Credentials
Before starting, you need to add credentials so Mage can execute your SQL commands. Follow the steps for the database or data warehouse of your choice:- BigQuery
- ClickHouse
- Databricks (Mage Pro only)
- Druid
- DuckDB
- MySQL
- Oracle (Mage Pro only)
- PostgreSQL
- Redshift
- Snowflake
- SQLite (Mage Pro only)
- Microsoft SQL Server
- Trino
Add SQL block to pipeline
- Create a new pipeline or open an existing pipeline.
- Add a data loader, transformer, or data exporter block.
- Select
SQL.
Configure SQL block
There are 4 - 5 fields that must be configured for each SQL block:Write policies
YAML configuration
You can also modify block configuration in pipeline’smetadata.yaml file. Each block has a configuration field.
Example configuration
Dynamic data_provider_profile
You can configure the data_provider_profile in a SQL block to resolve dynamically at runtime using Mage variable syntax.
This is done by modifying the pipeline’s metadata.yaml directly.
Example:

Automatically created tables
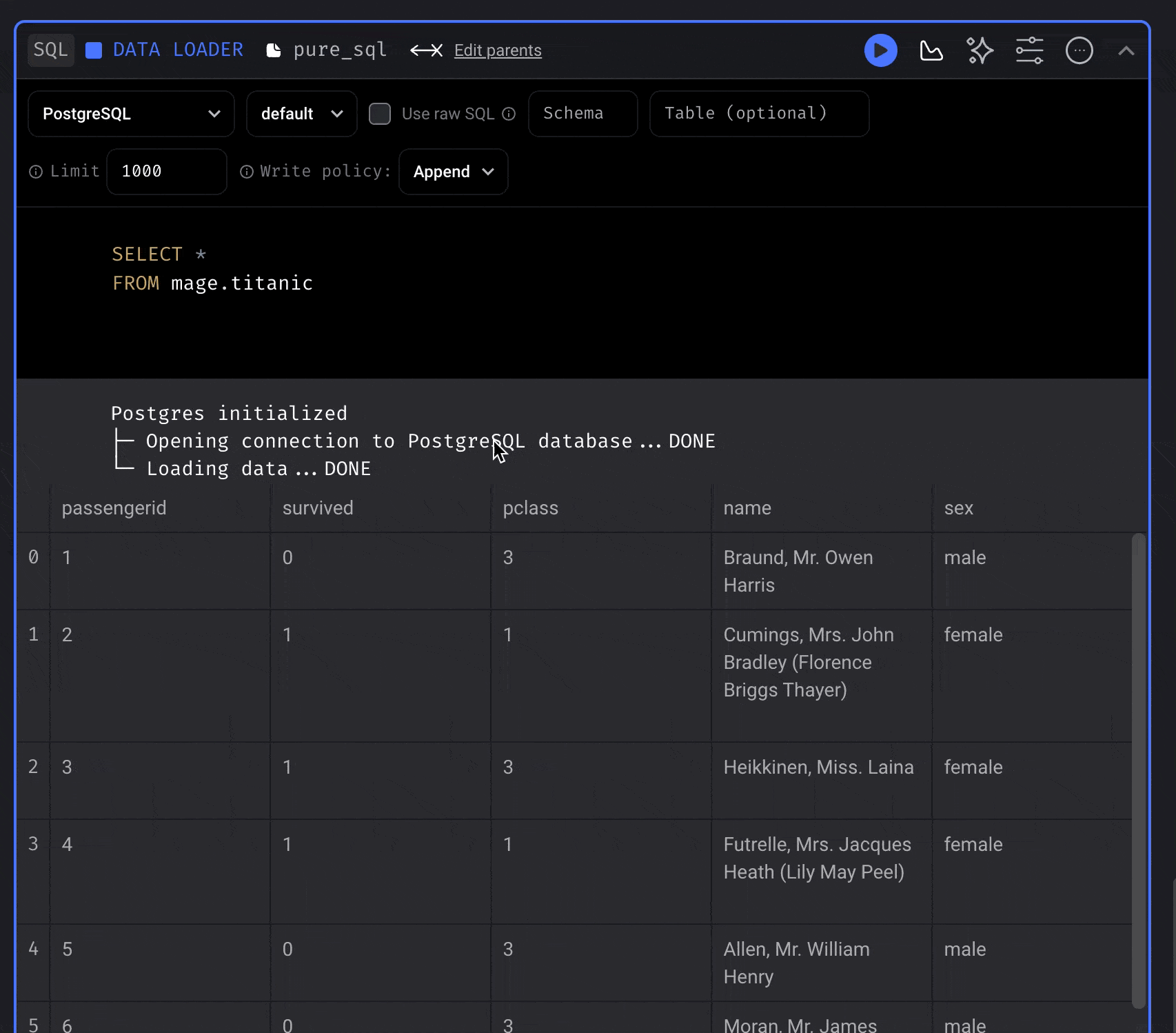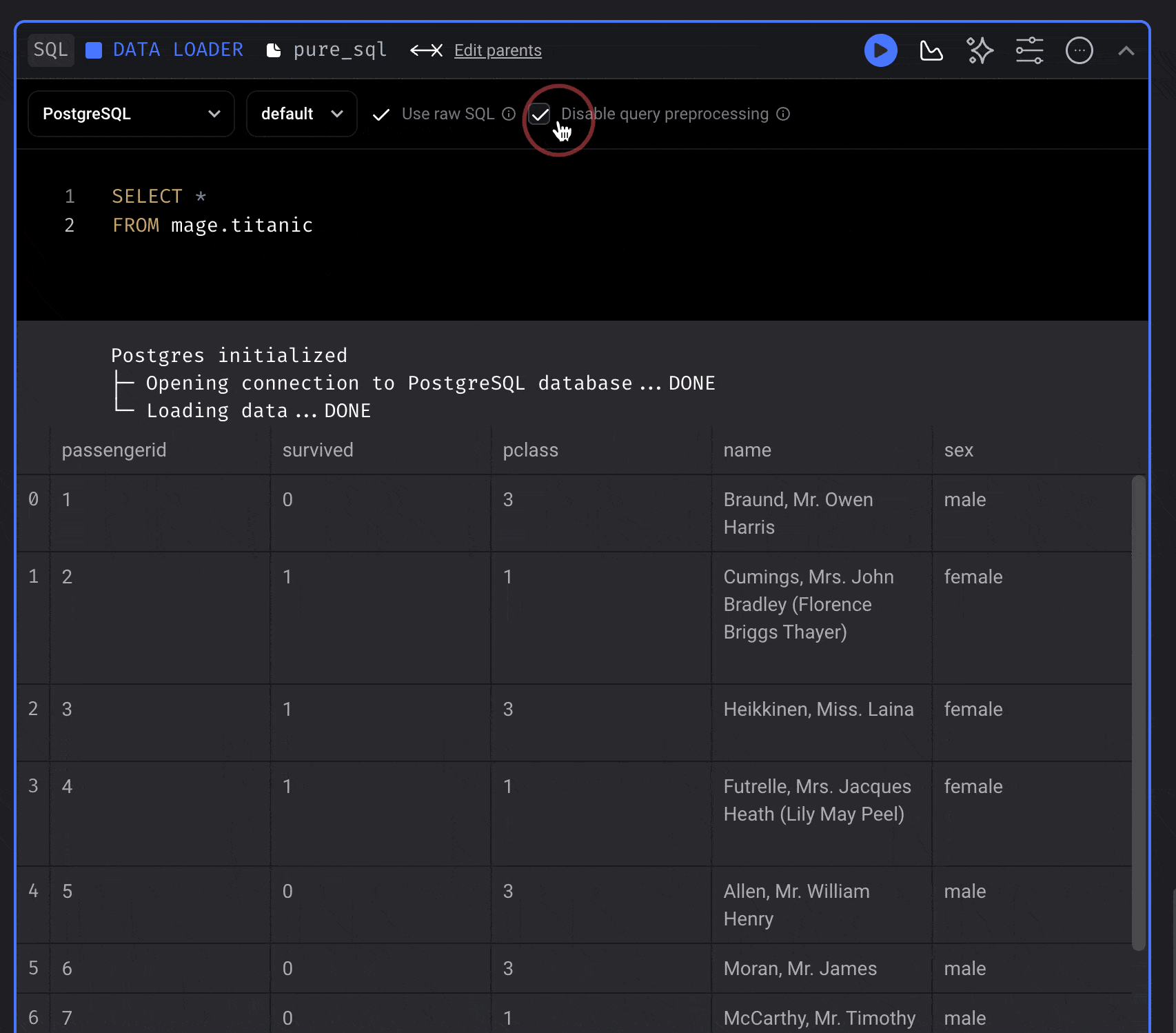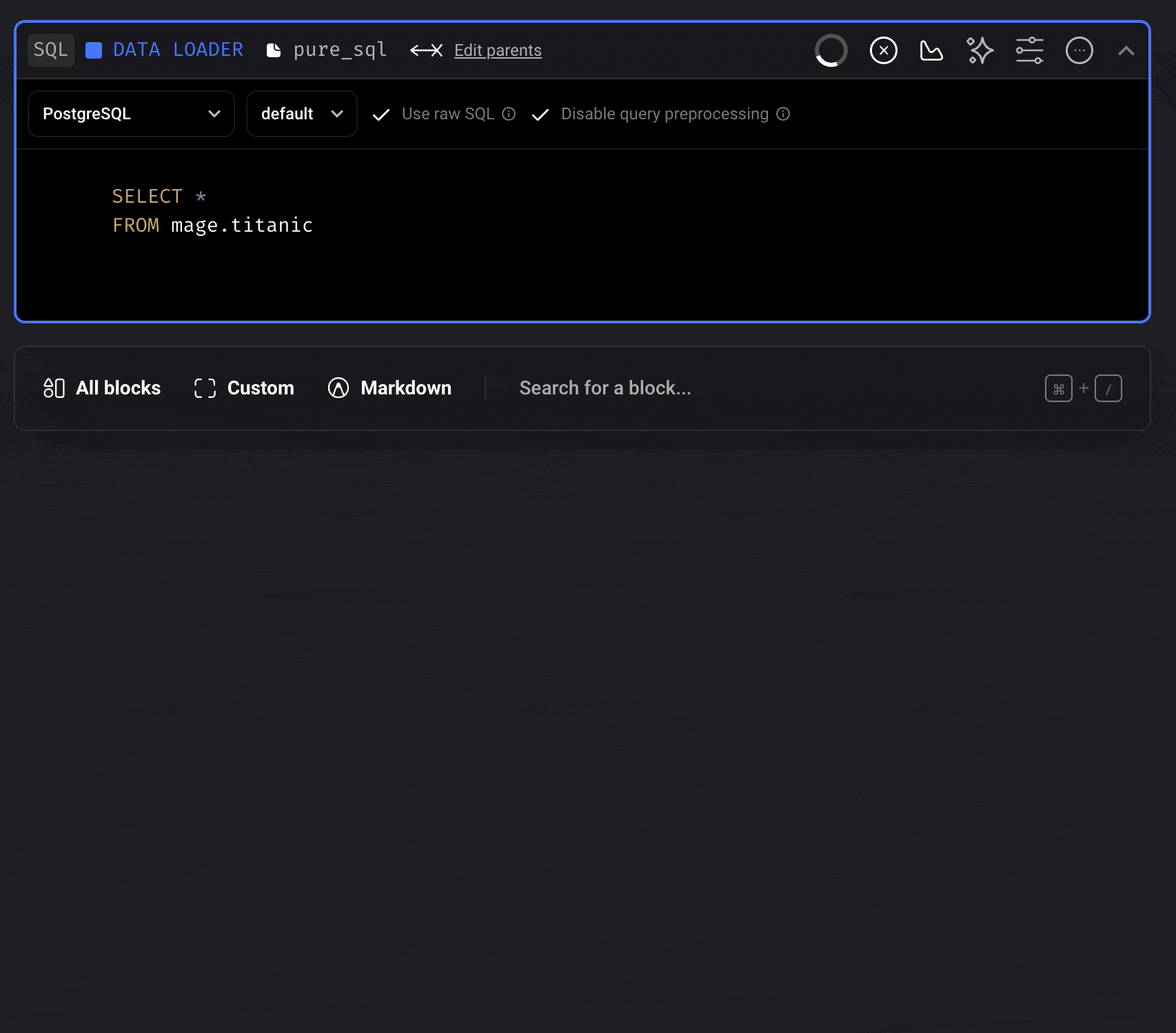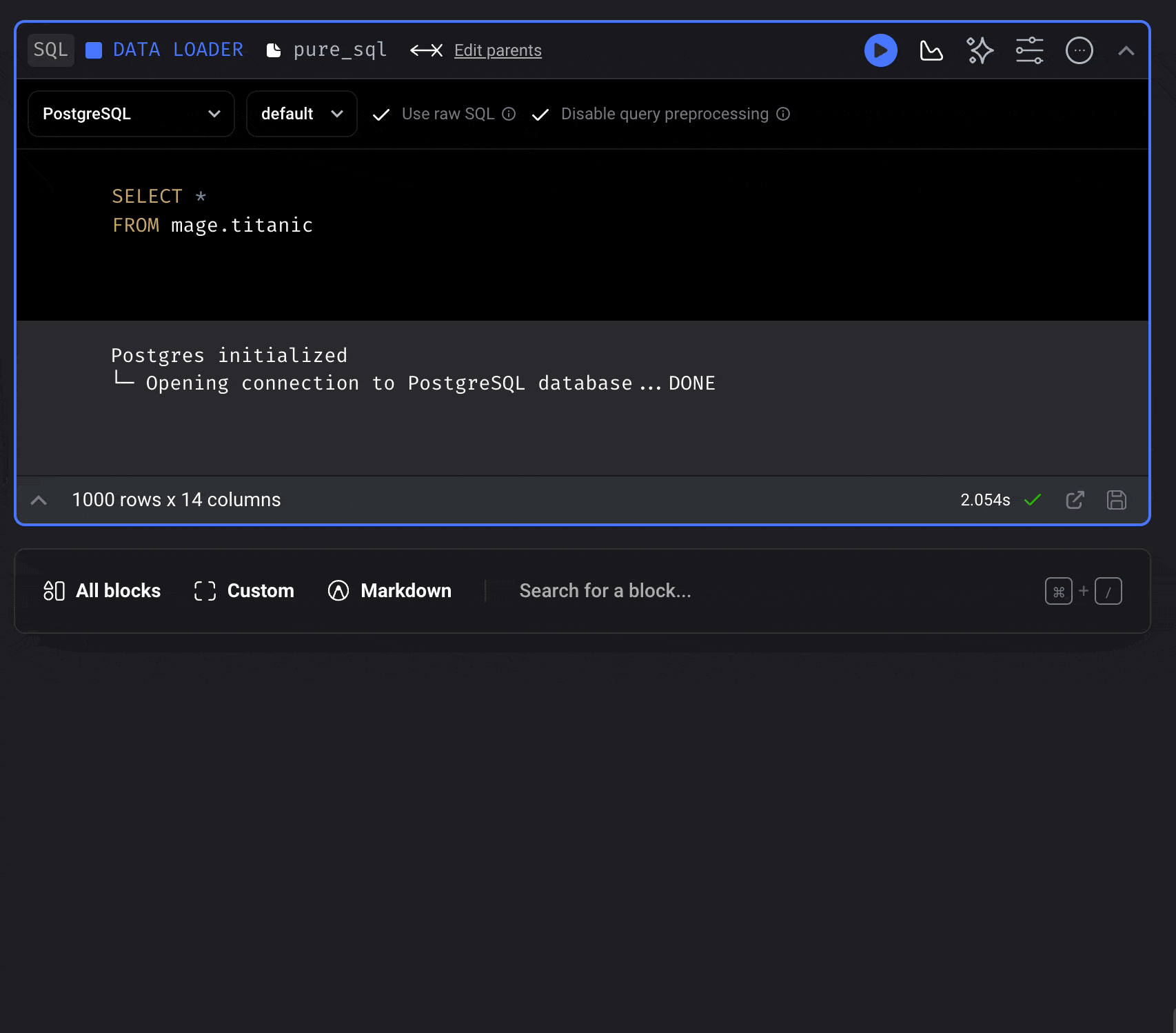
Each SQL block will create a table in the data provider of your choice. When you run a block, it’ll execute your SQL command, then store the results in a table created in your database or data warehouse.Using raw SQL
If you toggle this setting, you’re responsible for writing theCREATE TABLE command and the
INSERT command.
For example, if a table already exists then you can write the INSERT statement:
CREATE TABLE statement
and the INSERT statement:
mage.users with 2 columns: id as a BIGINT
and username as a VARCHAR(255).
Then, it’ll insert a single row into that table.
Required SQL statements
When writing raw SQL, you must use at least 1 of the following statements:SELECTINSERTCREATE TABLEDROP TABLEUPDATE
Multiple SQL statements
You can execute multiple SQL statements in a SQL block. Separate your SQL statements using a semi-colon (;).
Automatic naming of tables
If you don’t choose the setting for using raw SQL, the name of this automatically created table follows these conventions:- If
Databasefield is configured:[database].[schema].[pipeline UUID]_[block UUID] - If no
Databasefield is configured:[schema].[pipeline UUID]_[block UUID]
Upstream blocks
If your SQL block depends on upstream blocks that aren’t SQL blocks (e.g. Python code blocks), then those blocks will also automatically create tables. The name of those tables follows the same naming convention mentioned above.Variables
All SQL blocks have the following variables they can access in their query:{{ execution_date }}
The date and time the block is run.
Example
If a SQL block has 1 or more upstream blocks, then they have access to their parent blocks’ output using the following variable:
{{ df_1 }}
Depending on how many upstream blocks there are, the variable name changes. For
example, if there are 3 upstream blocks then there are 3 variables that can be
accessed:
{{ df_1 }}{{ df_2 }}{{ df_3 }}
{{ df_1 }}, and every
upstream block added after that will have an incrementing number in the variable
name after the prefix df_.
Example
Variable interpolation
Available in versions >=
0.9.59- Upstream block output
- Variables
- Global variables
- Pipeline variables
- Runtime variables
- Environment variables
Upstream block output
Use the data from 1 or more upstream block’s output by using theblock_output function.
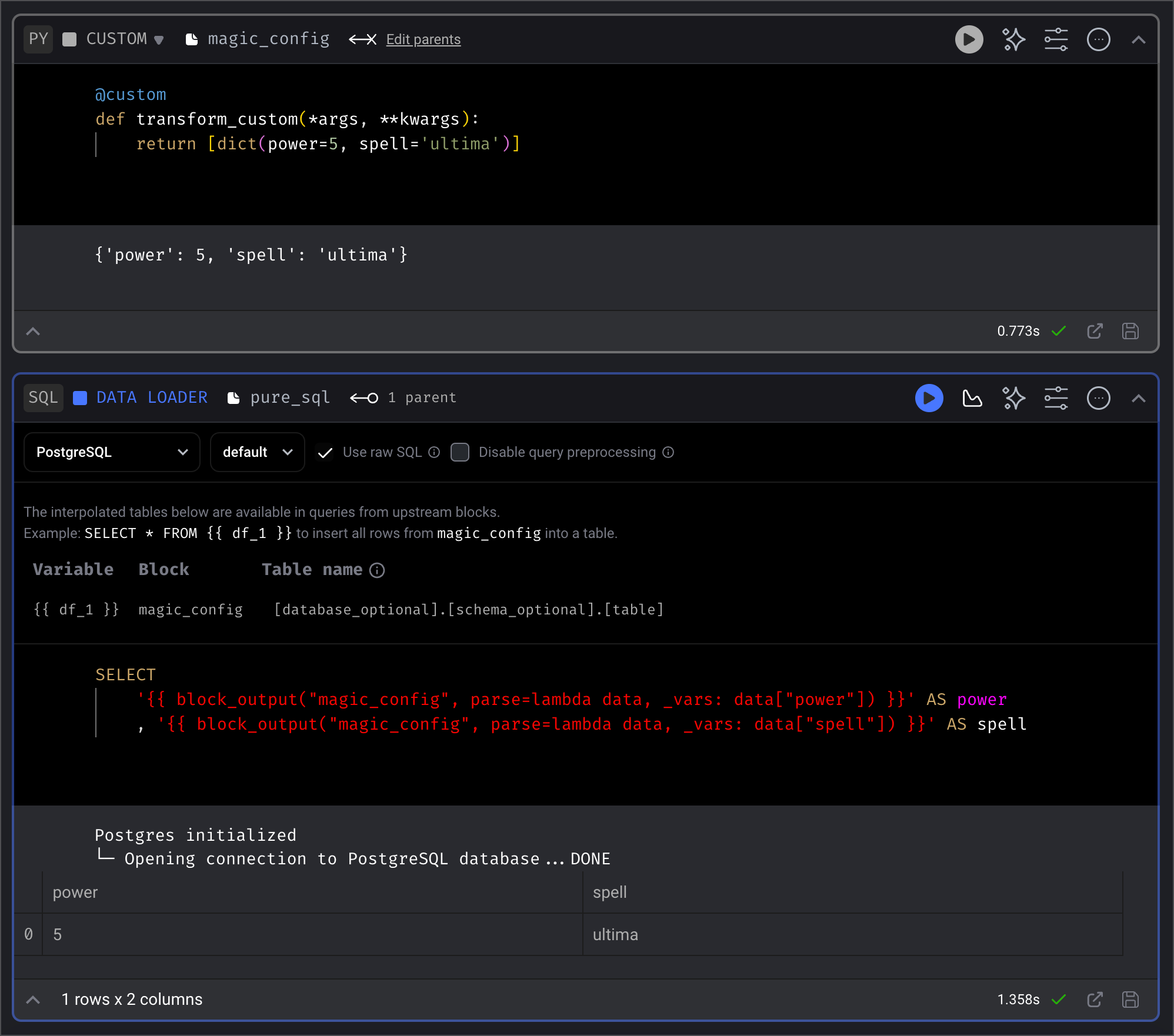
block_uuid
The UUID of the upstream block to get data from.
If argument isn’t present, data from all upstream blocks will be fetched.
parse
A lambda function to parse the data from an upstream block’s output.
If the parse argument isn’t present, then the fetched data from the upstream block’s output
will be interpolated as is.
Arguments
-
dataIf theblock_uuidargument isn’t present, then the 1st argument in the lambda function is a list of objects. The list of objects contain the data from an upstream block’s output. The positional order of the data in the list corresponds to the current block’s upstream blocks order. For example, if the current block has the following upstream blocks with the following output:load_api_data:[1, 2, 3]load_users_data:{ 'mage': 'powerful' }
-
variablesA dictionary containing pipeline variables and runtime variables.
Example
Withblock_uuid
block_uuid
Variables
Interpolate values from a dictionary containing keys and values from:- Global variables
- Pipeline variables
- Runtime variables
Example
Environment variables
Interpolate values from the environment variables.Example
Executing pure SQL
Available in versions >=
0.9.59