Build pipeline
- Add a new data loader block.
-
Paste in the following code:
-
Run the data loader block and the output will be:
-
In the top right corner of the block, click on the triple dot button (
...) and click the dropdown selection labeledSet block as dynamic.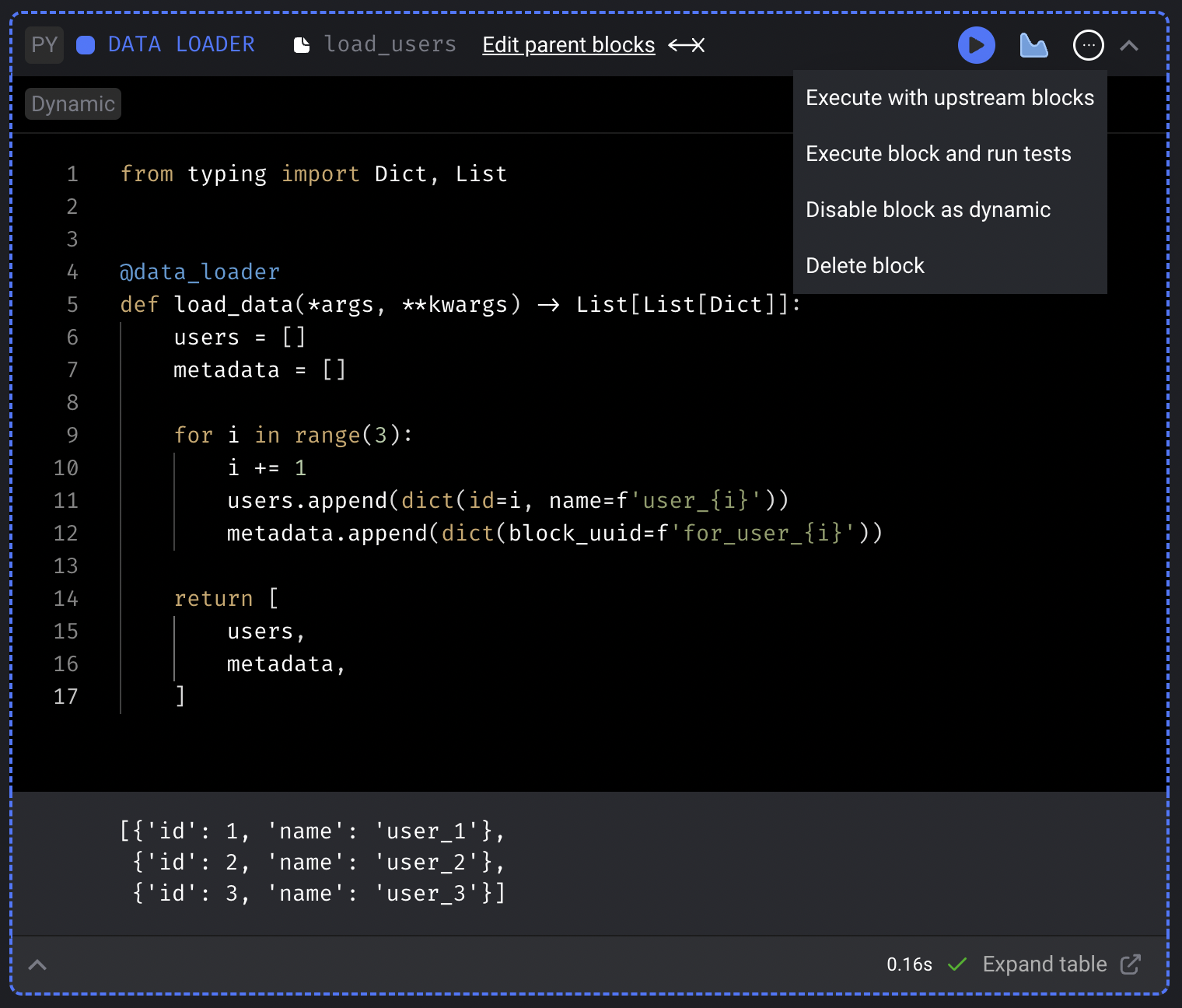
- Add a new transformer block.
-
Paste in the following code:
-
Run the transformer block and the output will be:
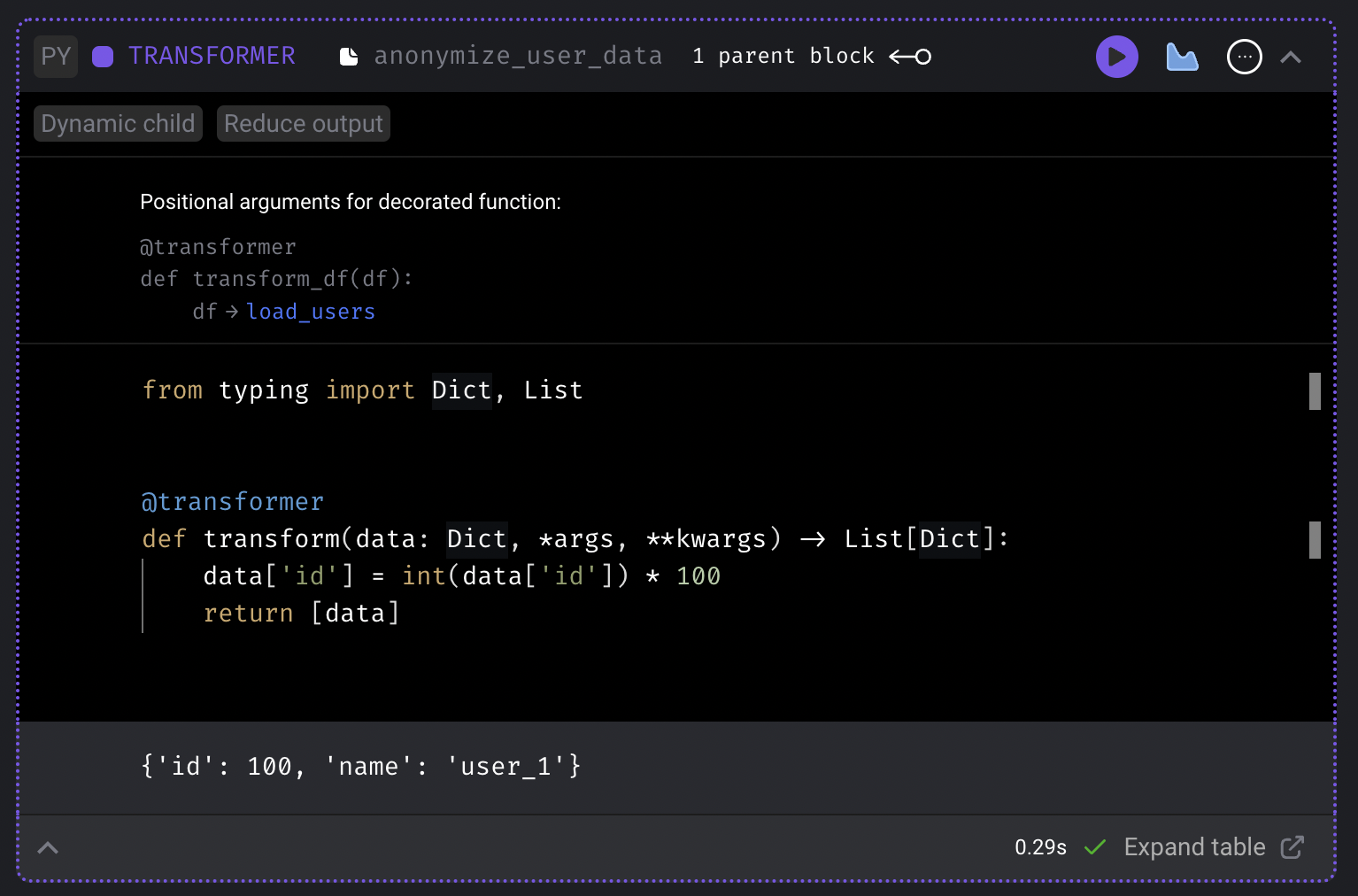
- Add another transformer block.
-
Paste in the following code:
- Change the 2nd transformer block’s upstream parent block to only be the data loader. This will require you to remove the existing upstream parent block which is currently pointing to the 1st transformer block.
-
In the top right corner of this 2nd transformer block,
click on the triple dot button (
...) and click the dropdown selection labeledReduce output. -
Run the transformer block and the output should look something like this:
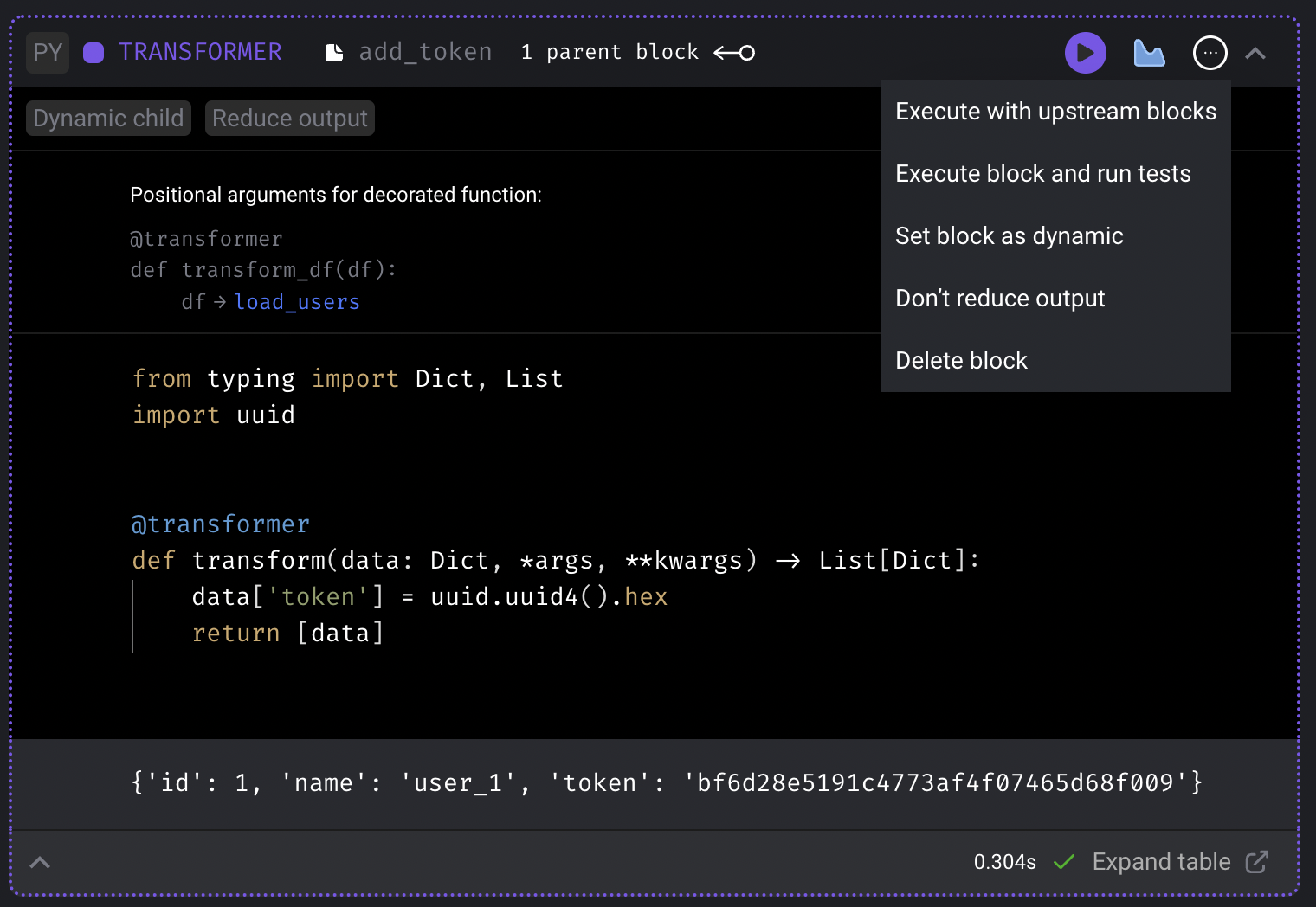
- Add a new data exporter block.
-
Paste in the following code:
-
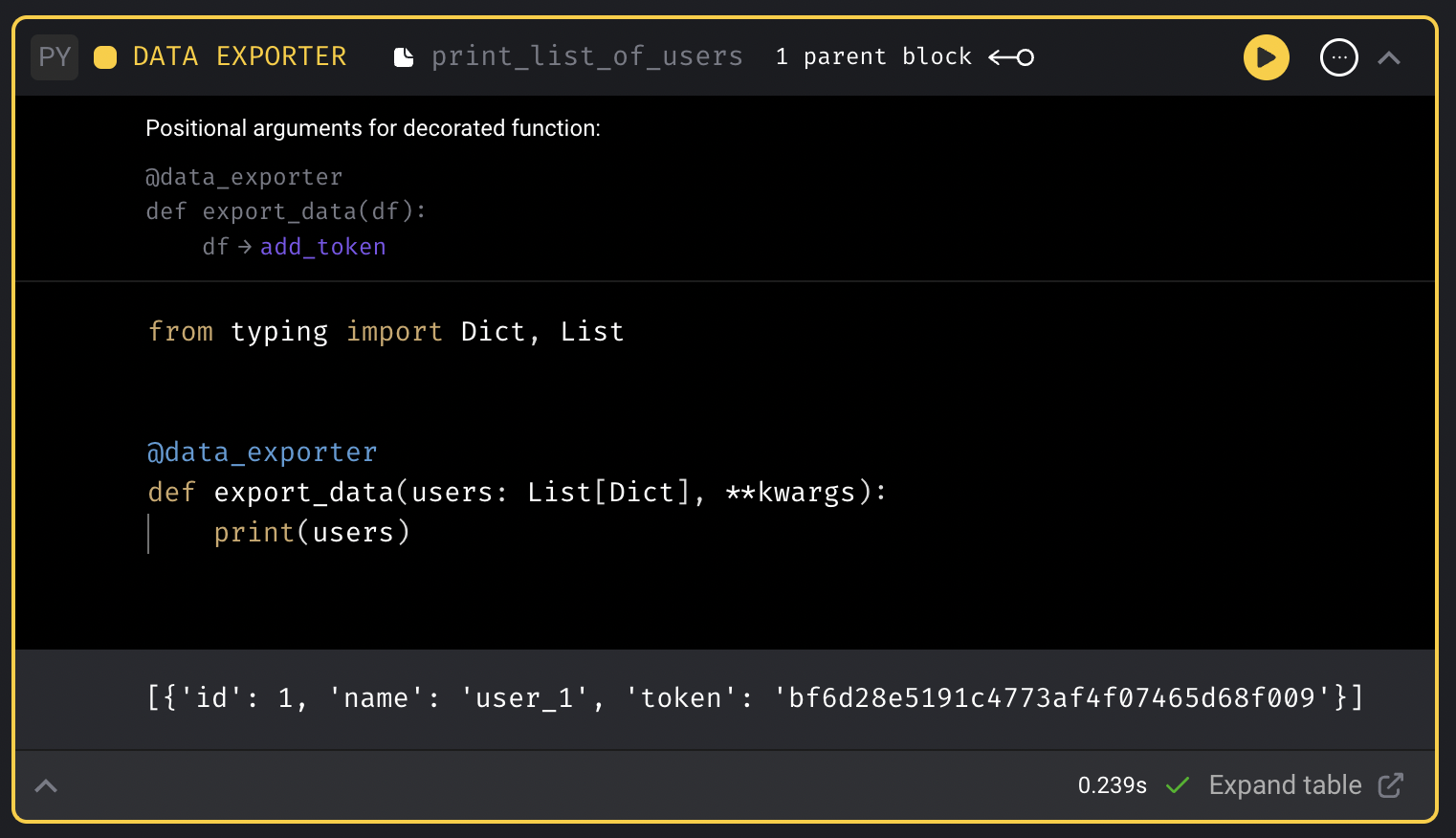
Run the data exporter block and the output should look something like this:
When executing the entire pipeline, this output will contain 3 items in this list.
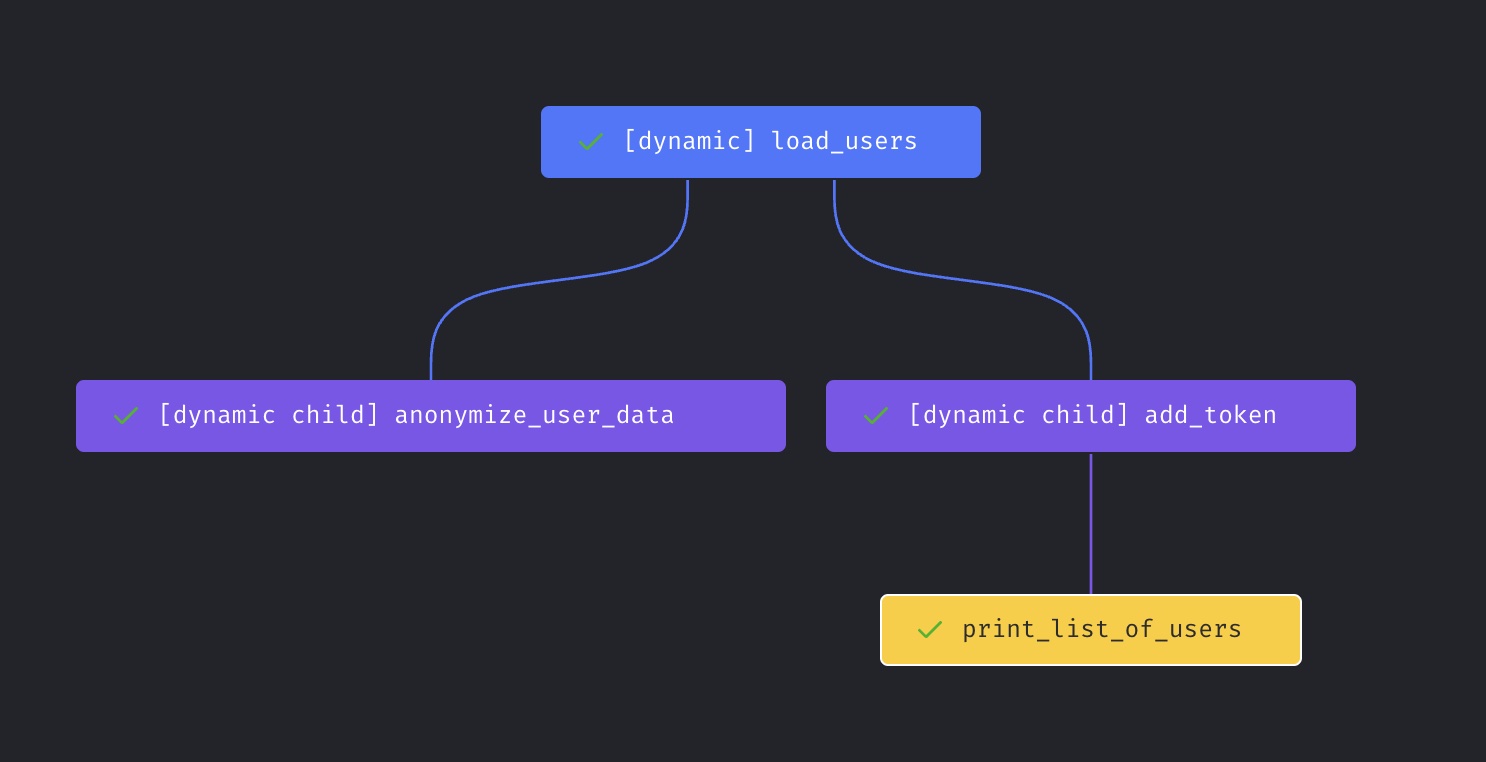
Run pipeline
- Click the pipeline name in the top left corner (e.g the breadcrumbs). This will take you to the pipeline’s trigger page.
- Click the button
[Run @once]in the page’s subheader, or create a trigger to run once. - Click the name of the newly created trigger.
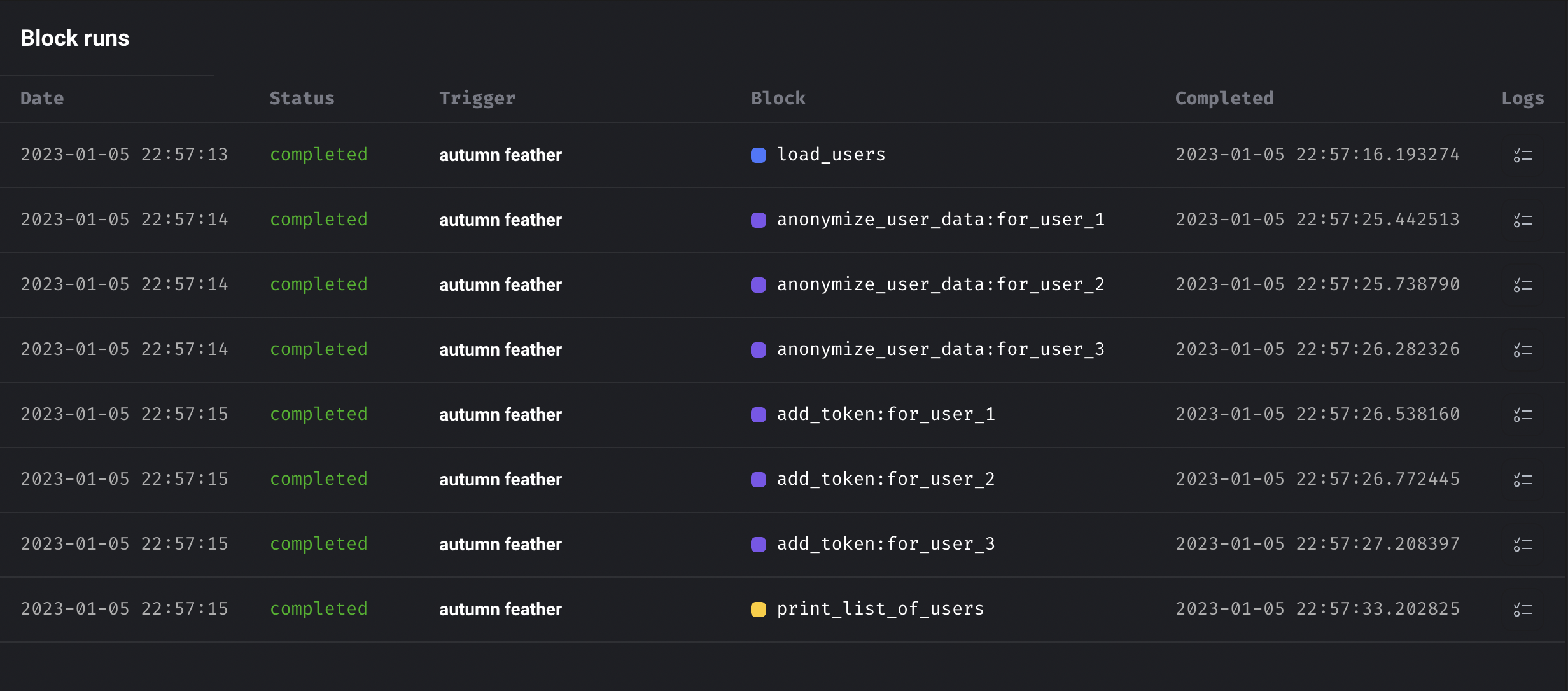
- The trigger will create 1 pipeline run with 9 block runs.
Limit dynamically created blocks
To prevent a dynamic block from creating too many downstream block runs, set a maximum number of dynamic child block runs. To throttle execution after those rows are created, set a maximum number of concurrent dynamic child block runs. Unset values and0 allow unlimited dynamic child
block creation or concurrent dynamic child execution.
Set workspace-wide defaults with the DYNAMIC_BLOCKS_MAX_CHILD_BLOCKS and
DYNAMIC_BLOCKS_MAX_CONCURRENT_CHILD_BLOCKS environment variables. Set
DYNAMIC_BLOCKS_MAX_CHILD_BLOCKS_BEHAVIOR to fail to stop runs that exceed the creation limit,
or limit to create only up to the configured maximum. You can also add this to the project
metadata.yaml:
metadata.yaml:
Dynamic blocks 2.0
In version 1.0 of dynamic blocks, Mage was loading all the data of an upstream dynamic child block from disk into memory in order to calculate how many dynamic child blocks should be created. This can result in using large amounts of memory. In version 2.0 of dynamic blocks, Mage leverages the metadata of upstream block outputs to calculate the number of downstream blocks for dynamic blocks and dynamic child blocks. The metadata is only several bytes on disk and less than a kilobyte in RAM.Stream mode
Here is a sample scenario to describe the previous and current state:- Dynamic block A returns a list of 10 items and has 1 direct downstream block B.
- B is a dynamic child block and has 2 direct downstream block: C and D.
- C is a dynamic child block and has 1 direct downstream block: D.
- Block A finishes executing and returns an output of 10 items.
- Block B spawns 10 dynamic child blocks.
- Block B executes all 10 dynamic blocks concurrently.
- Once all 10 block runs from block B finishes, block C starts.
- Block C spawns 10 child blocks and executes them.
- Once Block C completes all 10 runs, block D starts.
- Block D spawns 100 child blocks and executes them.
- Block A executes and can be handled in 2 ways:
- Serial: block A executes its code line by line and at the end, the return statement outputs the entire result of 10 items in a list.
- Generator: block A executes its code line by line up until a yield block. Once yield is called, the object that is yielded is stored as an output of block A. In this example, block A would yield 10 times, 1 for each item.
- As soon as 1 output is detected from block A, block B spawns 1 dynamic child that consumes that single output as its input argument.
- As soon as 1 output is detected from block B, block C spawns 1 dynamic child.
- As soon as 1 output is detected from both block B and block C, block D spawns 1 dynamic child.