Setup
If you haven’t setup a project before, check out the setup guide before starting.Pipelines
http://localhost:3000/pipelines
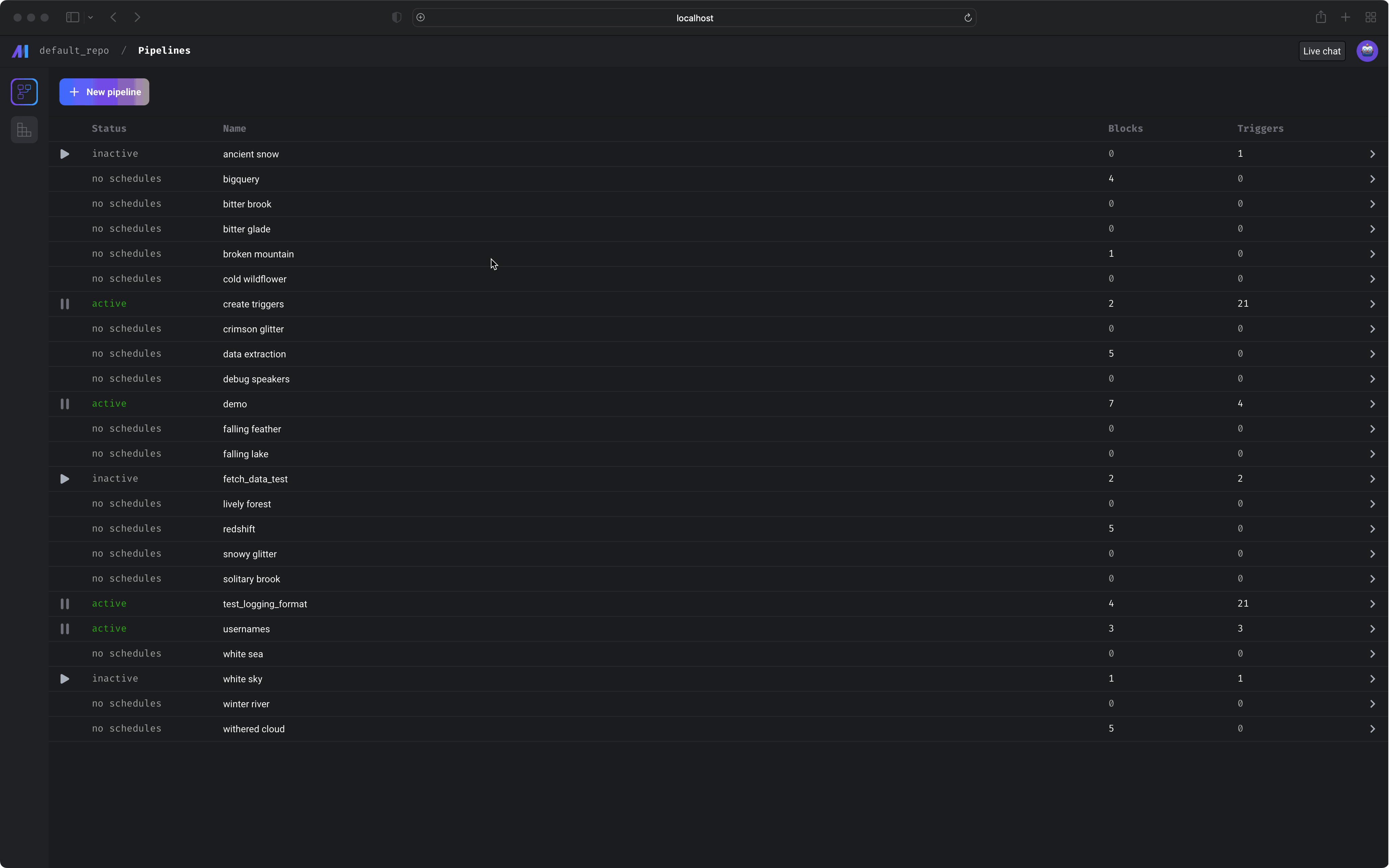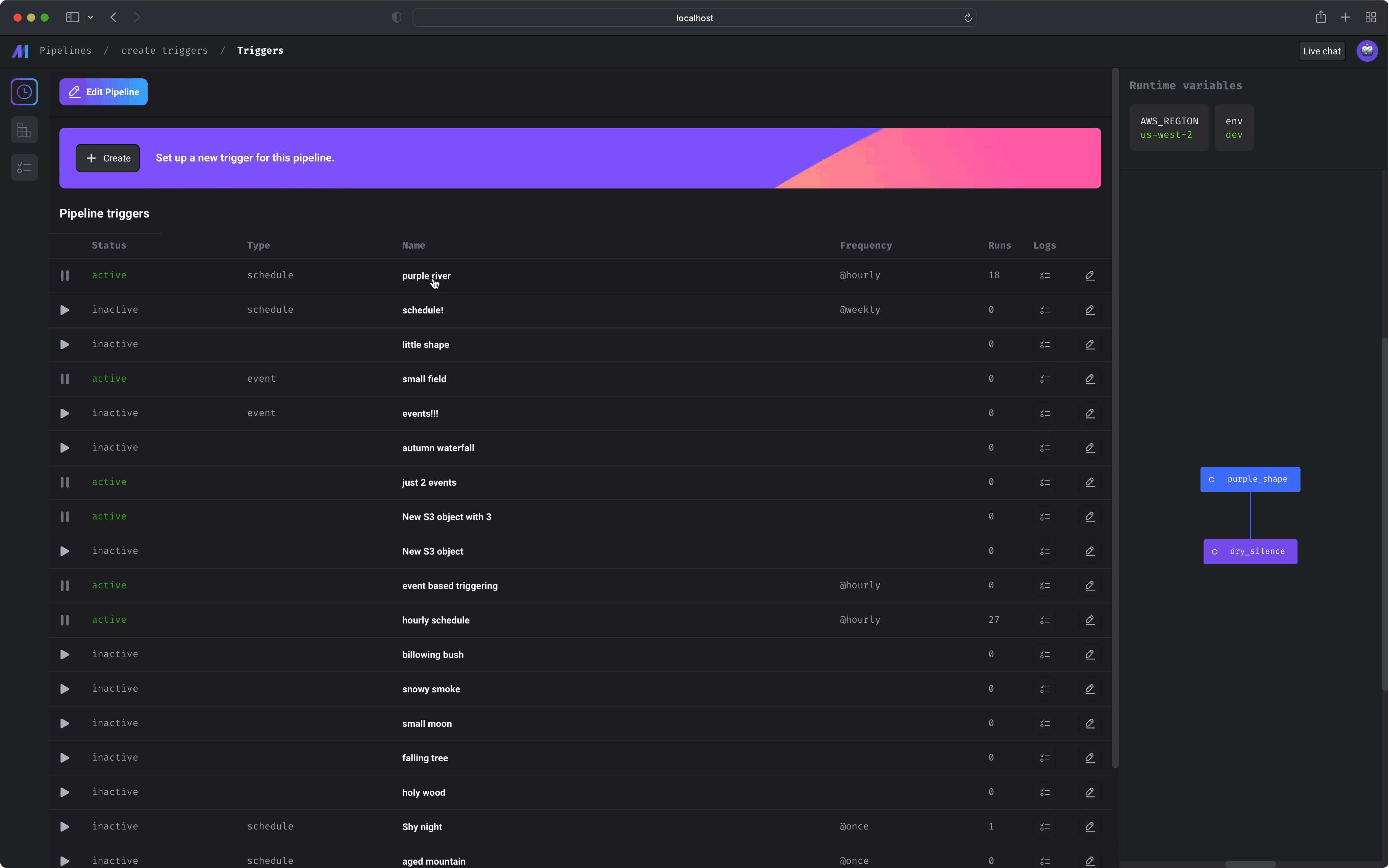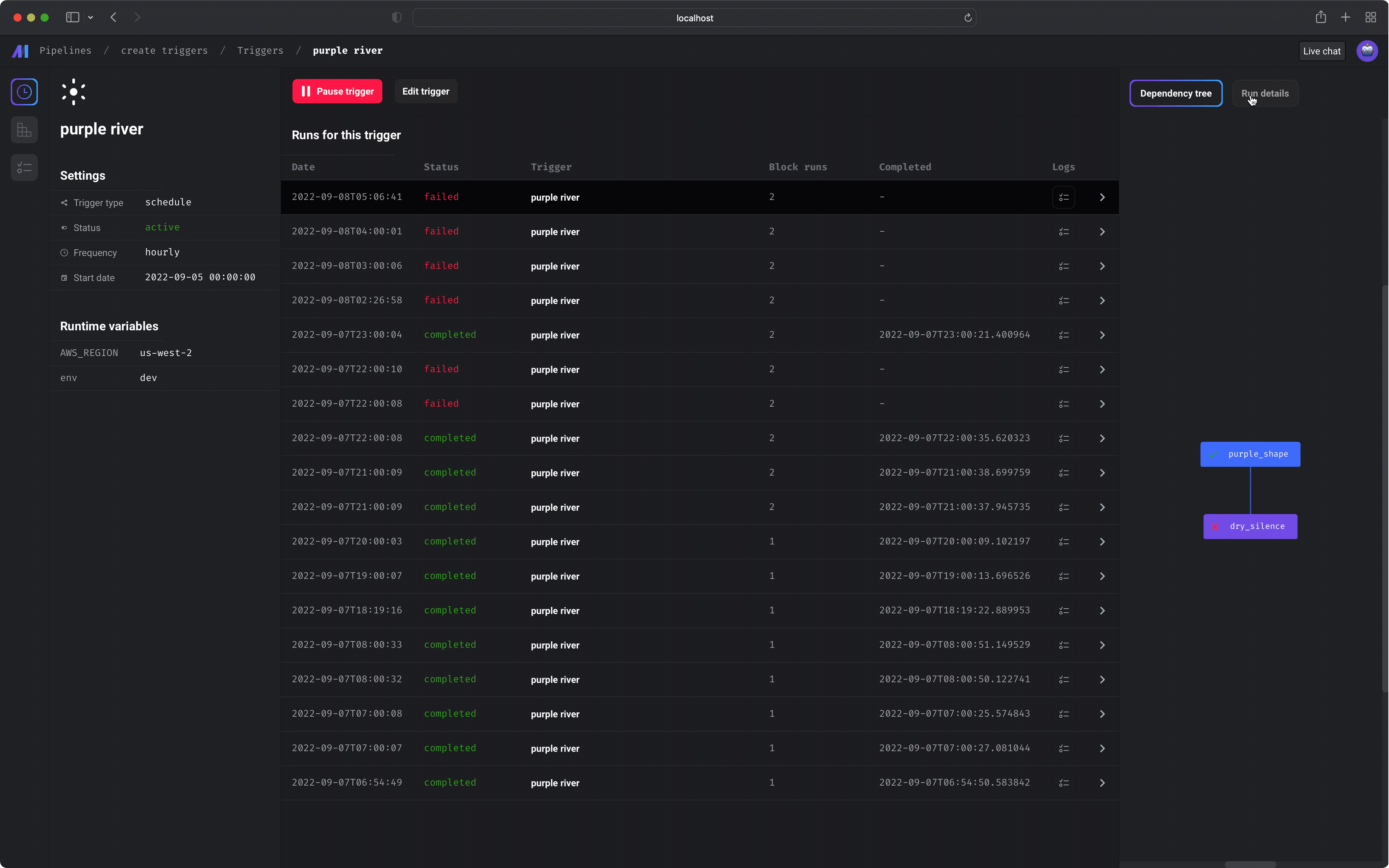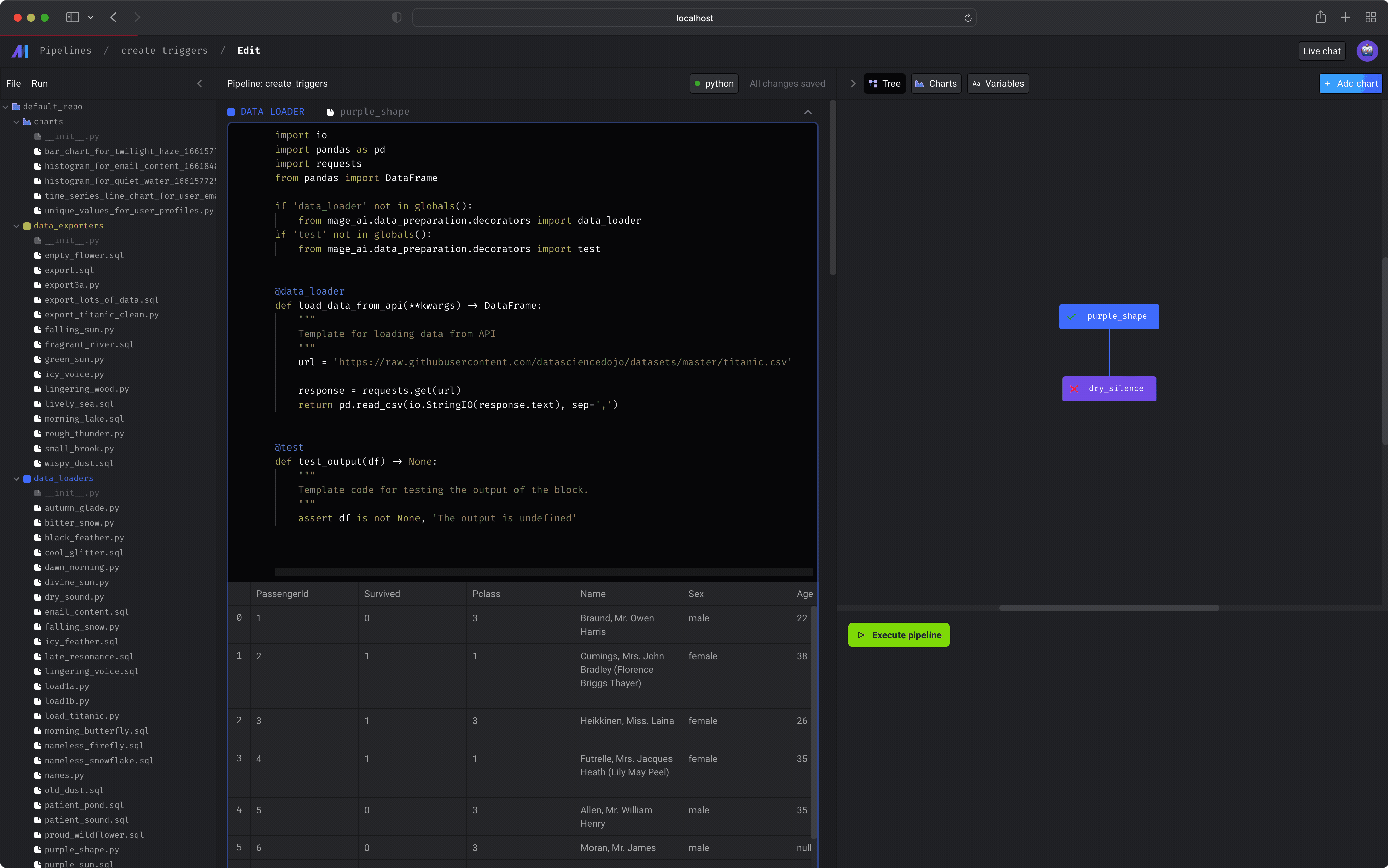
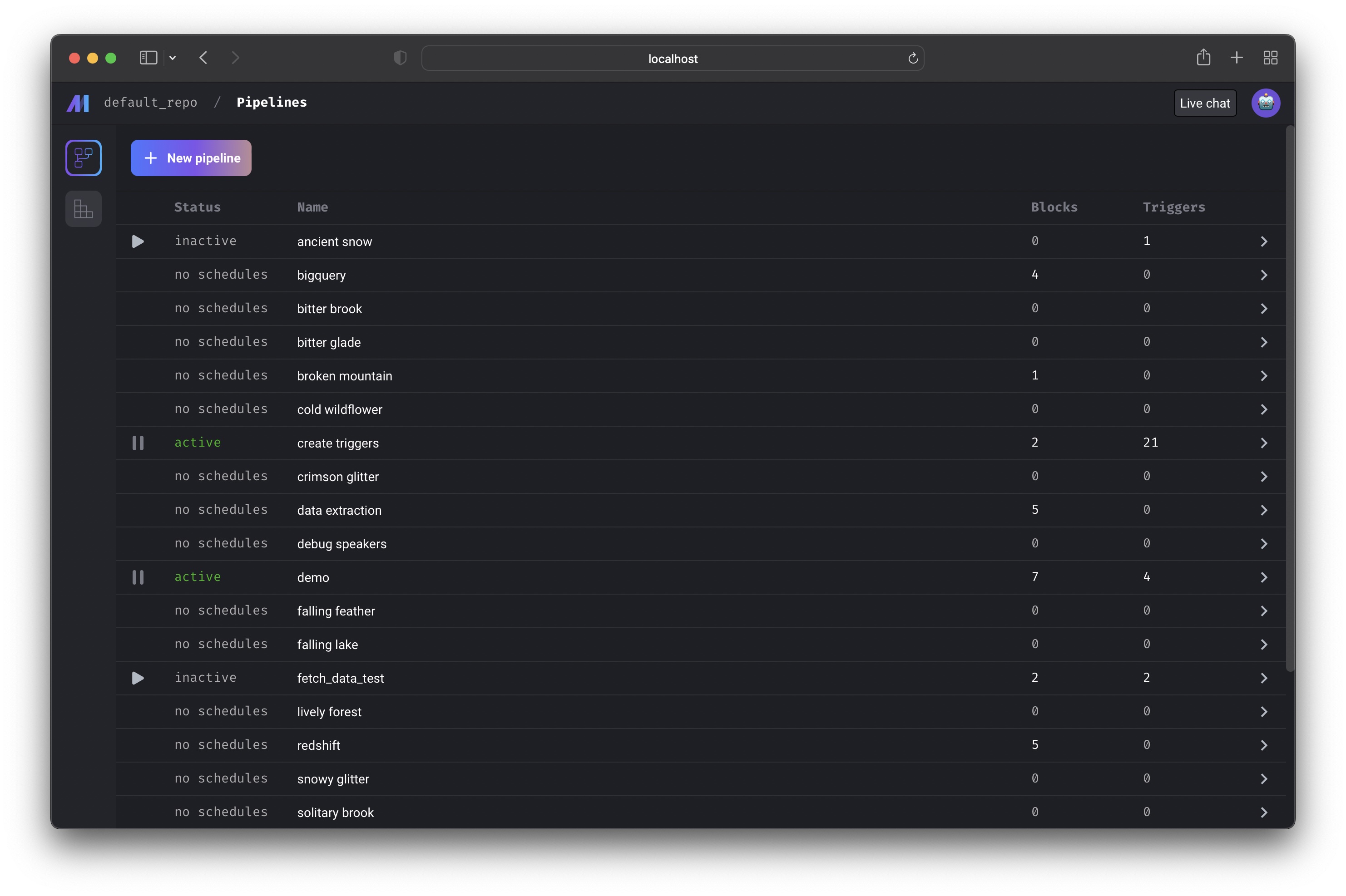
This page will show all the pipelines in your project.
Core abstraction: Pipeline A pipeline contains references to all the blocks of code you want to run, charts for visualizing data, and organizes the dependency between each block of code.
 Learn more about
projects and pipelines here.
From this page, you can also create a new pipeline by clicking the
Learn more about
projects and pipelines here.
From this page, you can also create a new pipeline by clicking the
[+ New pipeline] button.
Creating new pipeline
Creating a new pipeline will take you to the Pipeline edit page; a notebook-like experience for adding blocks, creating dependencies between blocks, testing code, and visualizing data with charts. Learn more about the Notebook for building data pipelinesPipeline runs
http://localhost:3000/pipeline-runs
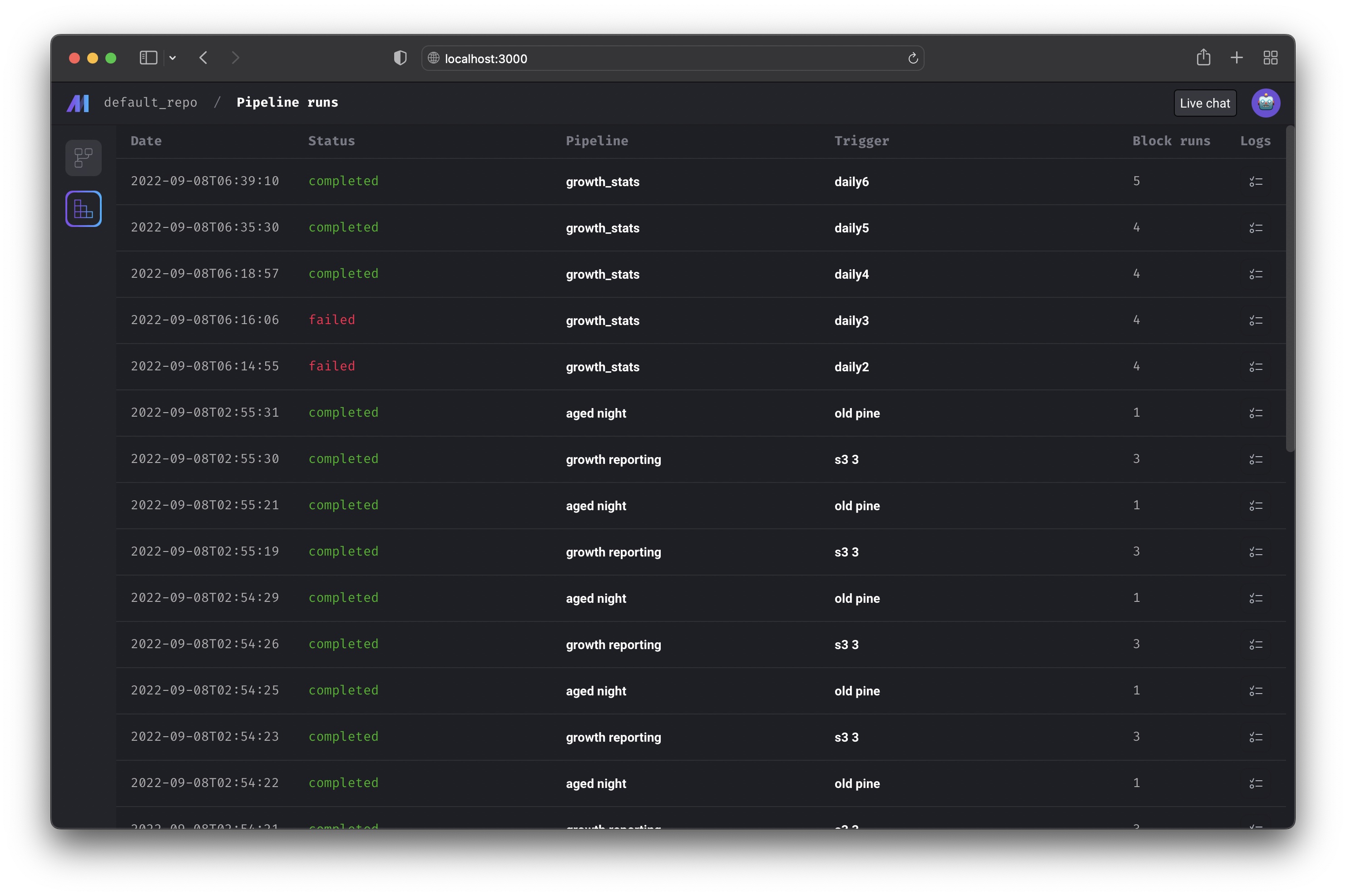
View all the runs for every pipeline in your current project.
Core abstraction: Run A run record stores information about when it was started, its status, when it was completed, any runtime variables used in the execution of the pipeline or block, etc.
Pipeline detail
http://localhost:3000/pipelines/[uuid]
This page contains all the information and history for a single pipeline:
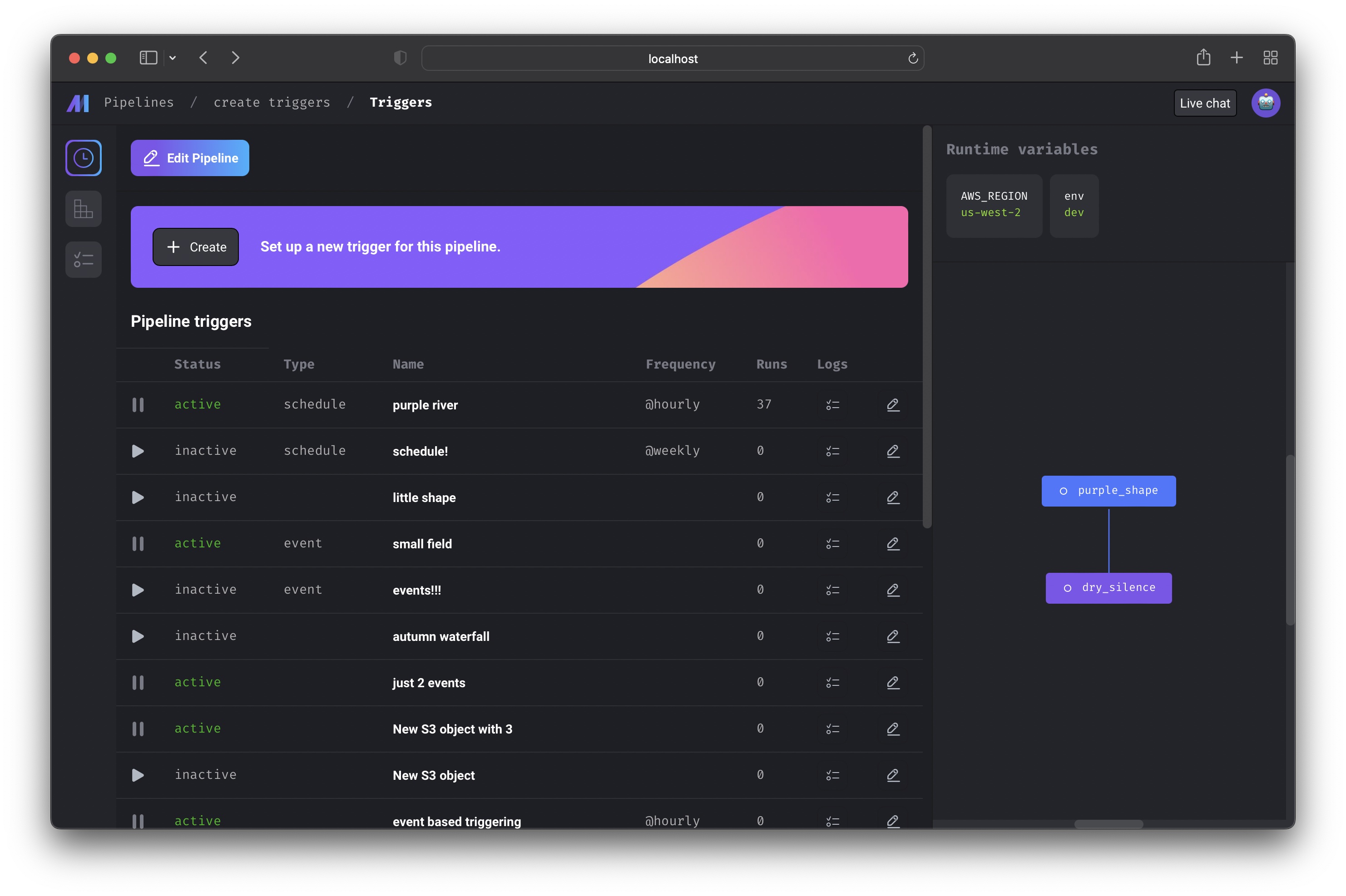
Triggers
http://localhost:3000/pipelines/example_pipeline/triggers
This page shows all the active and inactive triggers for a single pipeline.
Core abstraction: Trigger A trigger is a set of instructions that determine when or how a pipeline should run.
Create trigger
http://localhost:3000/pipelines/[uuid]/triggers/[id]/edit
Create a new trigger for this pipeline by clicking the [+ Create] button
near the top of the page.
You can configure the trigger to run the pipeline on a schedule, when an event
occurs, or when an API is called.
Core abstraction: Schedule A schedule type trigger will instruct the pipeline to run after a start date and on a set interval.
Core abstraction: Event An event type trigger will instruct the pipeline to run whenever a specific event occurs.
Core abstraction: API An API trigger will instruct the pipeline to run whenever a specific API is called.
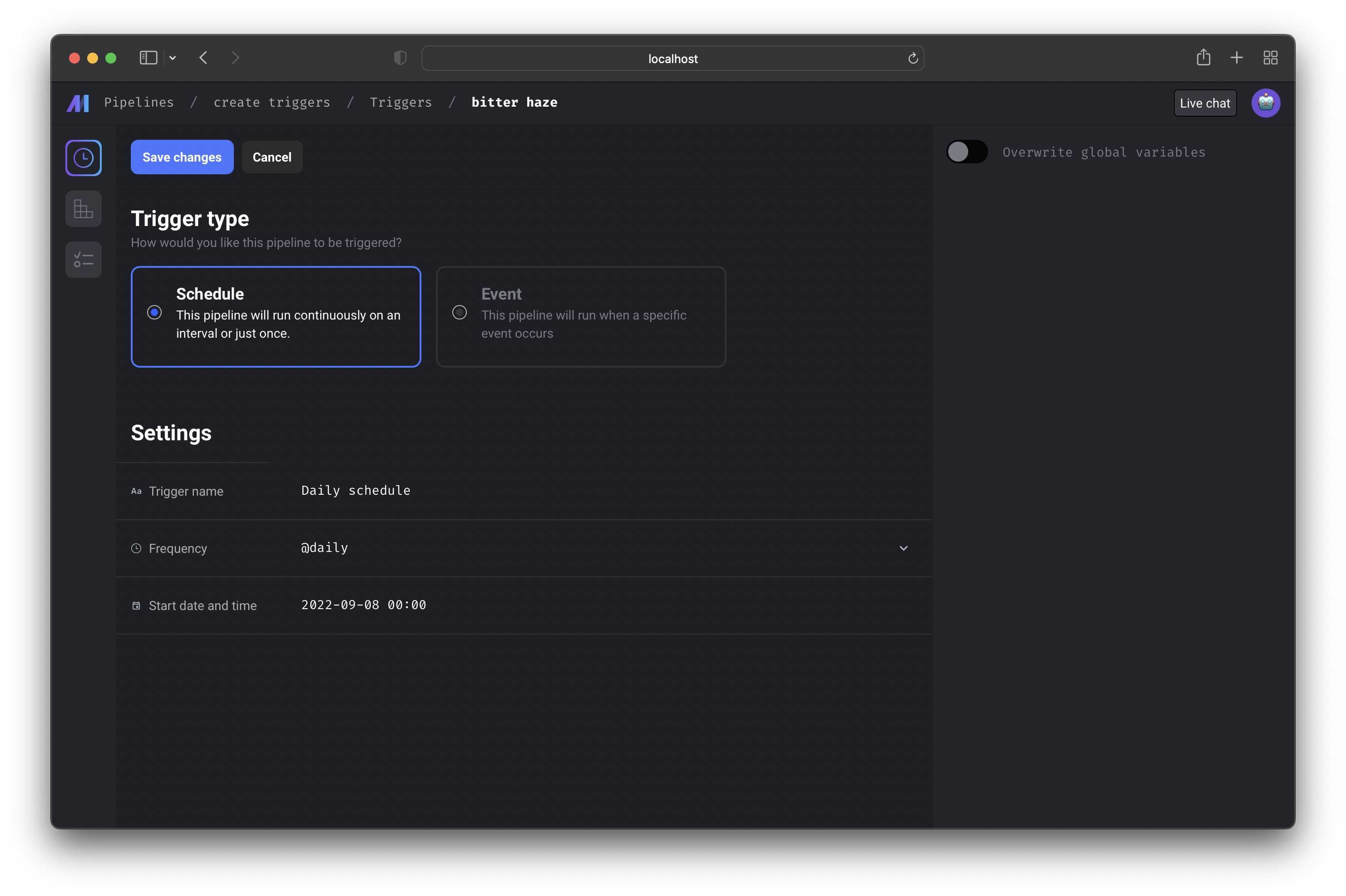
Trigger detail
On this page, you can start or pause the trigger. Starting the trigger will make it active. Pausing the trigger will prevent it from running the pipeline.If you have other triggers for this pipeline, pausing 1 trigger may not stop
the pipeline from running since other triggers can also run the pipeline.
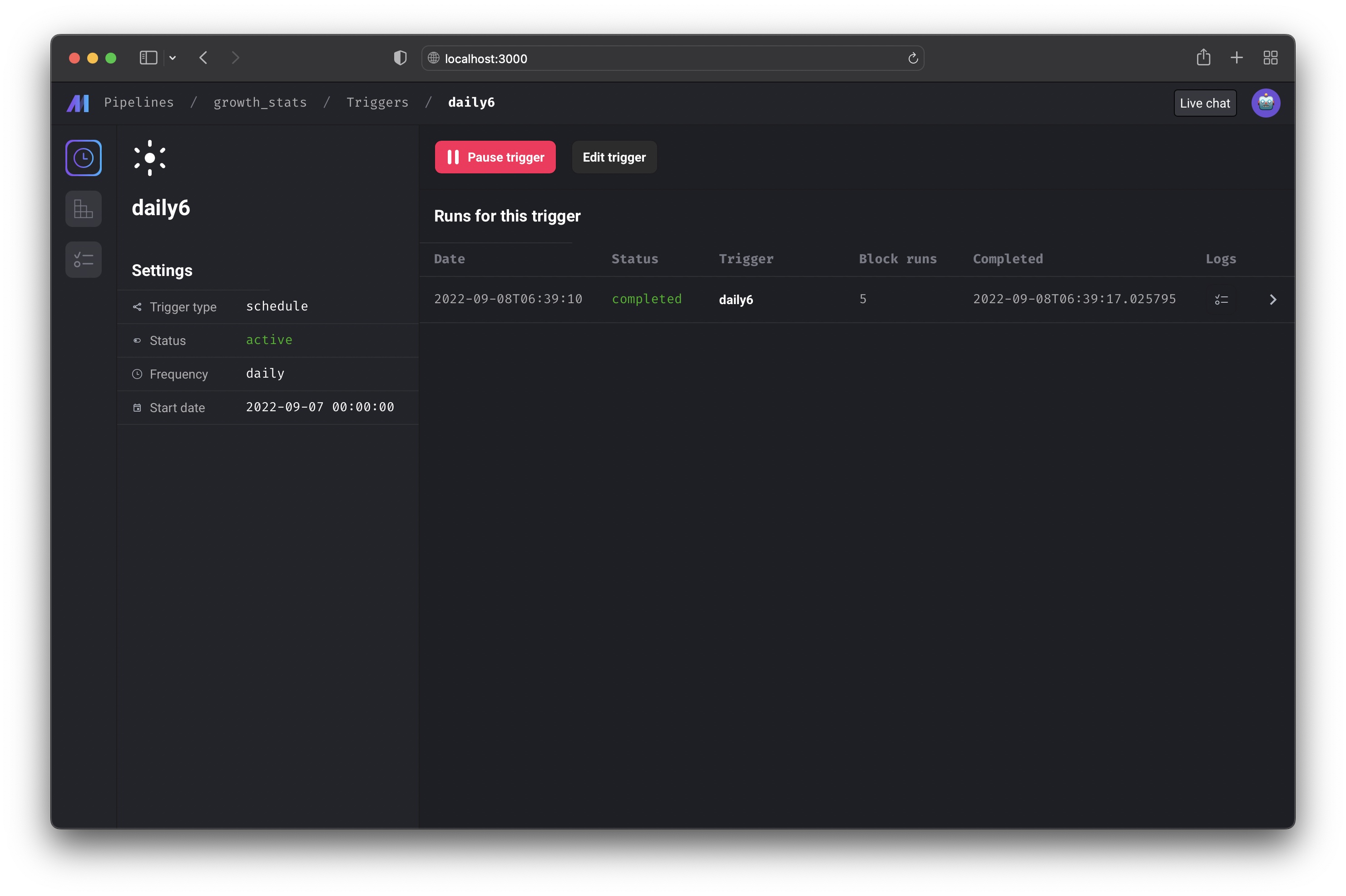 You can also edit the trigger after creating it by clicking the
You can also edit the trigger after creating it by clicking the
[Edit trigger] button.
Runs
http://localhost:3000/pipelines/example_pipeline/runs
View the pipeline runs and block runs for a pipeline.
Core abstraction: Run A run record stores information about when it was started, its status, when it was completed, any runtime variables used in the execution of the pipeline or block, etc.
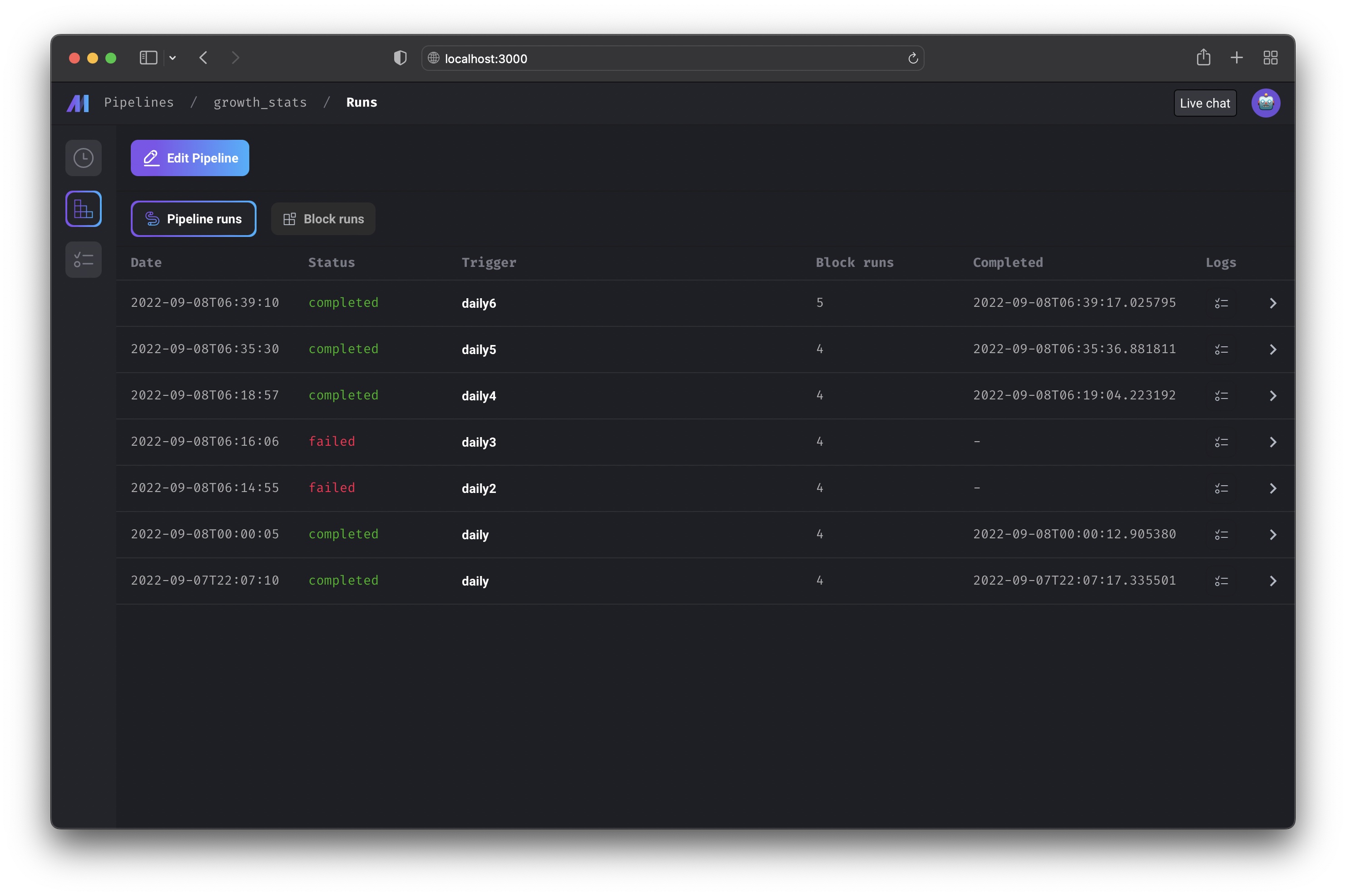
Retry run
WIPLogs
http://localhost:3000/pipelines/example_pipeline/logs
Browse all logs for a pipeline. You can search and filter logs by log level,
block type, block UUID, and more.
Core abstraction: Log A log is a file that contains system output information.
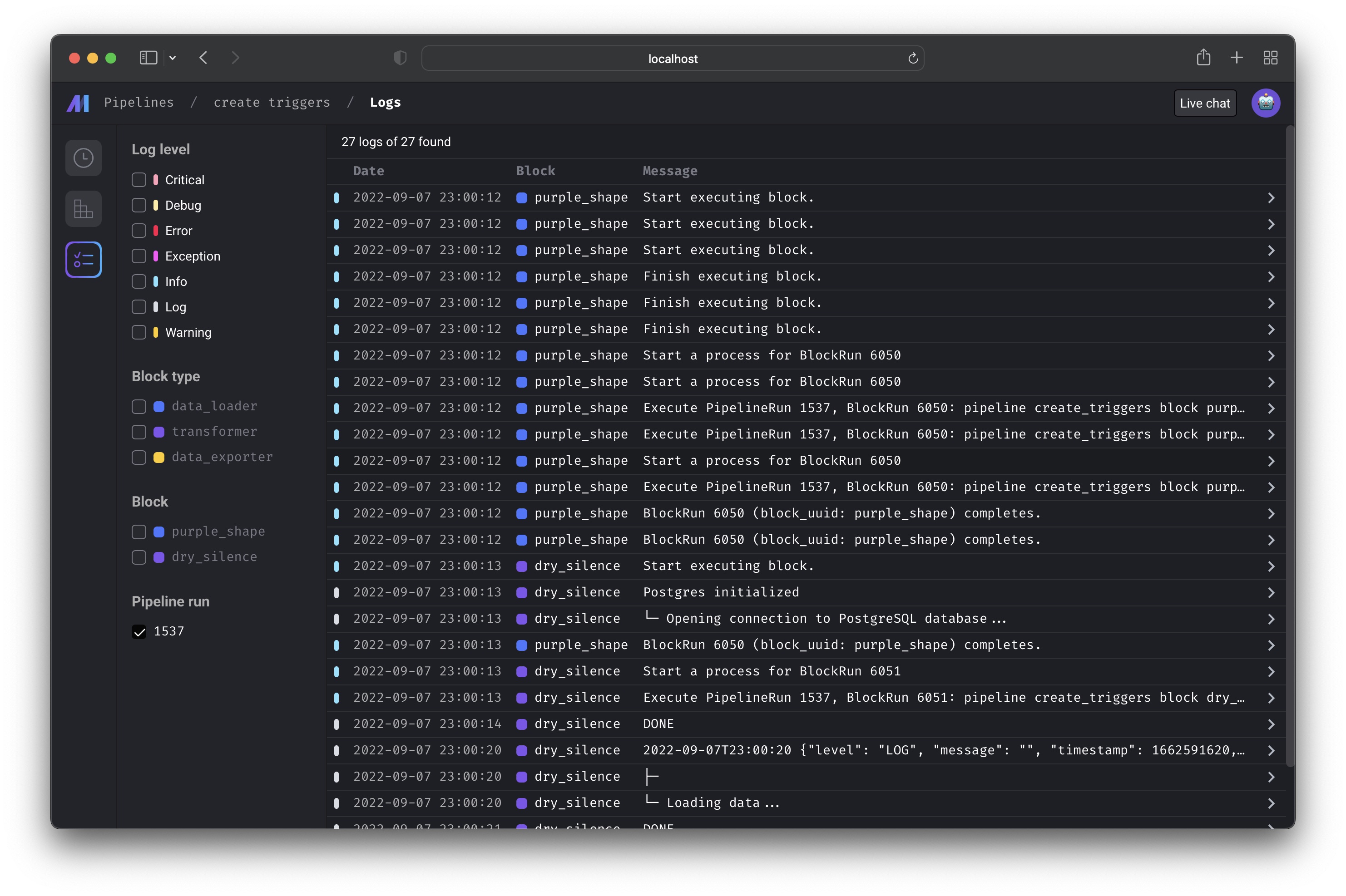
Backfill
WIPMonitor
You can monitor many metrics for each of your pipelines and blocks. Soon, you’ll be able to monitor aggregate metrics across all pipelines and blocks.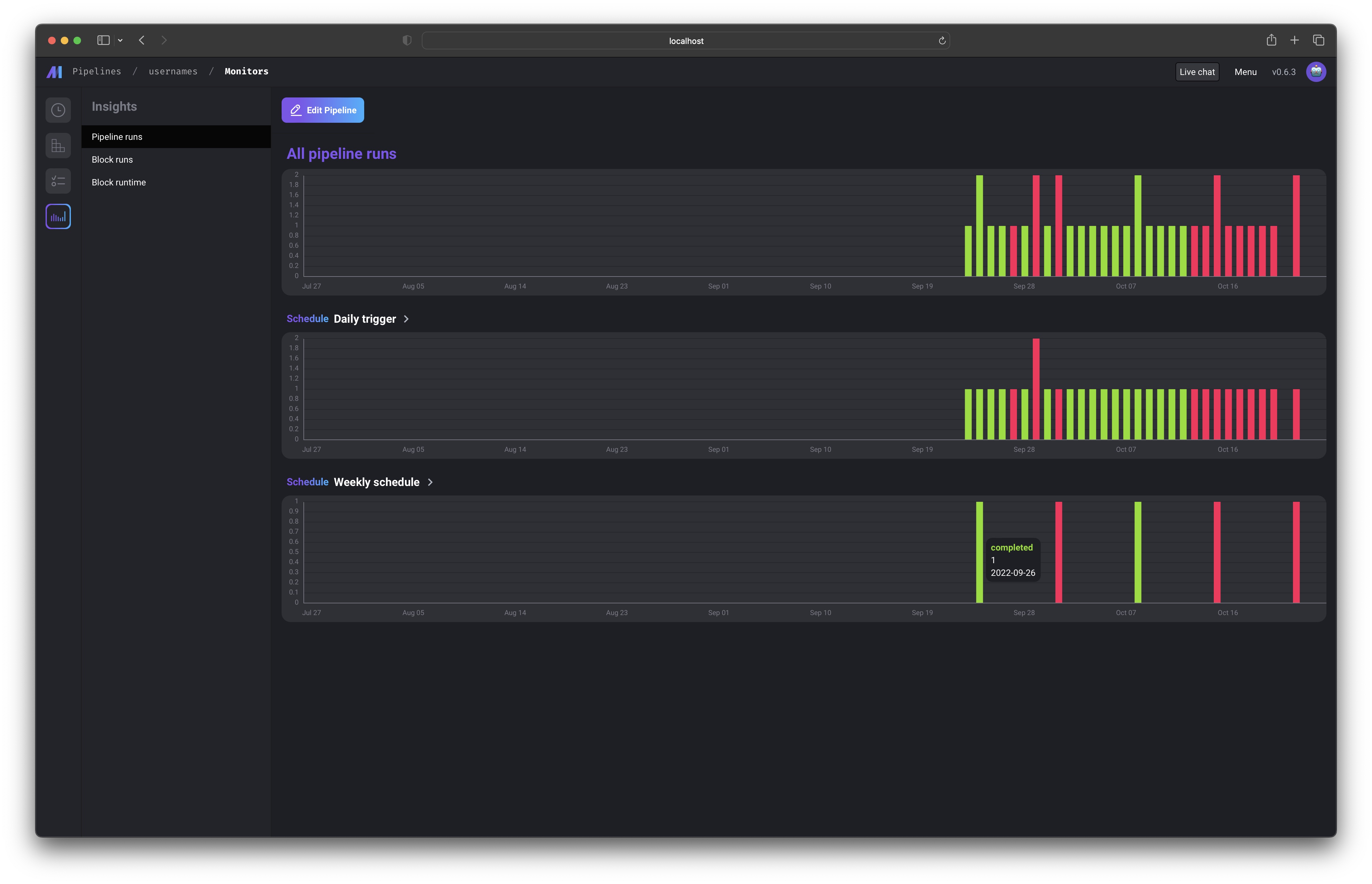 Read more here.
Read more here.
Concurrency
You can limit the concurrency of the block execution to reduce resource consumption.Global concurrency
You can configure the maximum number of concurrent block runs in project’smetadata.yaml via queue_config.
Global concurrency by block uuid
Only in Mage Pro.Try our fully managed solution to access this advanced feature.
metadata.yaml via concurrency_config.
Example
block_uuid_1can run at most 1 concurrent execution.block_uuid_2can run up to 5 concurrent executions.
- Replica blocks: Each replica is assigned a unique UUID for block run, so concurrency limits are not enforced across replicas.
- Dynamic blocks: Each dynamic child block has a unique UUID for block run, preventing concurrency limits from applying across them.
- Single-process mode: When
run_pipeline_in_one_processis set totruein the pipeline’smetadata.yaml, global concurrency is not enforced.
Pipeline level concurrency
You can edit theconcurrency_config in each pipeline’s metadata.yaml file to enforce pipeline level concurrency.
Here is the example:
block_run_limit and pipeline_run_limit can be set via environment variables: CONCURRENCY_CONFIG_BLOCK_RUN_LIMIT and CONCURRENCY_CONFIG_PIPELINE_RUN_LIMIT
block_run_limit: limit the concurrent blocks runs in one pipeline run.pipeline_run_limit: limit the concurrent pipeline runs in one pipeline trigger.pipeline_run_limit_all_triggers: limit the concurrent pipeline runs across all triggers in a pipeline.on_pipeline_run_limit_reached: choose whether towaitorskipwhen the pipeline run limit is reached.
Variable storage
Mage automatically persists the output of block runs on disk. You can specify the path or the storage for block output variables in the following ways.- Specify the data directory path via
MAGE_DATA_DIRenvironment variable. If you use Mage docker image, this environment variable is set to/home/src/mage_databy default. - If the
MAGE_DATA_DIRenvironment variable is not set, you can set thevariables_dirpath in project’s metadata.yaml. Here is an example: - You can also use an external storage to store the block output variables by specifying the
remote_variables_dirpath in project’s metadata.yaml.- AWS S3 storage:
- Google Cloud Storage:
When using GCS for your remote variables directory, if you run into a “Your default credentials were not found” error, you may need to set the
GOOGLE_APPLICATION_CREDENTIALSenvironment variable to the path of yourapplication_default_credentials.jsonfile with your Google Cloud credentials and theGOOGLE_CLOUD_PROJECTenvironment variable to your Google Cloud project ID.
- AWS S3 storage:
Variable retention
If you want to clean up the old variables in your variable storage, you can set thevariables_retention_period
config in project’s metadata.yaml. The valid period should end with “d”, “h”, or “w”.
Example config:
variables_retention_period in project’s metadata.yaml, you can run the following command
to clean up old variables:
Cache block output in memory
By default, Mage persists block output on disk. In pipeline’s metadata.yaml, you have the option to configure the pipeline to cache the block output in memory instead of persisting the block output on disk. The feature is only supported in standard batch pipeline (without dynamic blocks) for now. Example config:Operation history
Keeps track of recently viewed pipelines so you can easily navigate back to them in the Pipelines Dashboard (/pipelines). Adds a RECENTLY VIEWED tab to the Pipelines
Dashboard that lists these pipelines.