What is Mage Pro?
Mage Pro is a production-grade platform for building, running, and scaling data pipelines — with zero infrastructure hassle. You can deploy it as:- A fully managed cloud service (Mage-hosted)
- A private cloud installation (your cloud, your control)
- A hybrid cloud setup (Mage manages control plane; you host workloads)
Deployment Options
☁️ Fully Managed Cloud (Mage-hosted)
Let Mage handle everything: we manage infrastructure, upgrades, availability, and monitoring.🔒 Private Cloud (Your Infrastructure)
Run Mage Pro securely in your own cloud environment. Ideal for teams with data residency or compliance requirements.🔁 Hybrid Cloud (Split Control)
Keep data and compute in your environment while Mage manages the control plane. The best of both worlds — reduced overhead, full data privacy.Migrating to Mage Pro
1
Create multiple environments
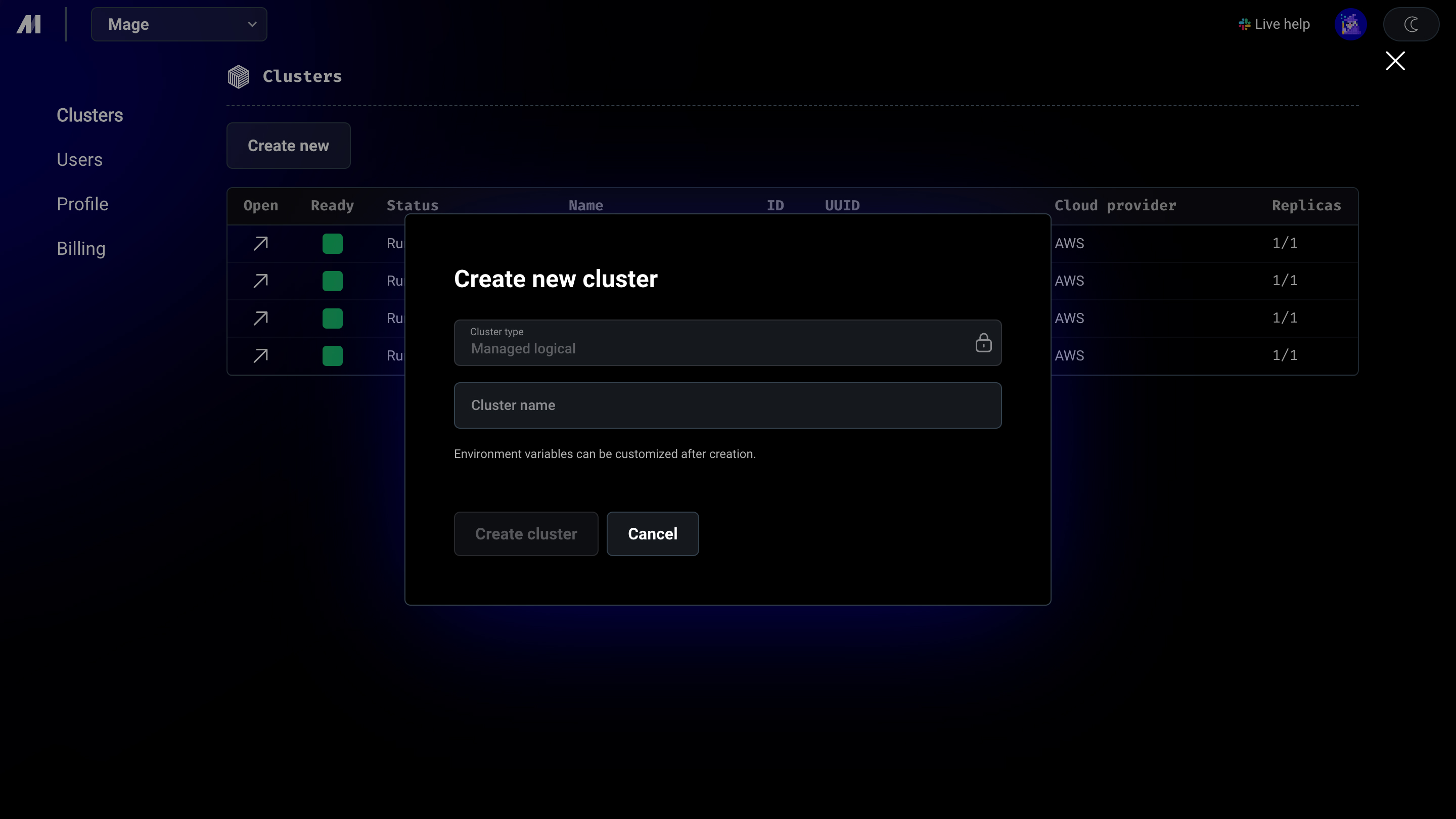
2
Customize and manage each environment
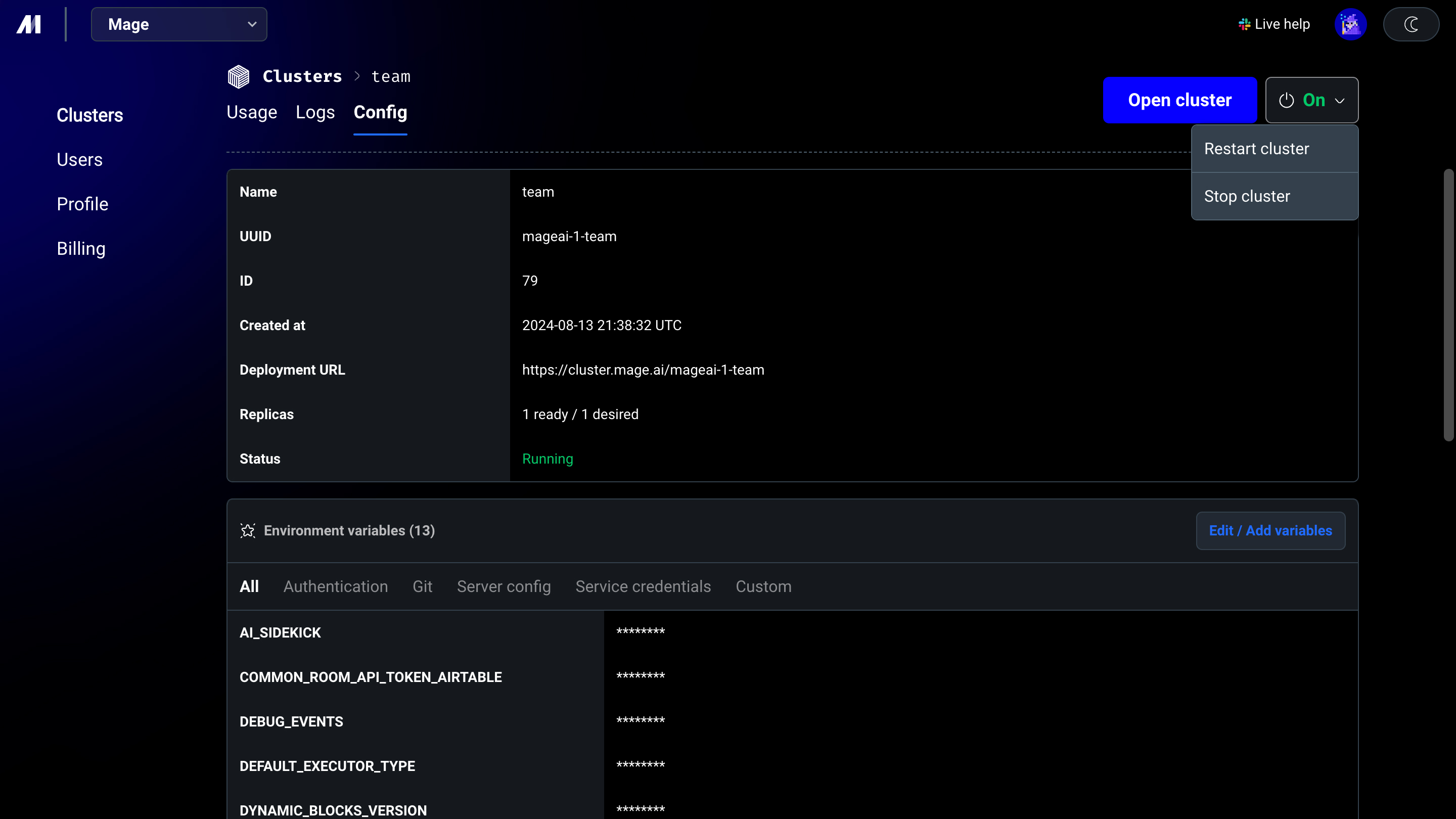
3
Monitor data pipeline CPU utilization
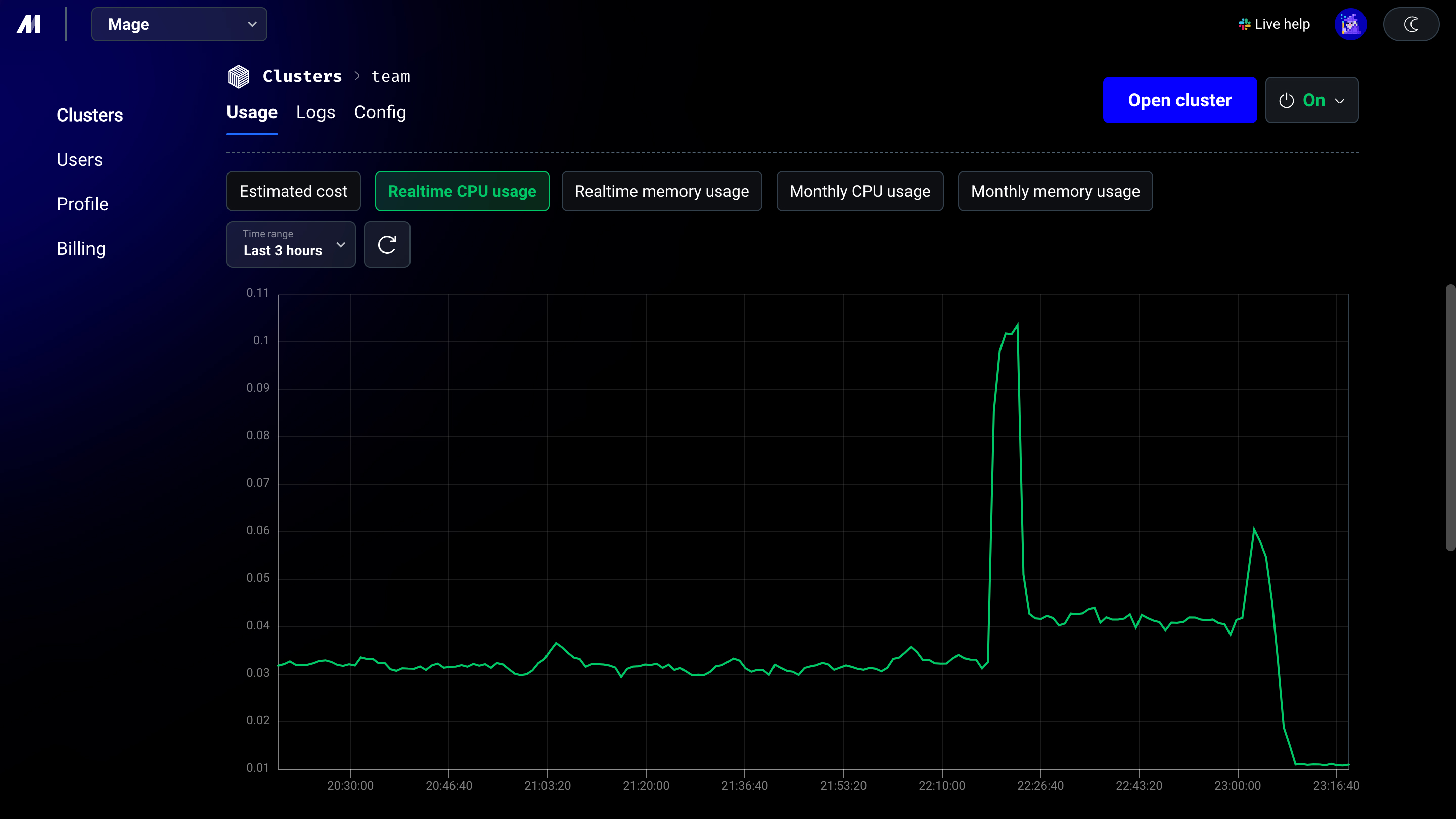
4
Monitor data pipeline memory usage
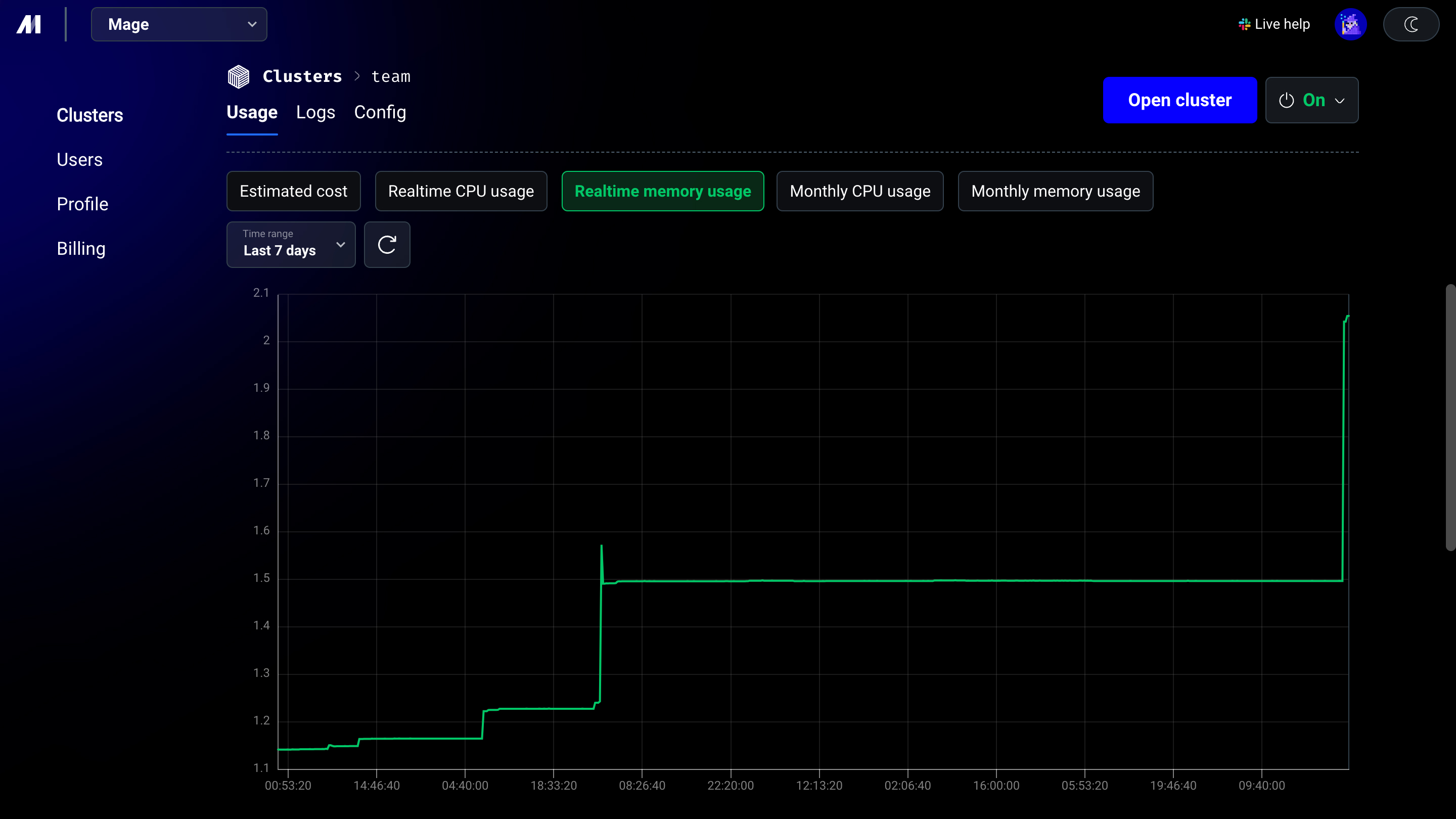
5
Migrate existing projects instantly into Mage Pro
Why Choose Mage Pro?
Mage Pro is more than just a hosted version of Mage — it’s a powerful upgrade with exclusive features, deeper integrations, and a refined developer experience for teams running data pipelines at scale.🚀 Mage Pro–Only Features
🧠 AI & Developer Experience
- AI Sidekick: Get context-aware code suggestions, explanations, and debugging for every block.
- Enhanced Code Editor: Smarter autocomplete, live error checking, and documentation hints.
- Personalized UI Themes & Light Mode: Match your workflow preferences.
- VSCode & Cursor Integration: Edit and sync directly with your local IDE.
🛠️ Advanced Orchestration & Infrastructure
- Workspaces: Create isolated environments for dev, staging, and prod.
- Pipeline-Level Resource Monitoring: Track memory and CPU usage per pipeline.
- Stateful Streaming Pipelines: Run real-time pipelines with stateful checkpointing.
- Deployment App & Version Control Terminal: Seamlessly deploy and manage pipeline code using built-in Git tools.
- More Variable Interpolation Syntax: Dynamically pass values with support for env vars, secrets, and config vars.
🔌 Pipeline Engine & Execution Enhancements
- Stateful Streaming Pipelines: Run real-time pipelines with built-in state management and checkpointing.
- Unified IO Config Framework: Use a single config structure across batch pipelines, streaming pipelines, and data integration pipelines.
- New Data Sources & Destinations: Access exclusive connectors not available in Mage OSS.
- Enhanced Existing Integrations: Benefit from optimized, production-ready versions of popular sources and destinations.
- Simplified Spark & Databricks Integration: Run distributed compute jobs with less setup and config.
- Native Iceberg Support: Work with open table formats natively for modern data lakes.
🏢 Enterprise-Grade Platform
- ☁️ Flexible Deployments: Fully managed, private cloud (your VPC), or hybrid cloud.
- 🔒 Security Built-In: RBAC, workspace isolation, secrets vault, audit logs.
- 📊 Full Observability: Built-in dashboards for logs, CPU/memory, errors, and alerts.
- 📈 Autoscaling & High Availability: Handle bursty, concurrent workloads across projects.
- 🤝 Dedicated Support & SLAs: White-glove onboarding, expert guidance, and 24/7 help if needed.
- 🔁 Instant Migration: Import OSS pipelines via Git and sync across environments.
🚀 Get Started with Mage Pro
Get started for free


A fully managed service, where we maintain the infrastructure, guarantee uptime, automatically scale your workloads to handle any volume of pipeline runs, automatically upgrade new versions of Mage Pro only features, monitor your production pipelines, and provide enterprise level support.