- Create new template - Click “New block template” button
- Define template properties - Set template UUID, block type, and language
- Edit template content - Write the template code with placeholders
- Save template - Click “Save template” to create the template
- Open pipeline editor - Navigate to the pipeline where you want to add the block
- Add new block - Click the ”+” button to add a new block
- Browse templates - Select “Browse templates” from the block creation options
- Select template - Choose the template you want to use from the available templates
- Name the block - Enter a specific name for your new block instance
Cross-project block sharing
For organizations with multiple projects:- Export blocks by downloading the block file from the source project
- Import blocks by uploading the block file in the file browser of the target project
- Maintain version control across project boundaries
- Share common utilities and configurations
- Document dependencies - Clearly list required packages and configurations
- Use relative imports - Make blocks portable across different project structures
- Test thoroughly - Ensure blocks work in different project environments
Best practices for block reuse
Design reusable blocks
- Make blocks generic - Avoid hardcoded values, use runtime variables instead
- Clear naming - Use descriptive names that indicate the block’s purpose
- Documentation - Add comments explaining what the block does and its inputs/outputs
- Error handling - Include proper error handling for different use cases
Runtime variables for flexibility
Use runtime variables to make blocks adaptable across different pipelines:Block dependencies
When reusing blocks, consider their dependencies:- Data loaders - Ensure data sources are accessible from all pipelines
- Transformers - Make sure input data format is consistent
- Exporters - Verify output destinations are appropriate for each pipeline
Managing shared blocks
Viewing shared block usage
- Click on a shared block in any pipeline
- Look for the sharing indicator (
<> X pipelines) - Click the indicator to see which pipelines are using the block
- Review the usage to understand the block’s impact
Updating shared blocks
When you modify a shared block:- Changes apply everywhere - All pipelines using the block will be affected
- Test thoroughly - Ensure changes work for all use cases
- Communicate changes - Notify team members about significant modifications
- Version control - Use Git to track changes and enable rollbacks if needed
Detaching blocks when needed
If you need to customize a shared block for a specific pipeline:- Use the detach feature - See Detaching blocks guide
- Create a copy - This creates an independent version
- Customize freely - Make changes without affecting other pipelines
Common use cases
Data loading blocks
Reuse data loading logic across multiple pipelines:Transformation blocks
Share common data transformations:Export blocks
Reuse export logic for different destinations:Related documentation
- Block design overview - Understanding block architecture
- Detaching blocks - Separating shared blocks
- User-defined templates - Creating custom block and pipeline templates
- Runtime variables - Making blocks flexible