Overview
In this tutorial, we’ll create a data pipeline with the following steps:1
Load data from an online endpoint
We’ll use a Python block to load data from an online endpoint— a CSV file containing restaurant user transactions. We’ll also run a test to make sure the data is clean.
2
Clean column names and add a new column
We’ll use a Python block to transform the data by cleaning the columns and creating a new column,
number of meals, that counts the number of meals for each user.3
Write the transformed data to a local DuckDB database
Finally, we’ll write the transformed data to a local DuckDB table.
Quickstart
Want to dive in? Simply run the following command to clone a pre-built repo:https://localhost:6789 in your browser to see the pipeline in action!
Tutorial
1️⃣ Create a pipeline
1️⃣ Create a pipeline
Open the pipelines list page (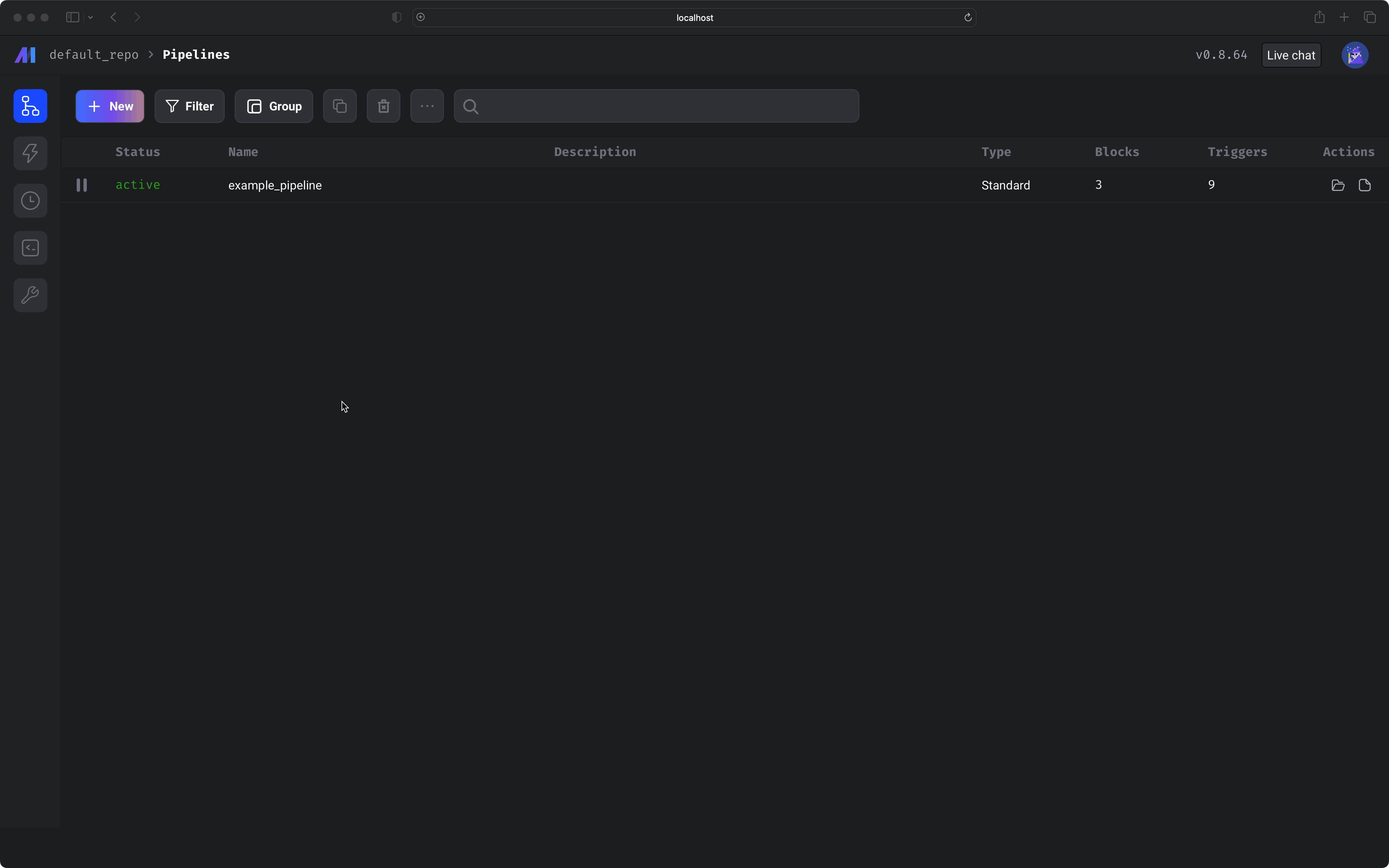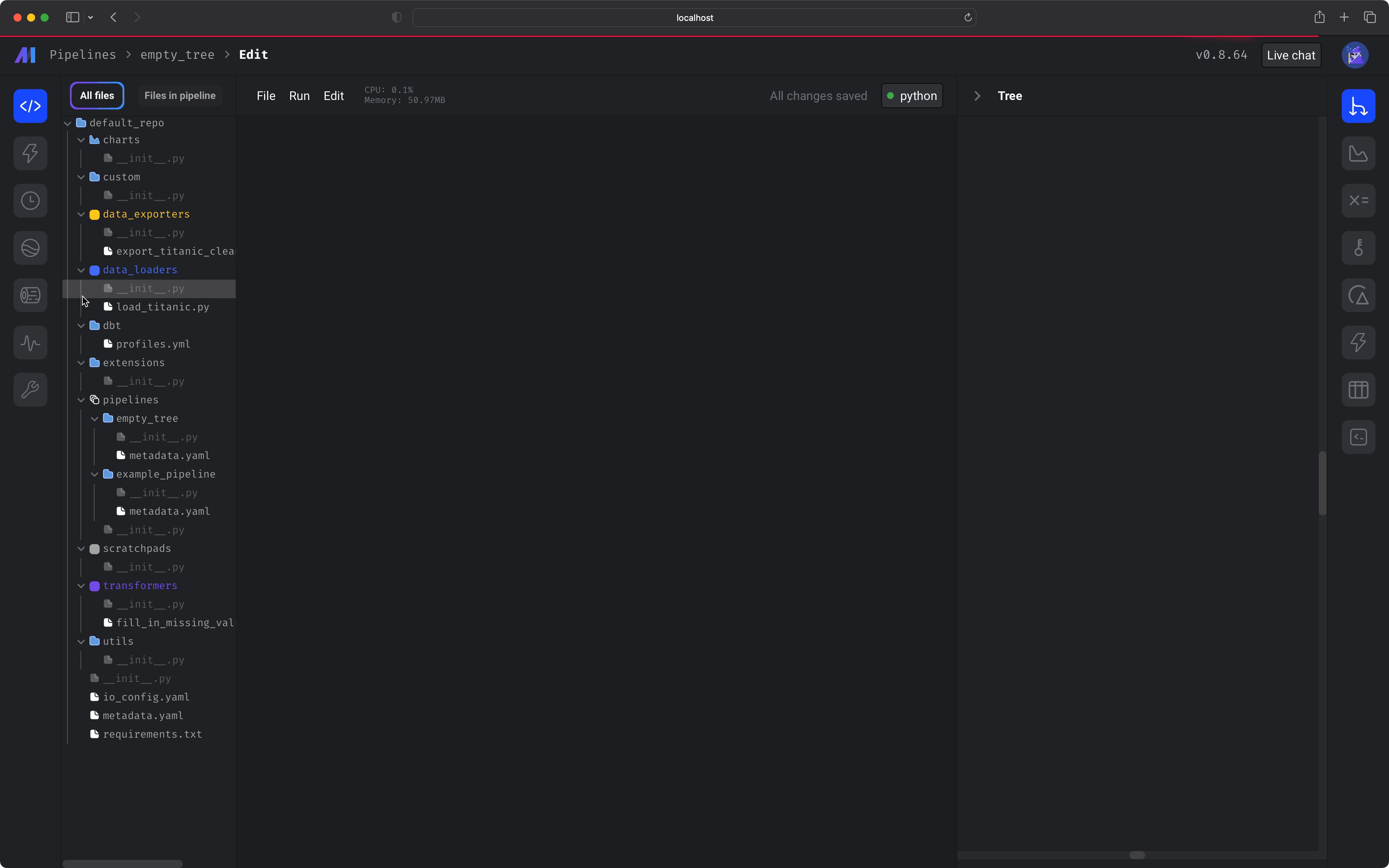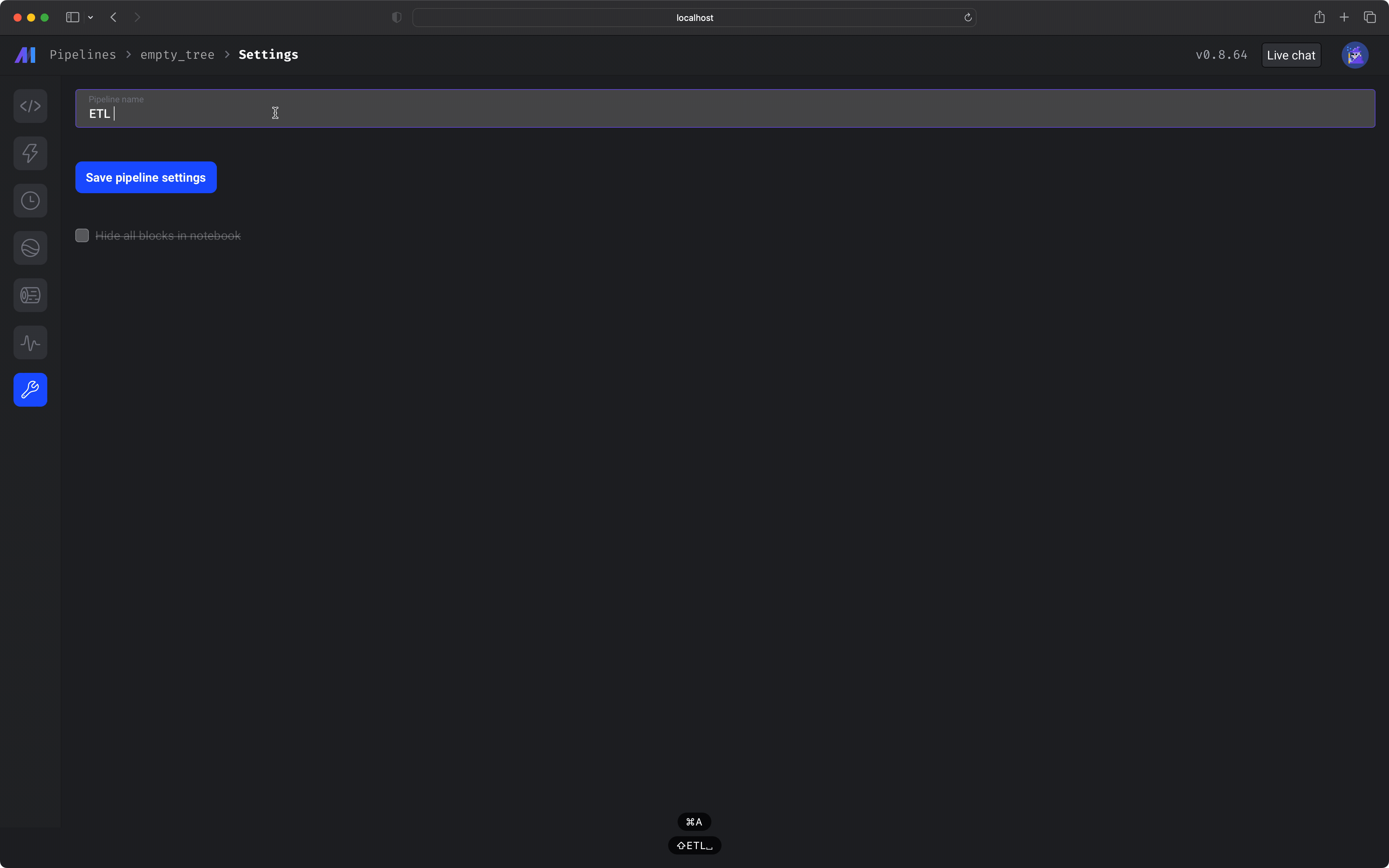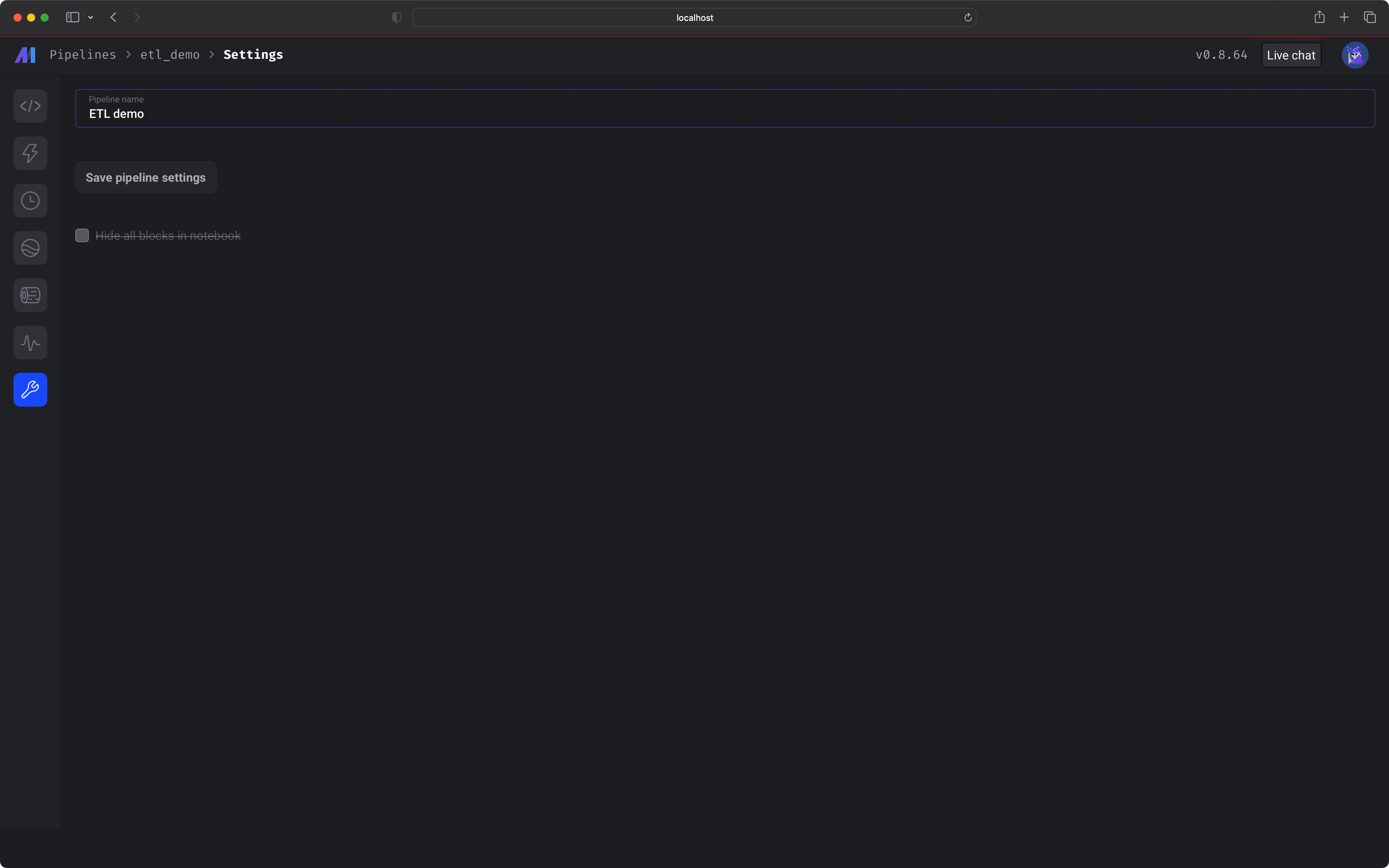
/pipelines). This is the default page when navigating to Mage in your web browser. If you have Mage running, just click here.In the top left corner, select the button labeled + New, then select the option labeled Standard (batch) to create a new pipeline.In the left vertical navigation, click the last link labeled Pipeline settings. Change the pipeline’s name to ETL demo. Click the button labeled Save pipeline settings.2️⃣ Load data from an API
2️⃣ Load data from an API
In the left vertical navigation, click the 1st link labeled Edit pipeline. Click the button labeled + Data loader then hover over Python, and click the option labeled API.A dialog menu will appear. Change the block name to Run the block by clicking the play icon button in the top right corner of the data loader block or one of the following keyboard shortcuts: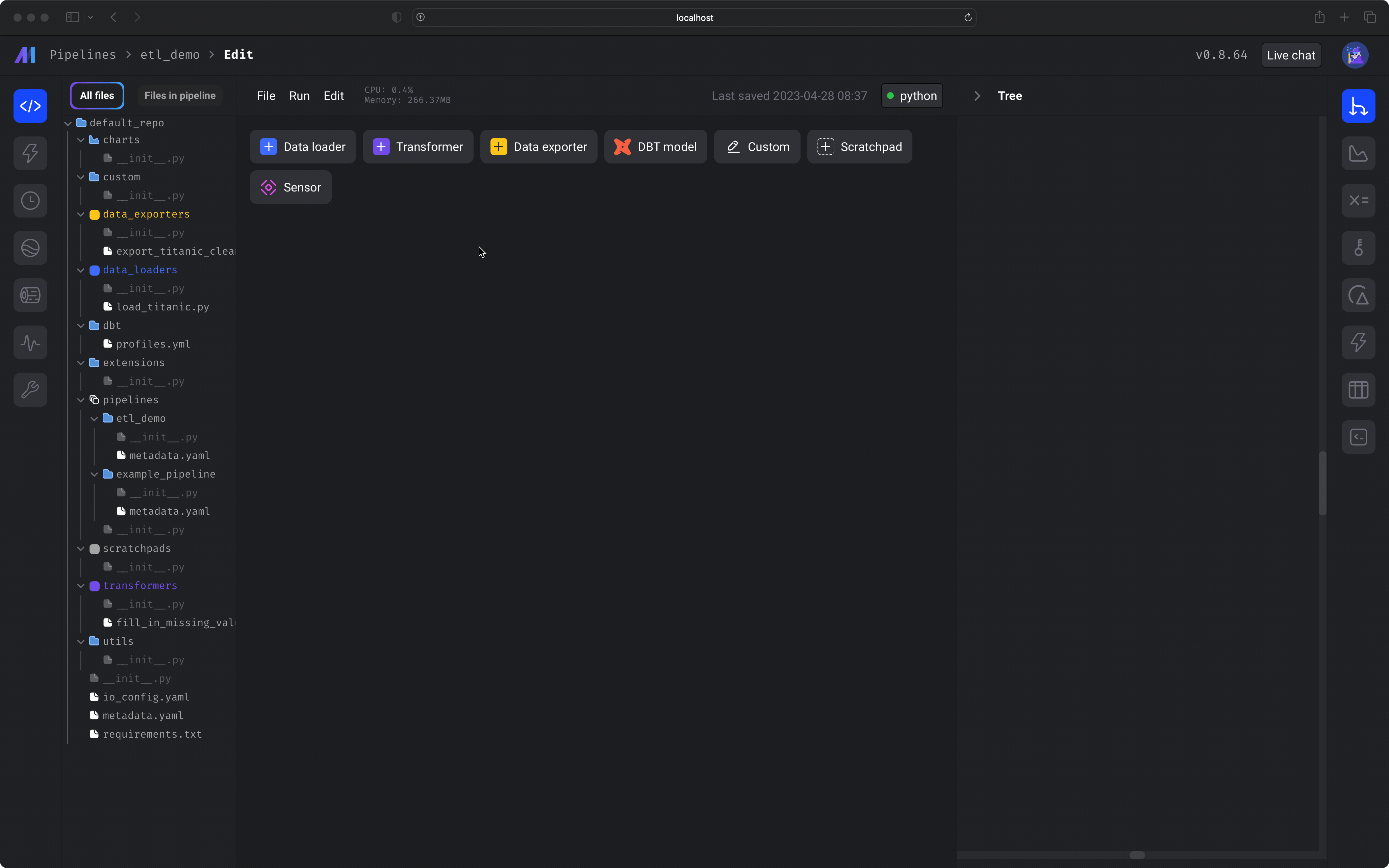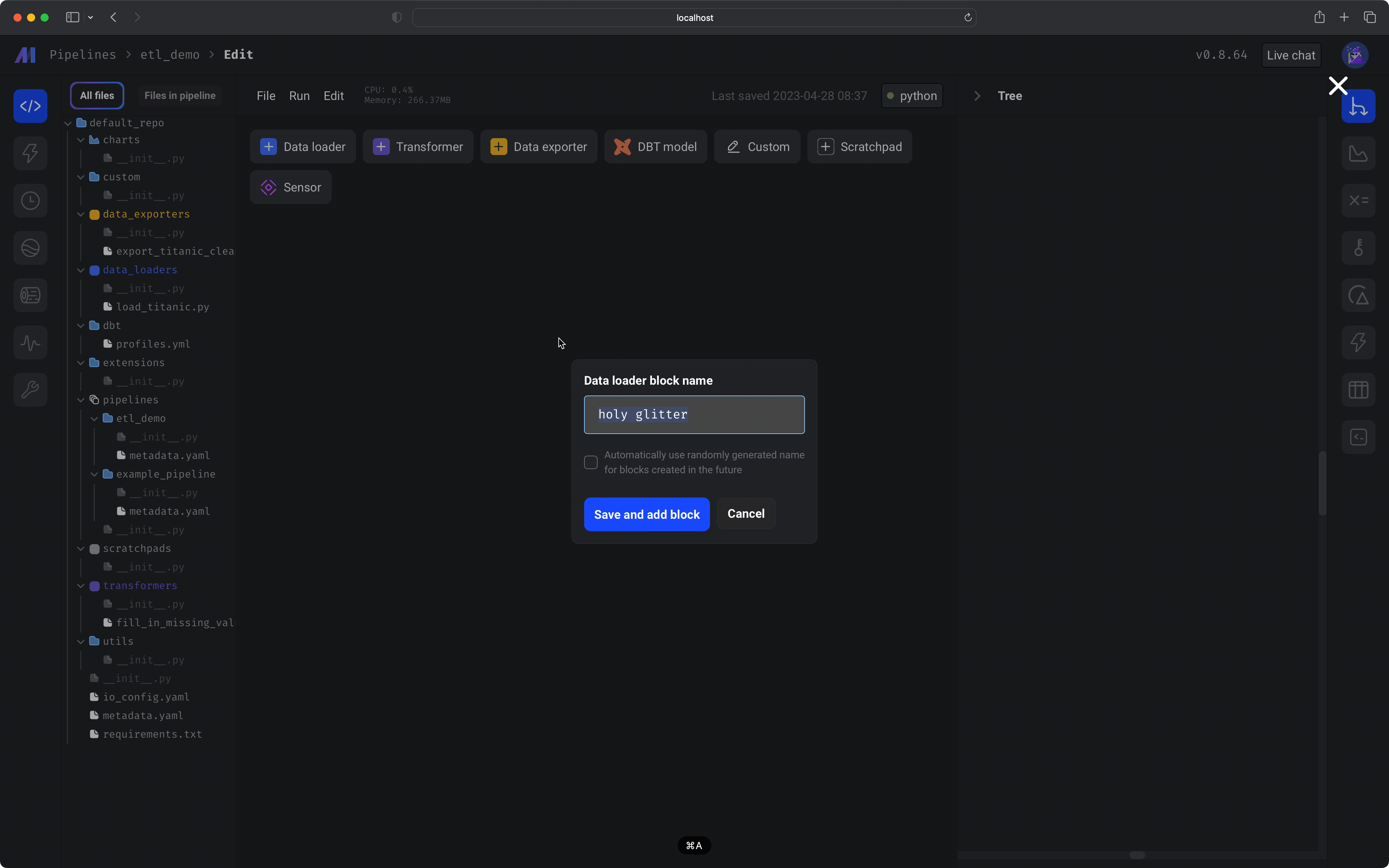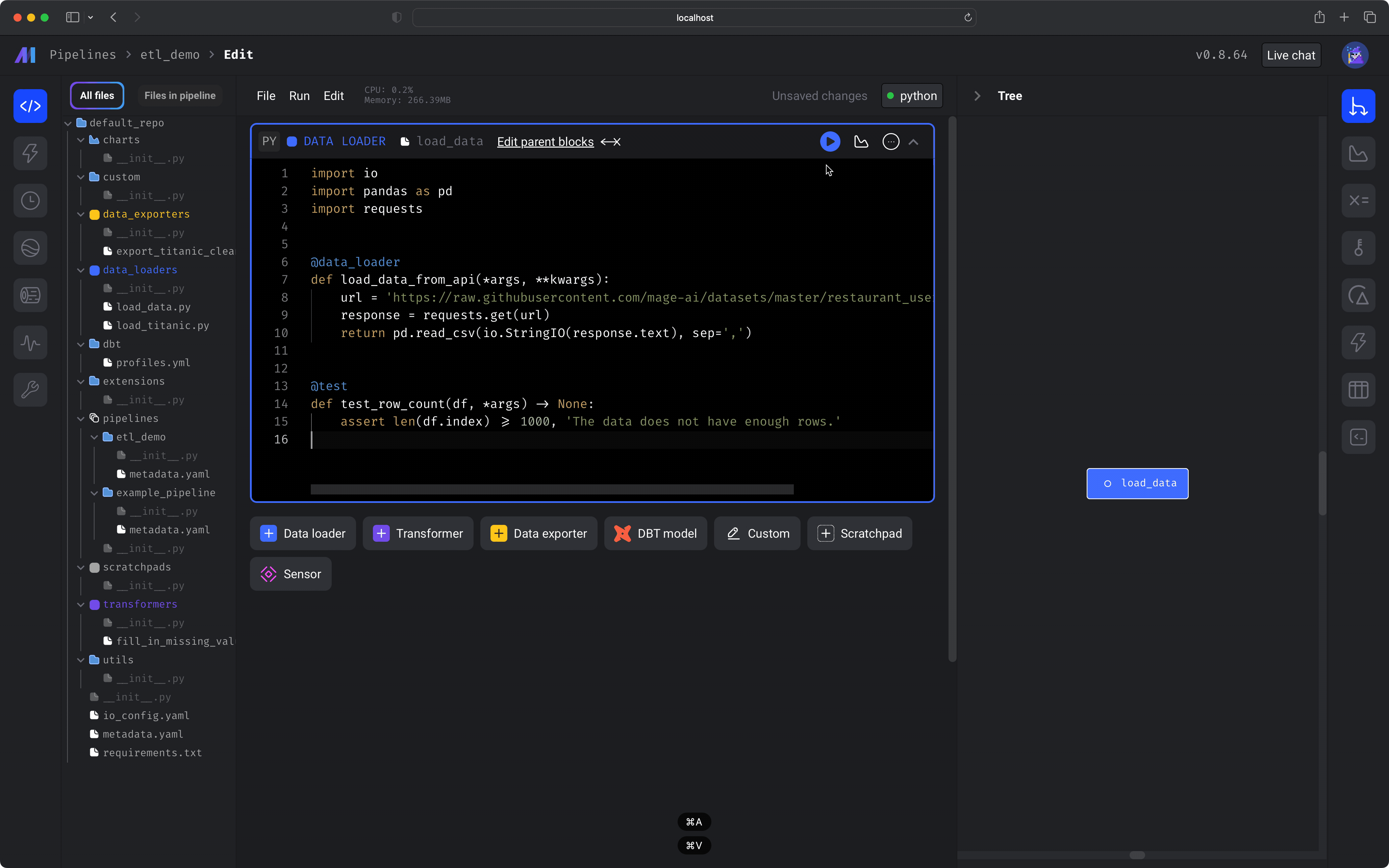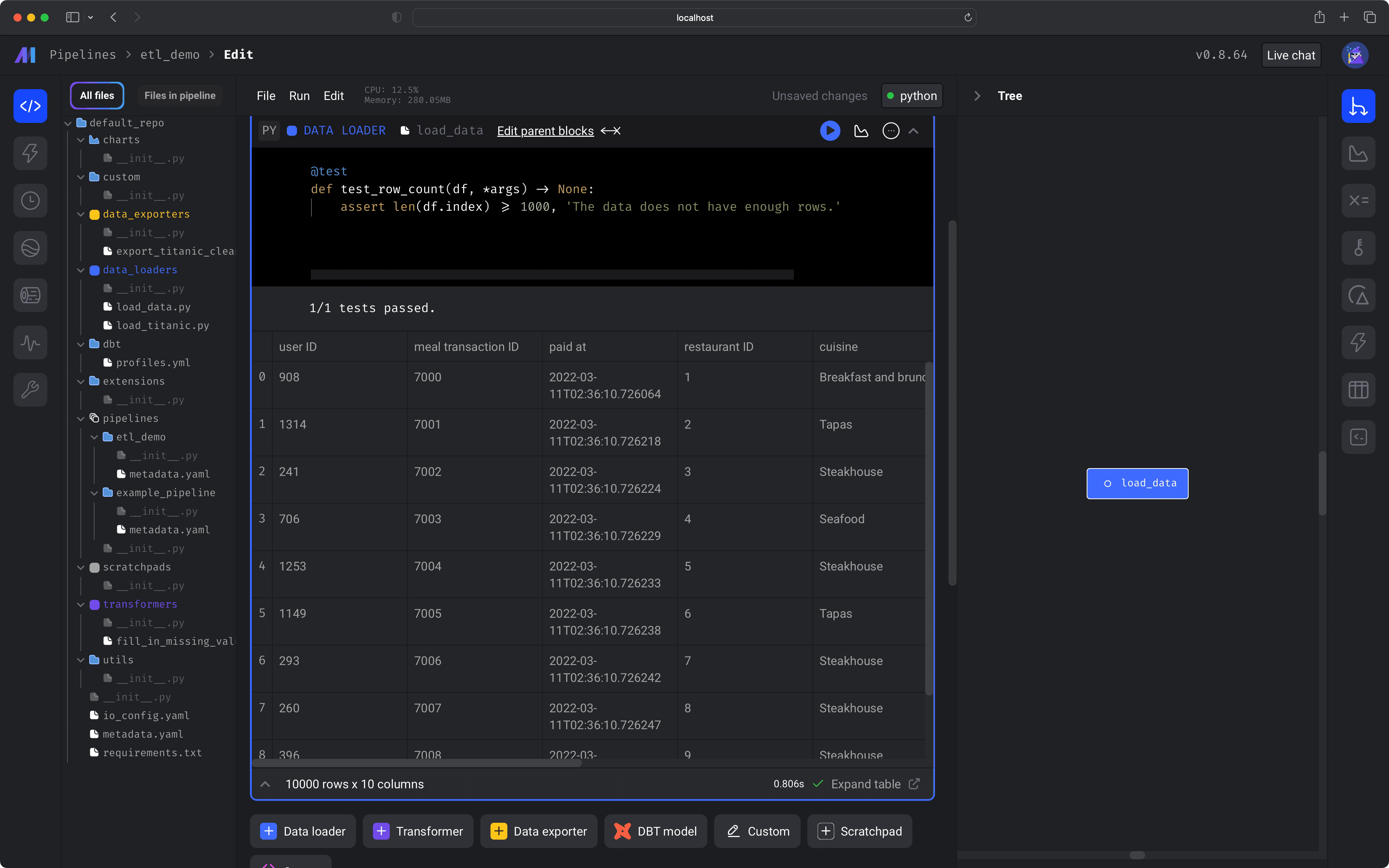
load data. Click the button labeled Save and add block. Paste the following code in the data loader block:⌘ + EnterControl + EnterShift + Enter
3️⃣ Transform data
3️⃣ Transform data
Let’s transform the data in 2 ways:Run the block by clicking the play icon button in the top right corner of the data loader block or press 1 of the following keyboard shortcuts: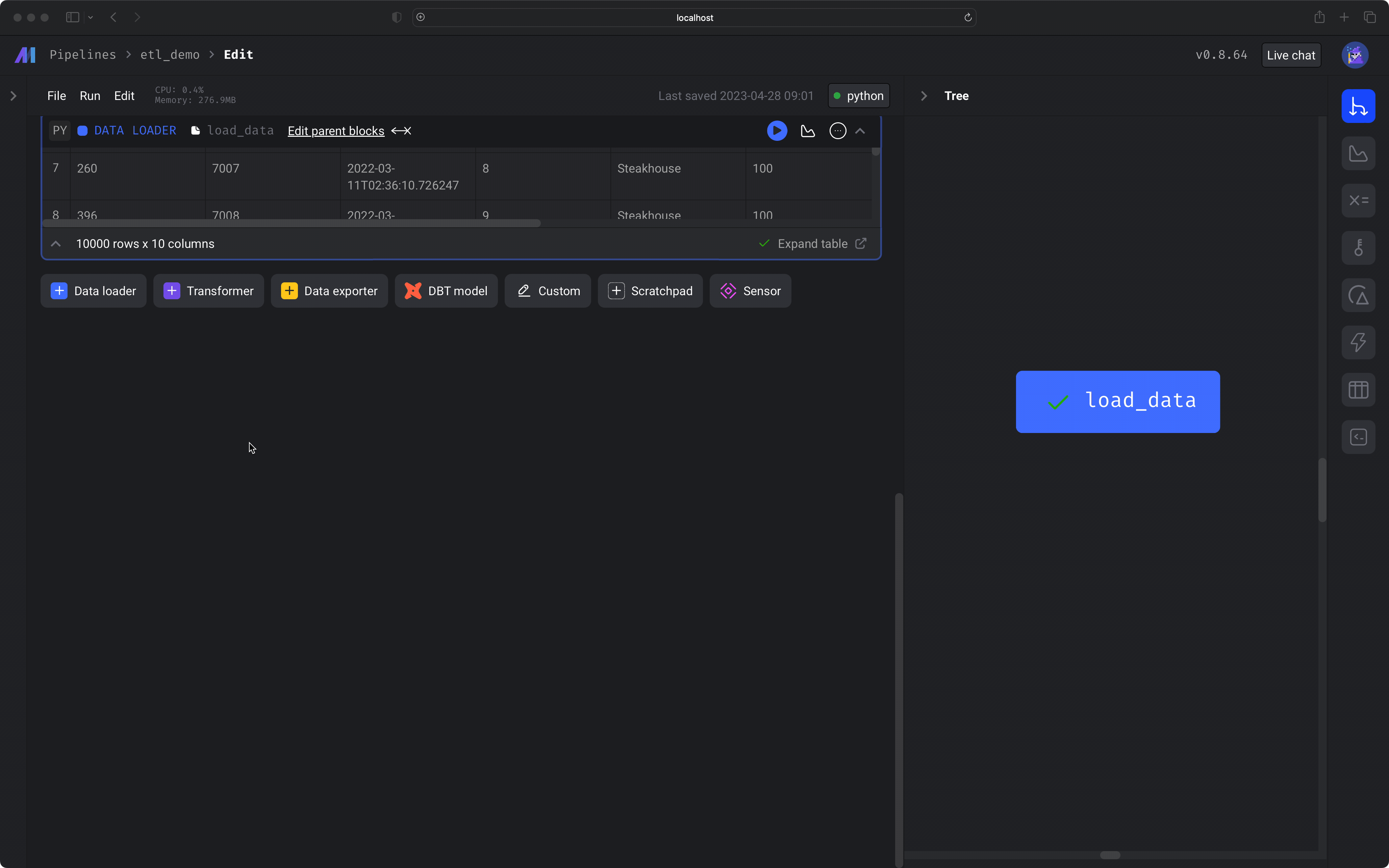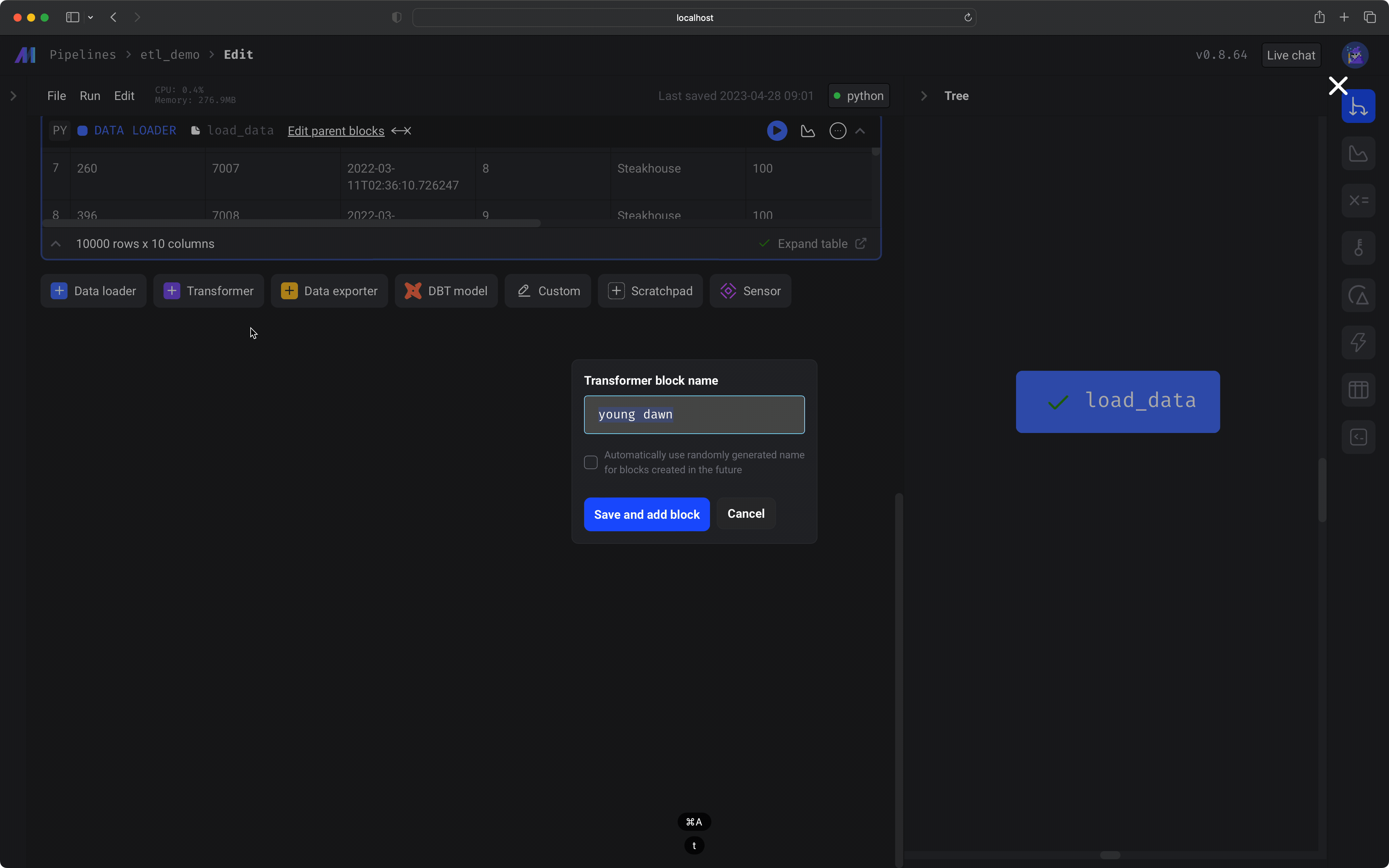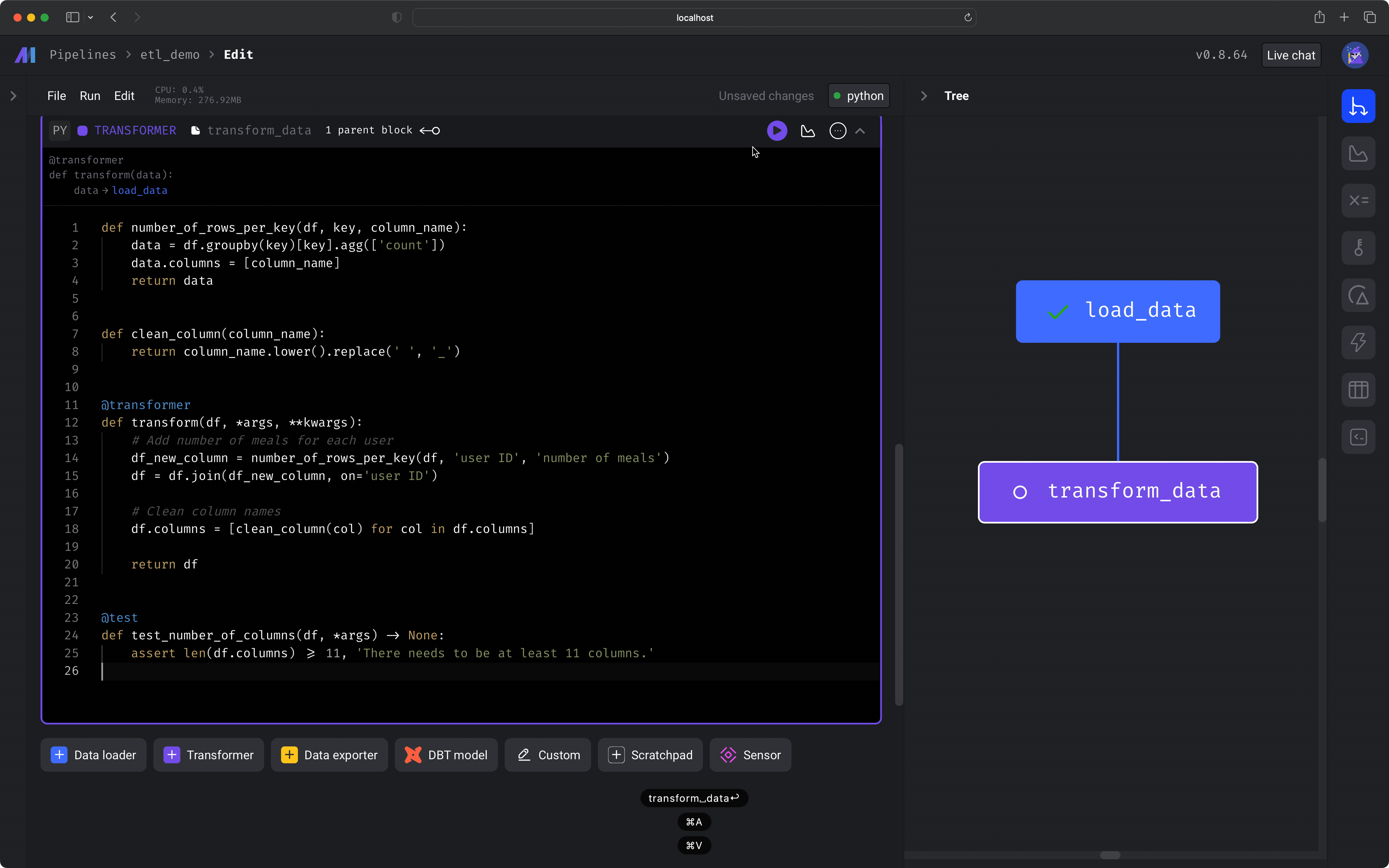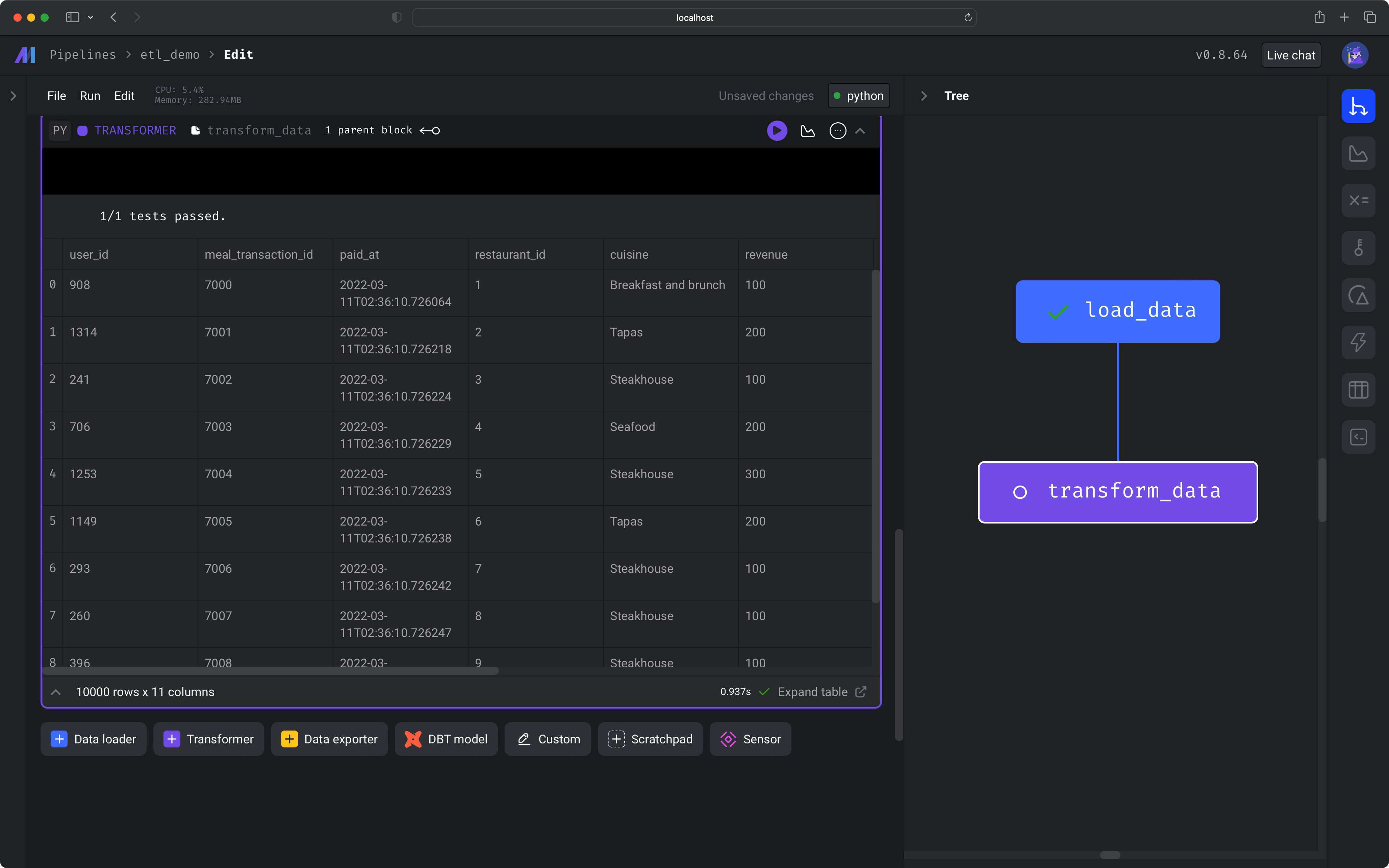
- Add a column that counts the number of meals for each user.
- Clean the column names to properly store in a PostgreSQL database.
⌘ + EnterControl + EnterShift + Enter
4️⃣ Export data to DuckDB
4️⃣ Export data to DuckDB
Let’s export the data to a local DuckDB database! Create a new This will take our data from the previous block and export it to a local DuckDB table— 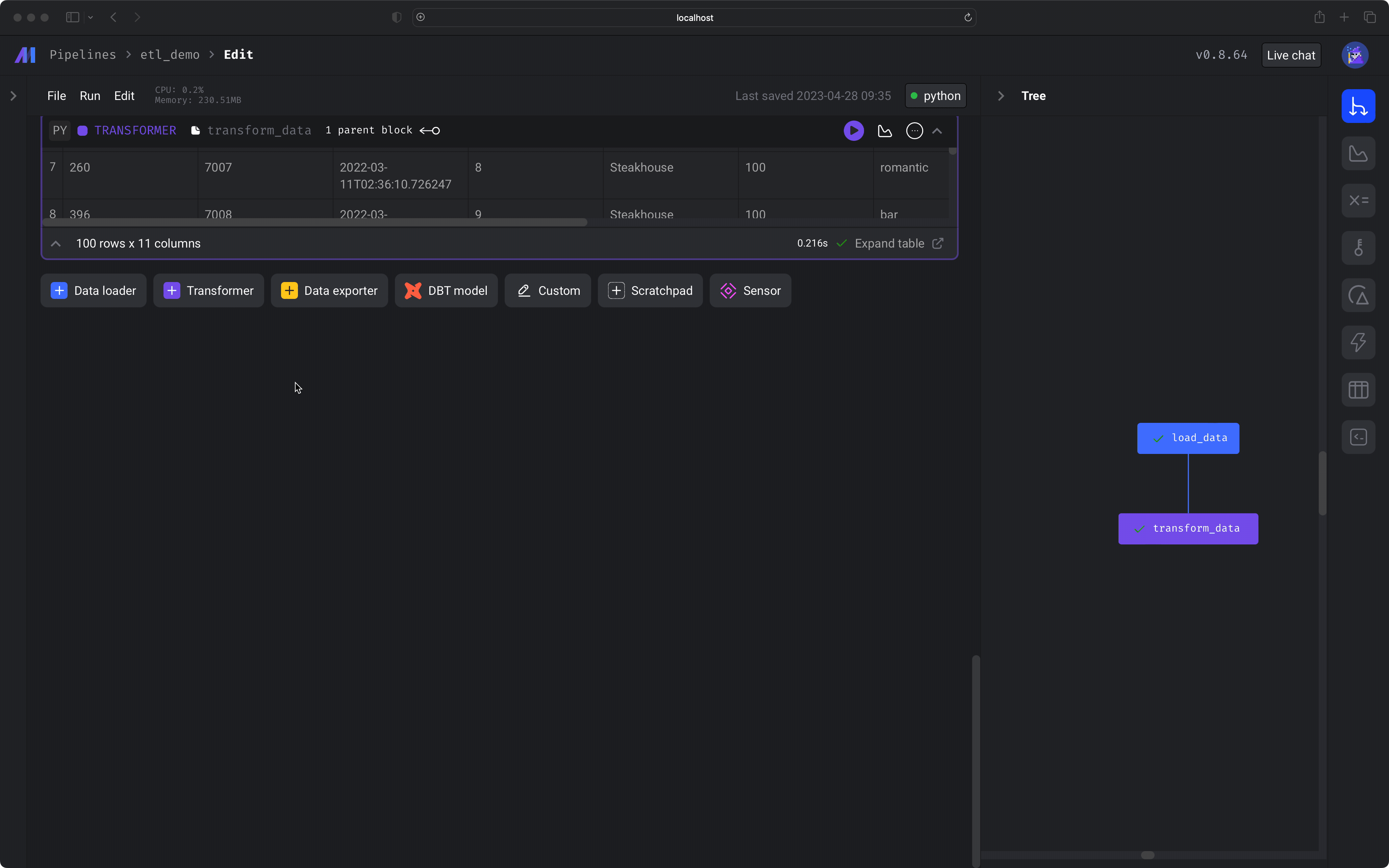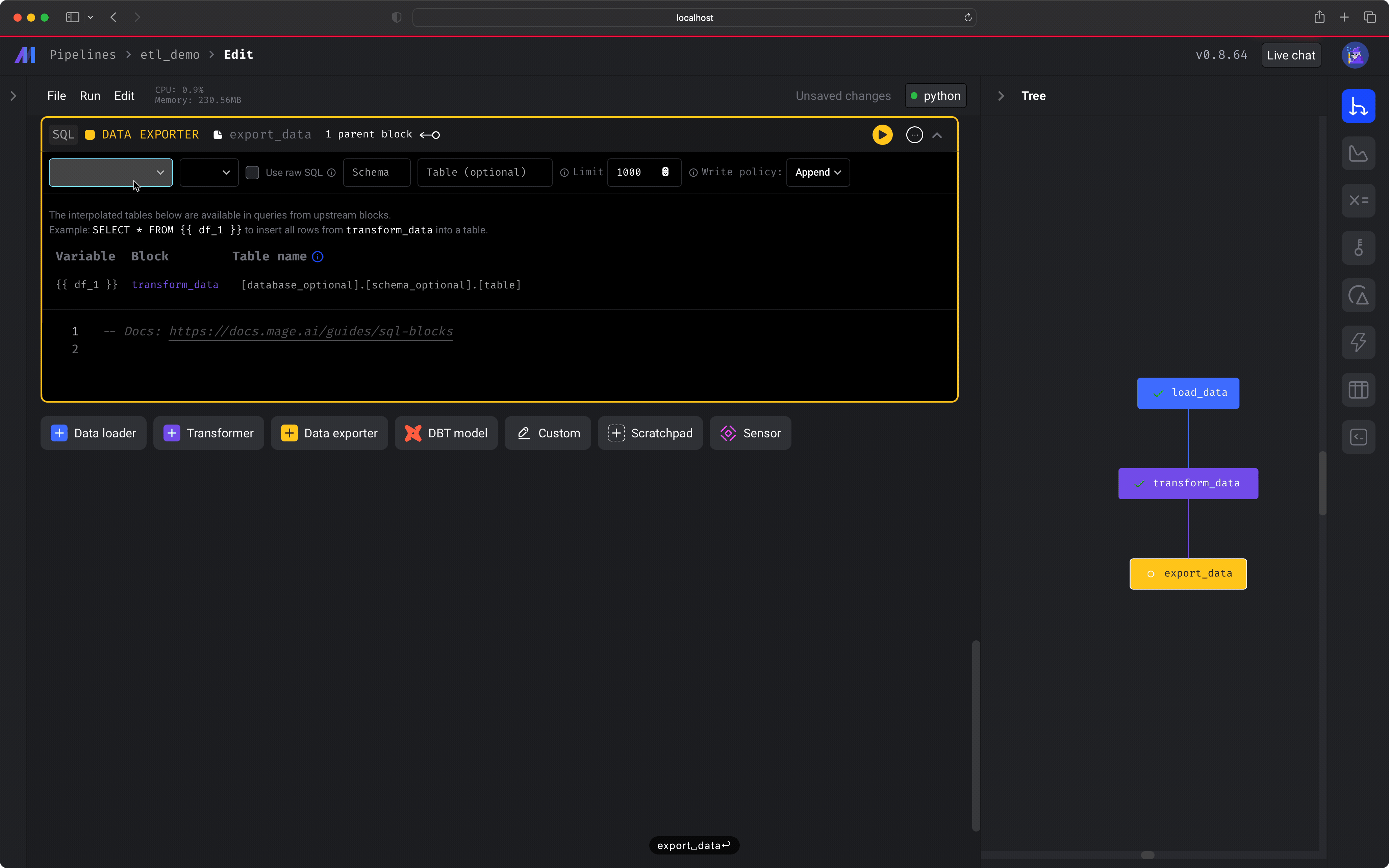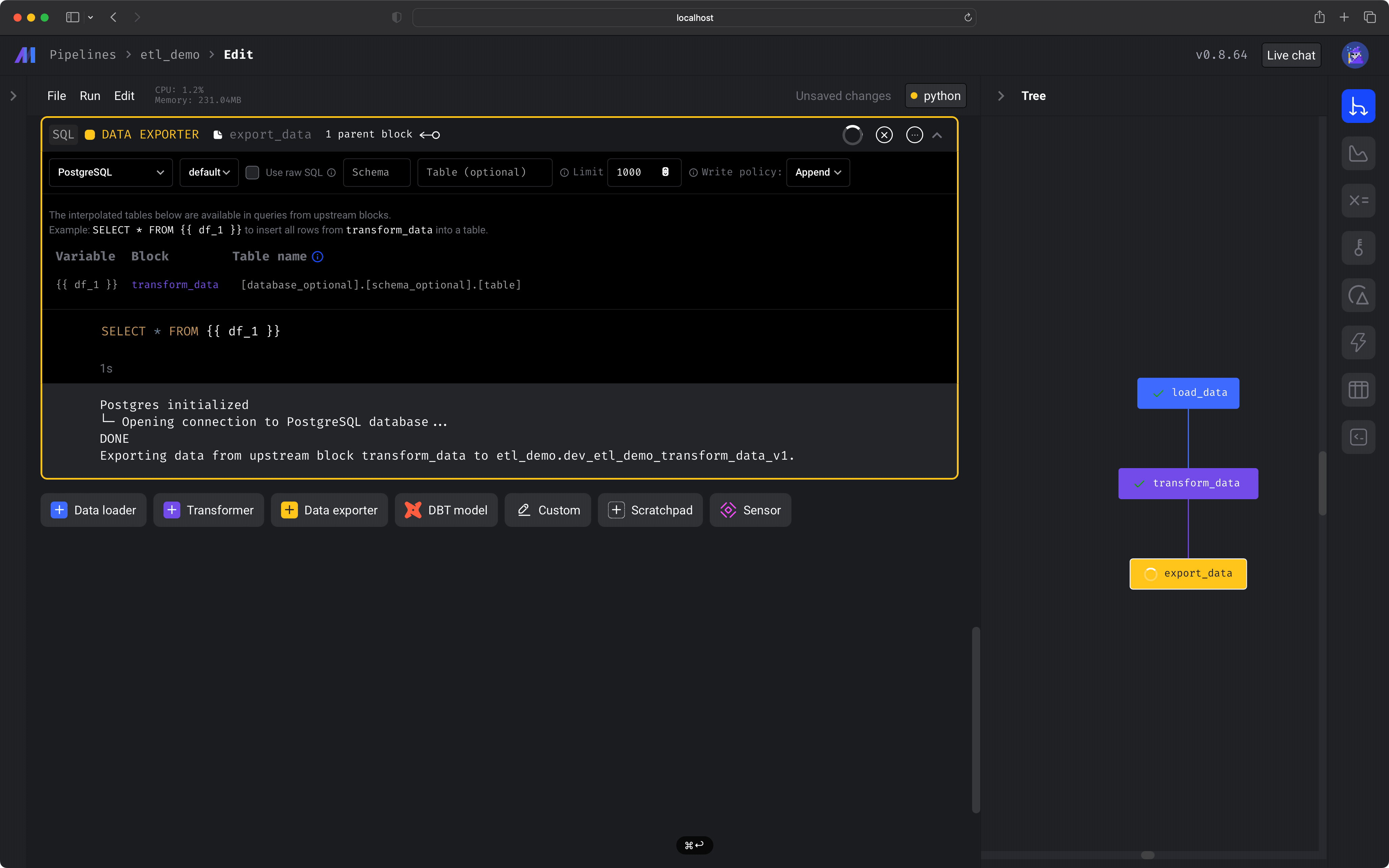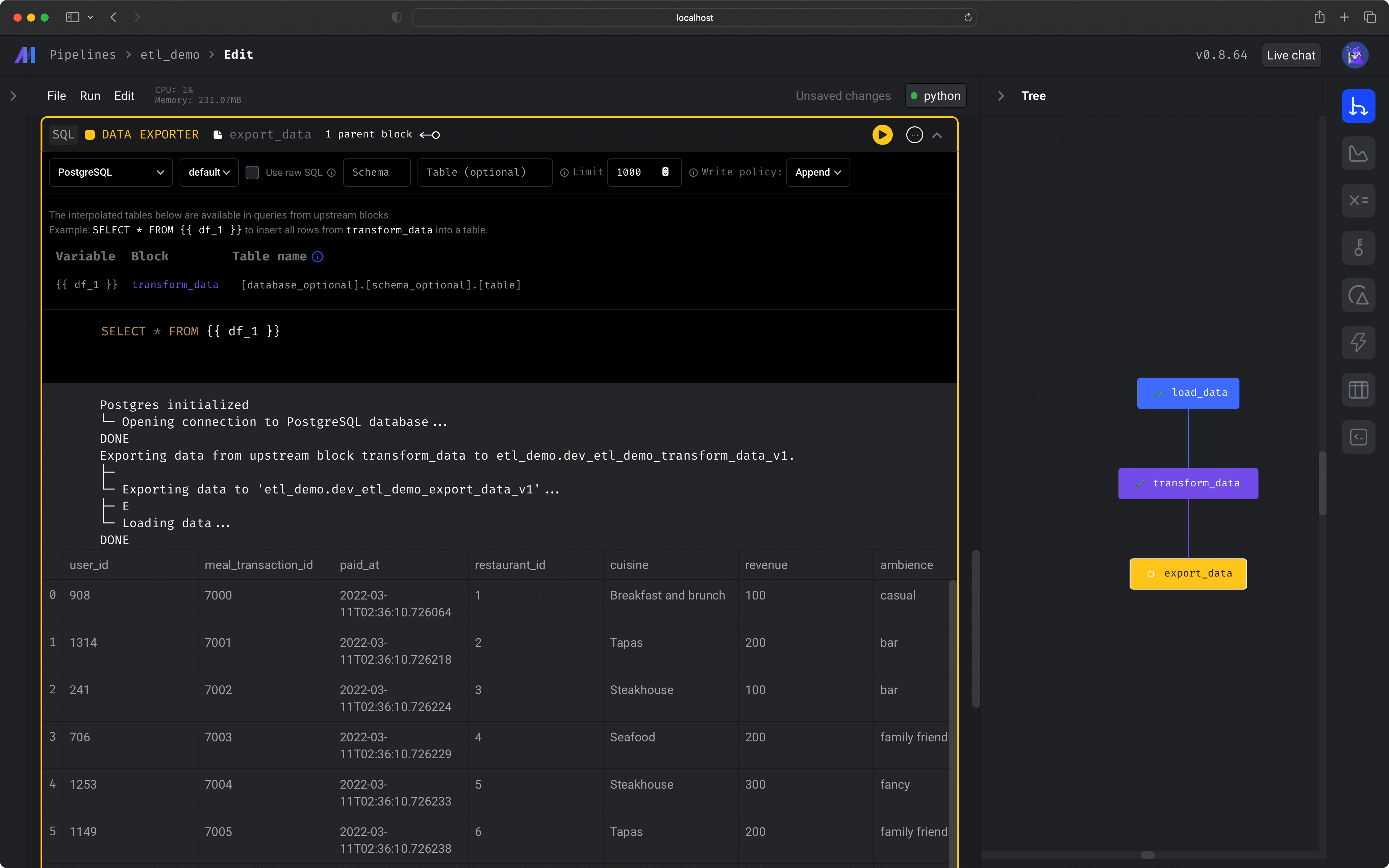 You should also see some logs indicating the export was completed, e.g.
You should also see some logs indicating the export was completed, e.g.
Data Exporter SQL block and change the connection type to be DuckDB.Next, change the Table name to be magic_duck.restaurant_user_transactions and make sure the content of the block is:magic_duck.restaurant_user_transactions! 🎉After you run the block (⌘ + Enter), you’ll see a sample of the data that was exported. If you have more questions or ideas, get real-time help in our live support
Slack channel.
If you have more questions or ideas, get real-time help in our live support
Slack channel.