Adding blocks made easy
You can quickly add blocks of code to your pipeline with these methods:Drag blocks from the file browser and drop it on the pipeline
Drag blocks from the file browser and drop it on the pipeline
Supported block type directories:
callbacks, conditionals, custom, data_exporters, data_loaders, dbt,
dbts, markdowns, scratchpads, sensors, and transformersVersion 0.9.64 or greater is required to add callback and conditional
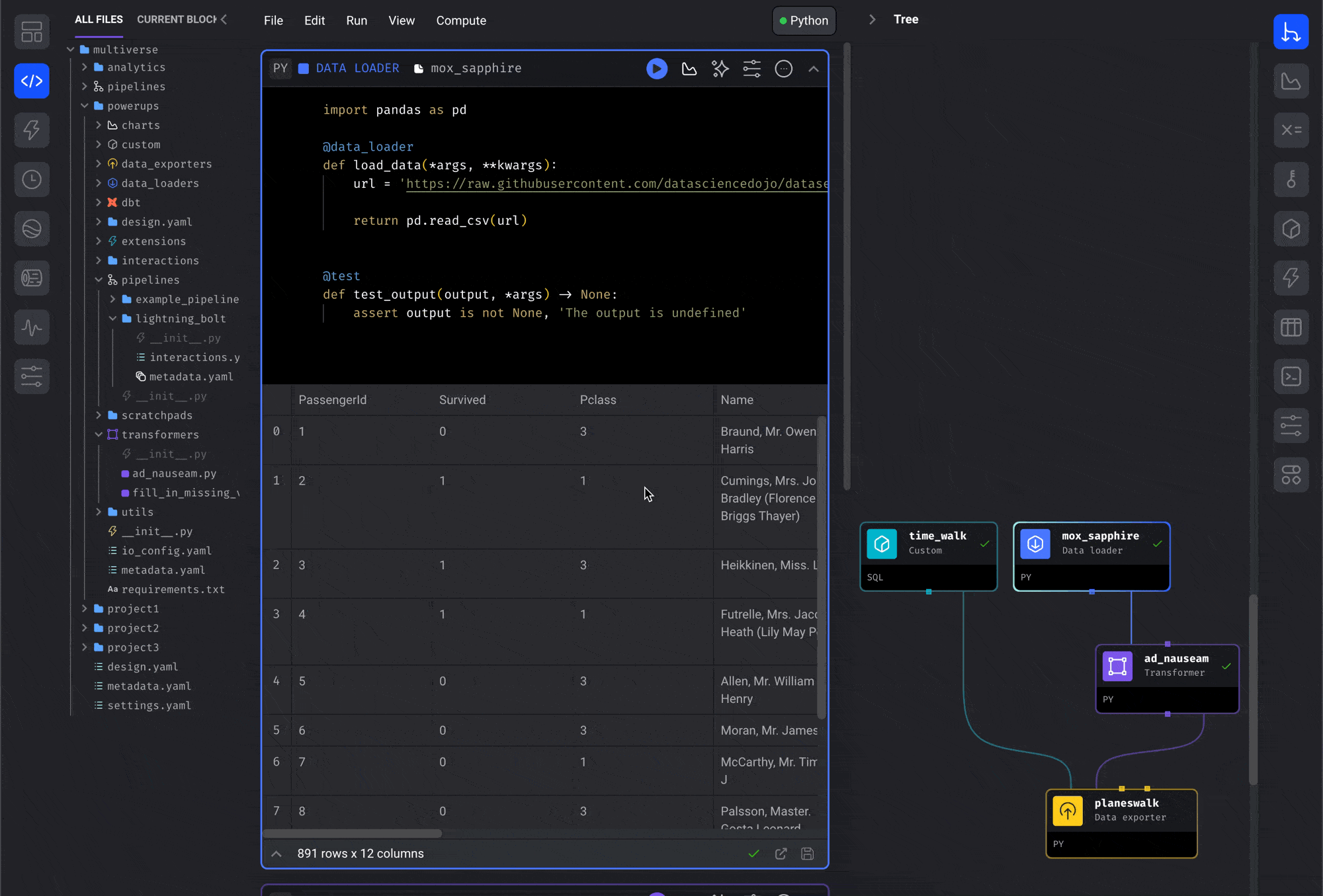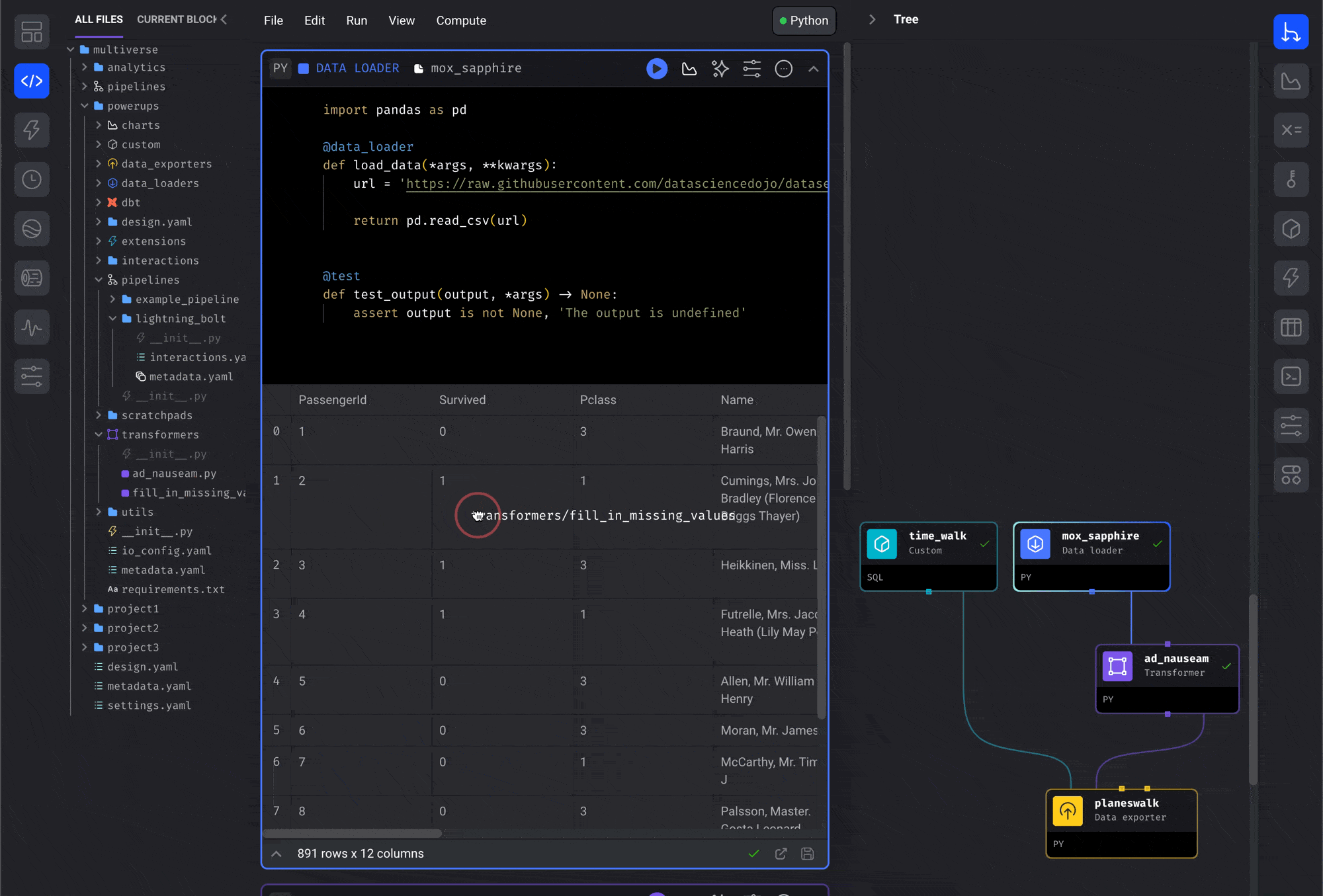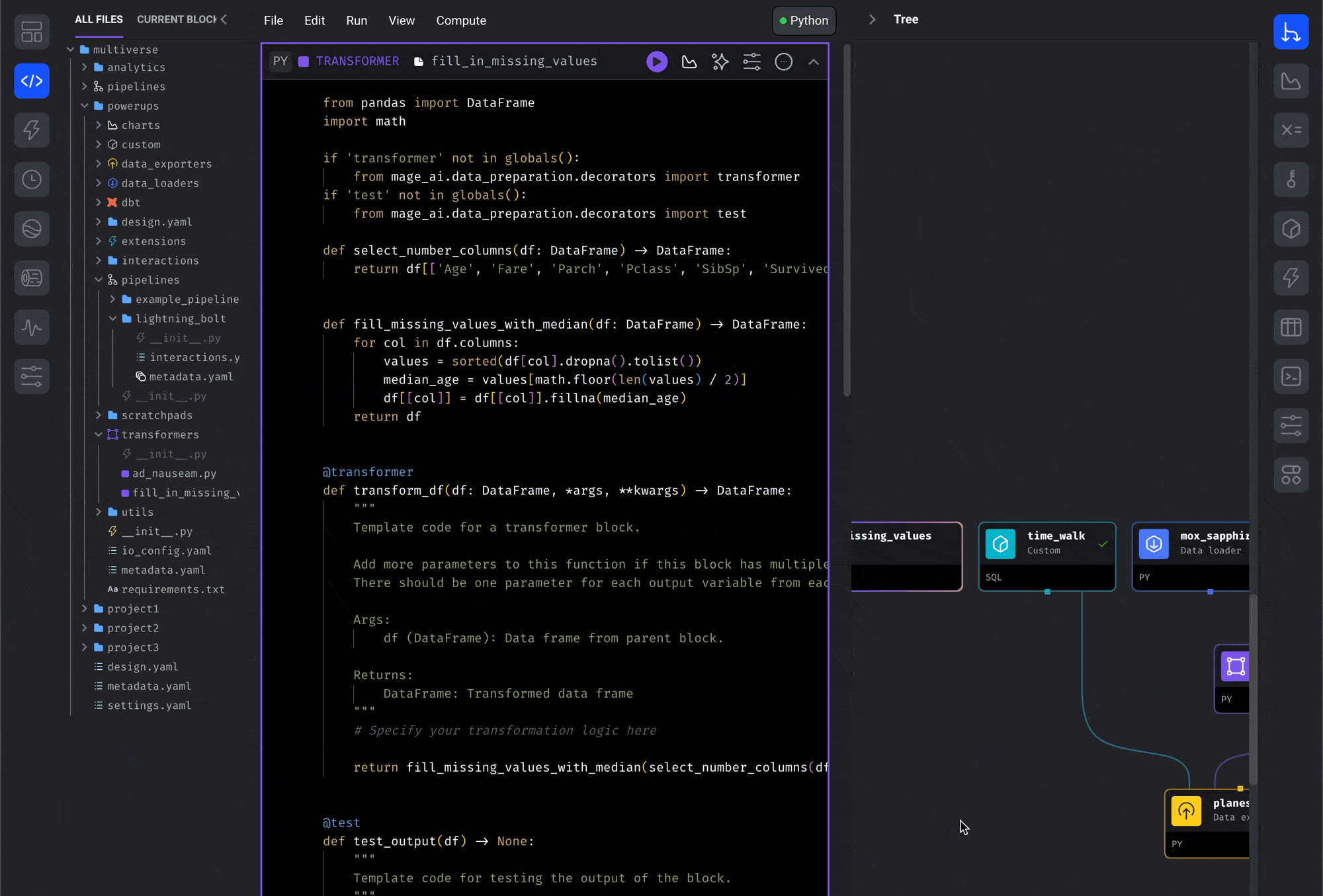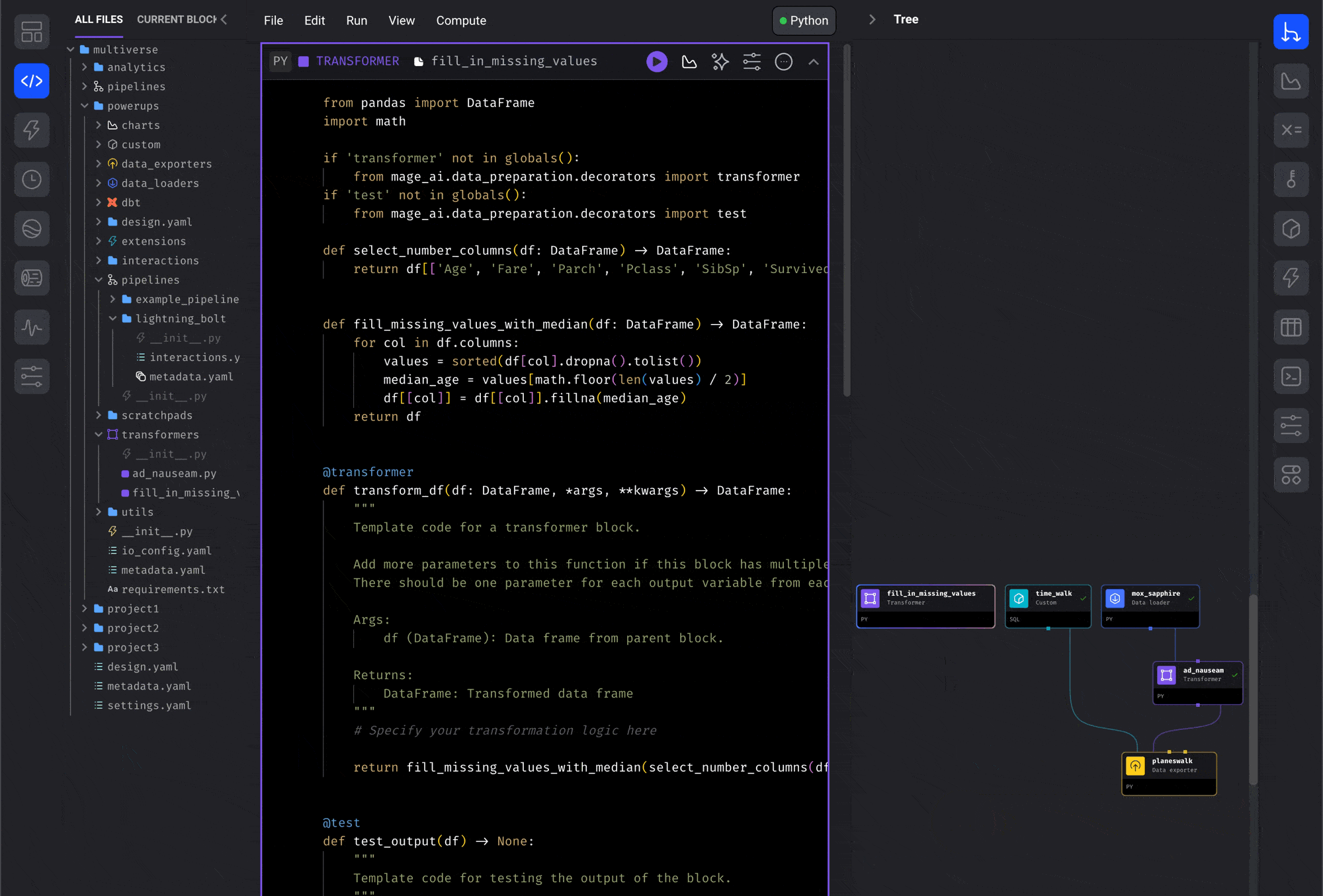
blocks from the file browser.- Open the file browser on the Pipeline Editor page.
- Click a block file and keep holding down.
- Drag the block file onto the center of the page (the Notebook area).
- Release the button and it’ll be added to the pipeline.
Search blocks across entire projects
Search blocks across entire projects
Find existing code and add it to the current pipeline.Instead of clicking a button to add a new block, type in the search bar to find an
existing block across all your projects.
You must first enable the feature named Add new block v2 in your
project settings.
This feature is available in standard (batch) pipelines.If you just recently enabled the feature Add new block v2, you must restart Mage
so that your blocks can be indexed.Version 0.9.64 or greater is required to add
callback and conditional
blocks from the block search.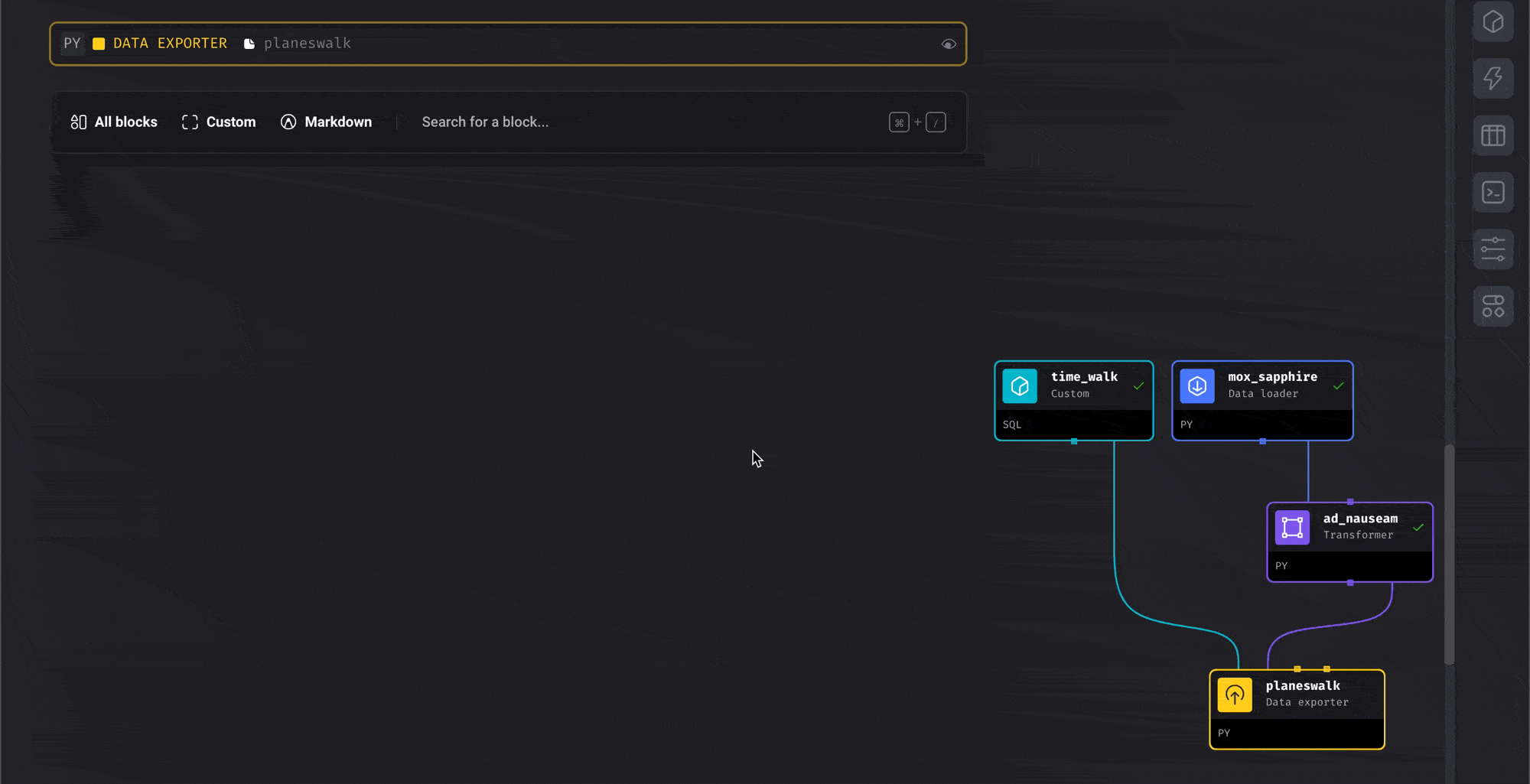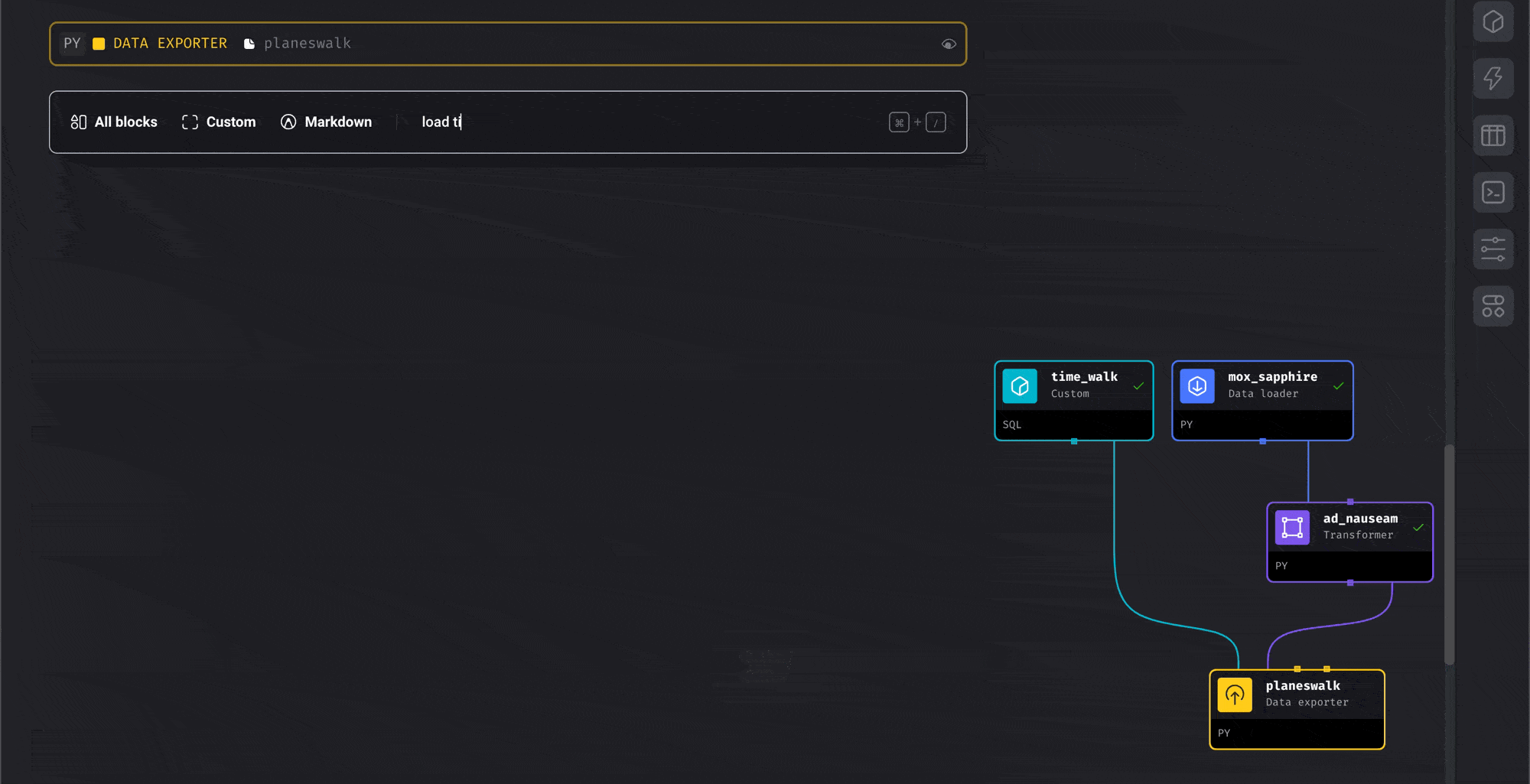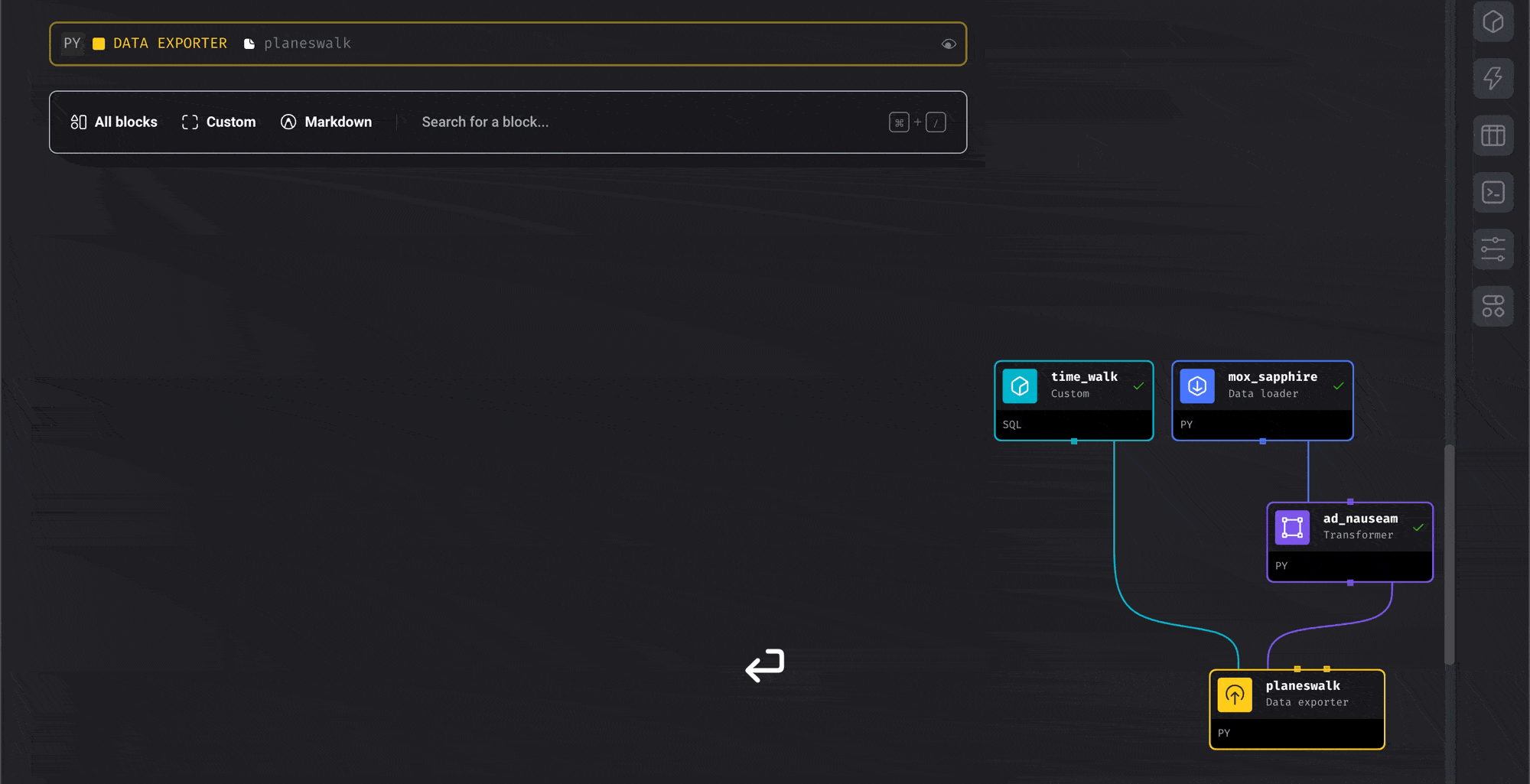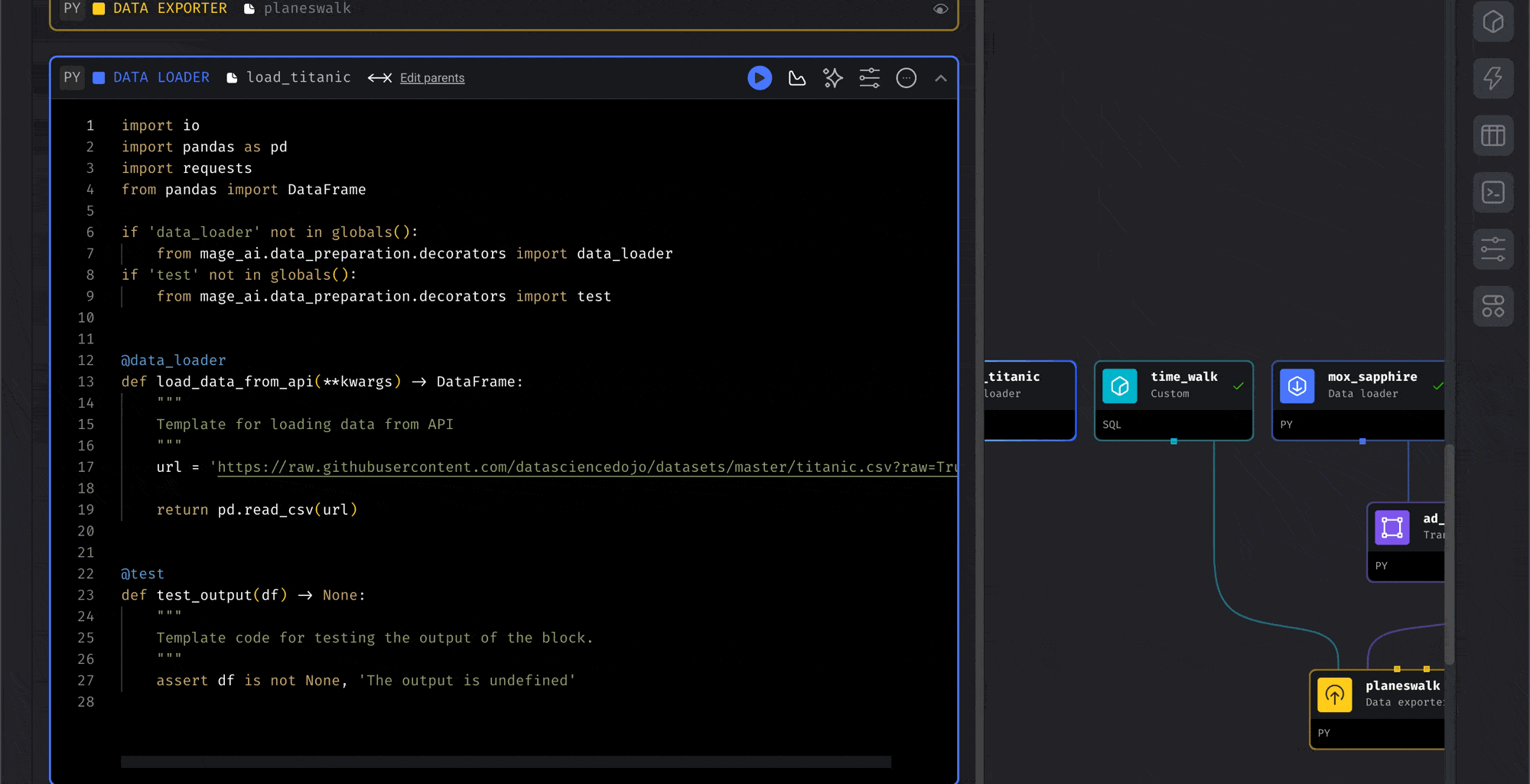
Custom code templates for reducing boilerplate work
Custom code templates for reducing boilerplate work
Create a template for a block or a pipeline that can be reused throughout your project.Read more here
Notes on editing pipelines
Tips to stay safe:- Edit a pipeline in one tab only.
- If you need to monitor the pipeline elsewhere, use another tab in read-only mode.
- Close extra editing tabs if opened by mistake.
Collaboration best practices
If multiple users need to develop the same pipeline:- Use Workspace mode in Mage Pro, which provides:
- Isolated environments per user or team.
- Safe collaboration without overwriting each other’s changes.
- The ability to merge updates back into shared pipelines.
Re-arrange and hide or show blocks
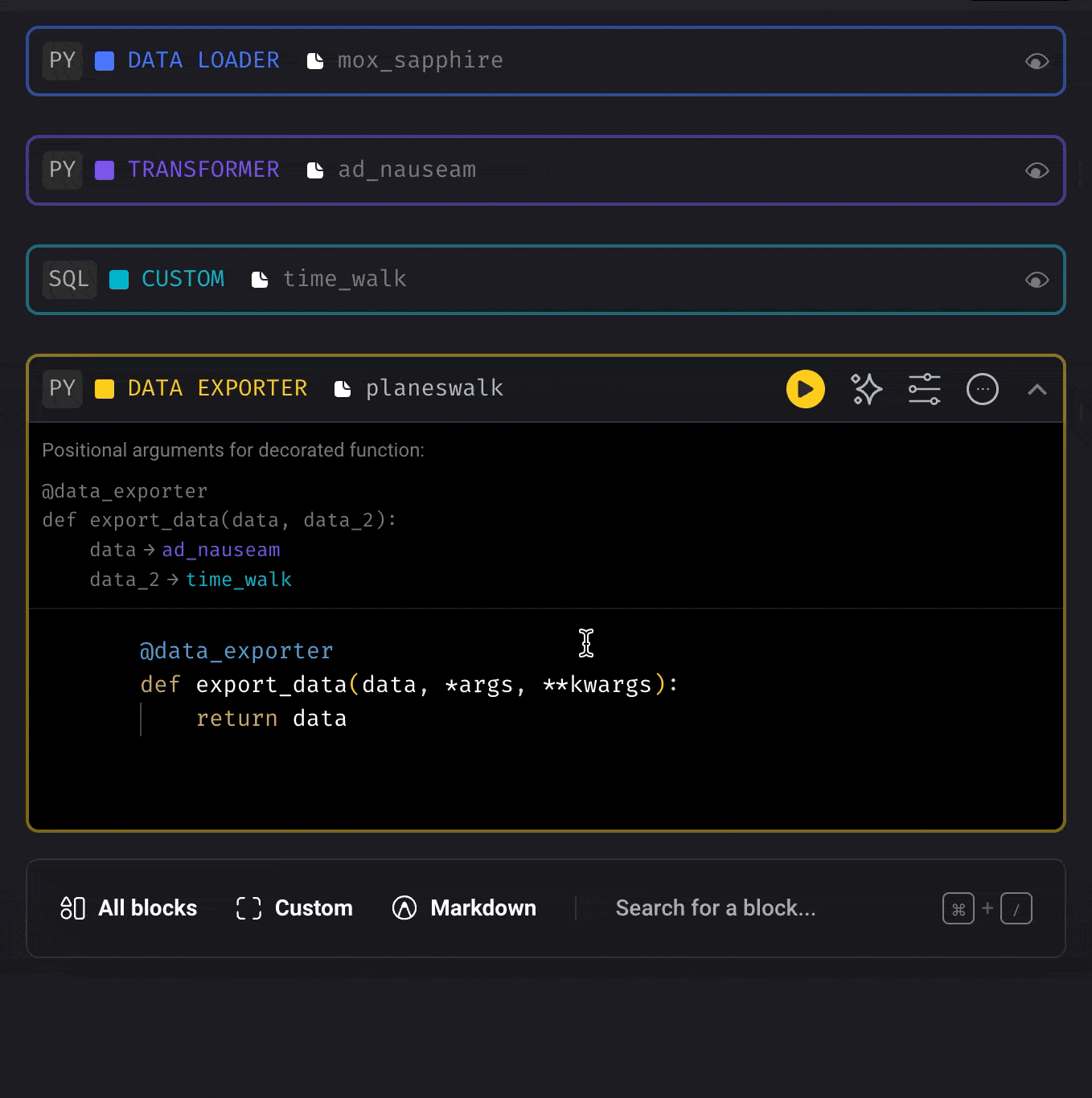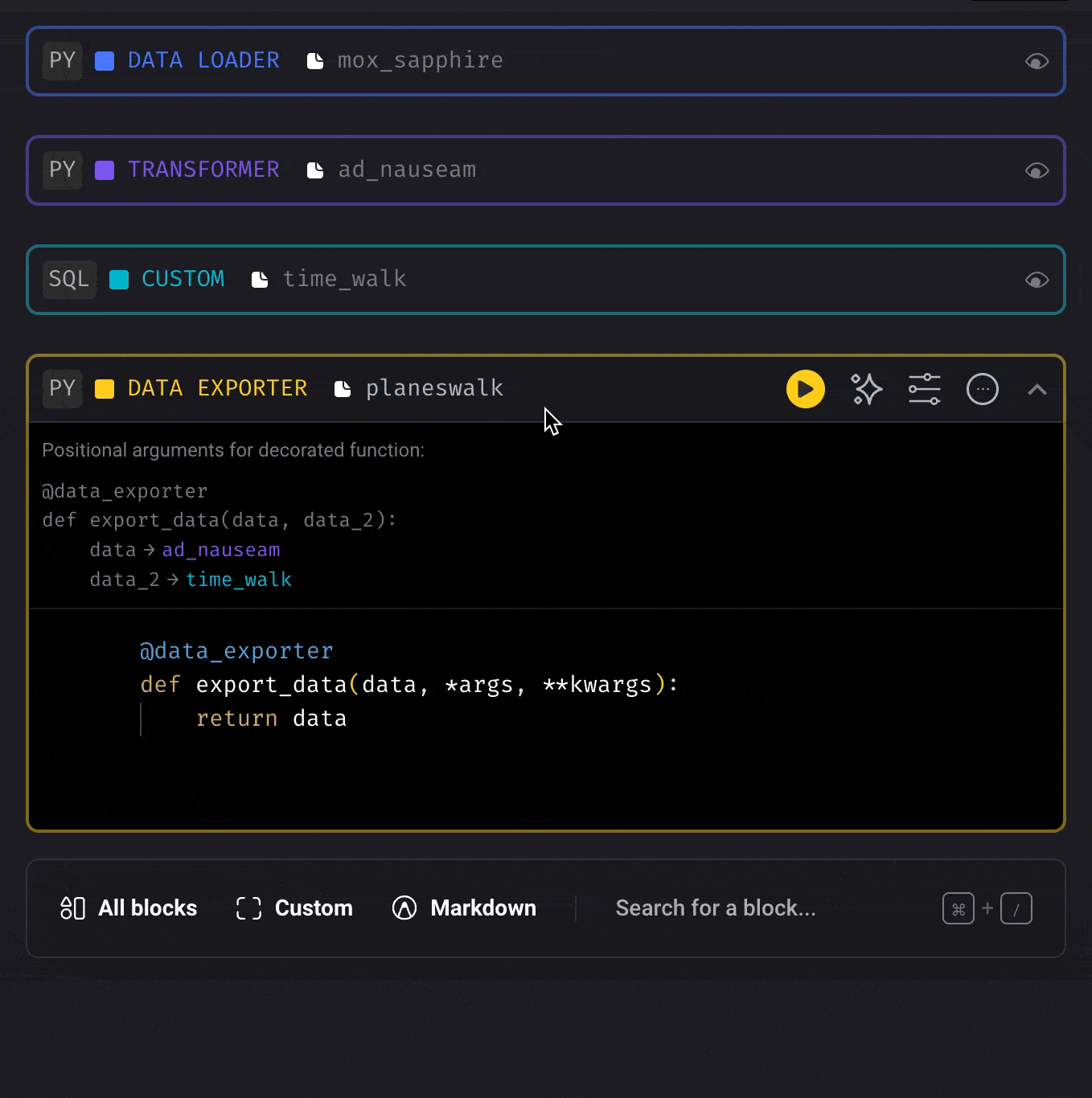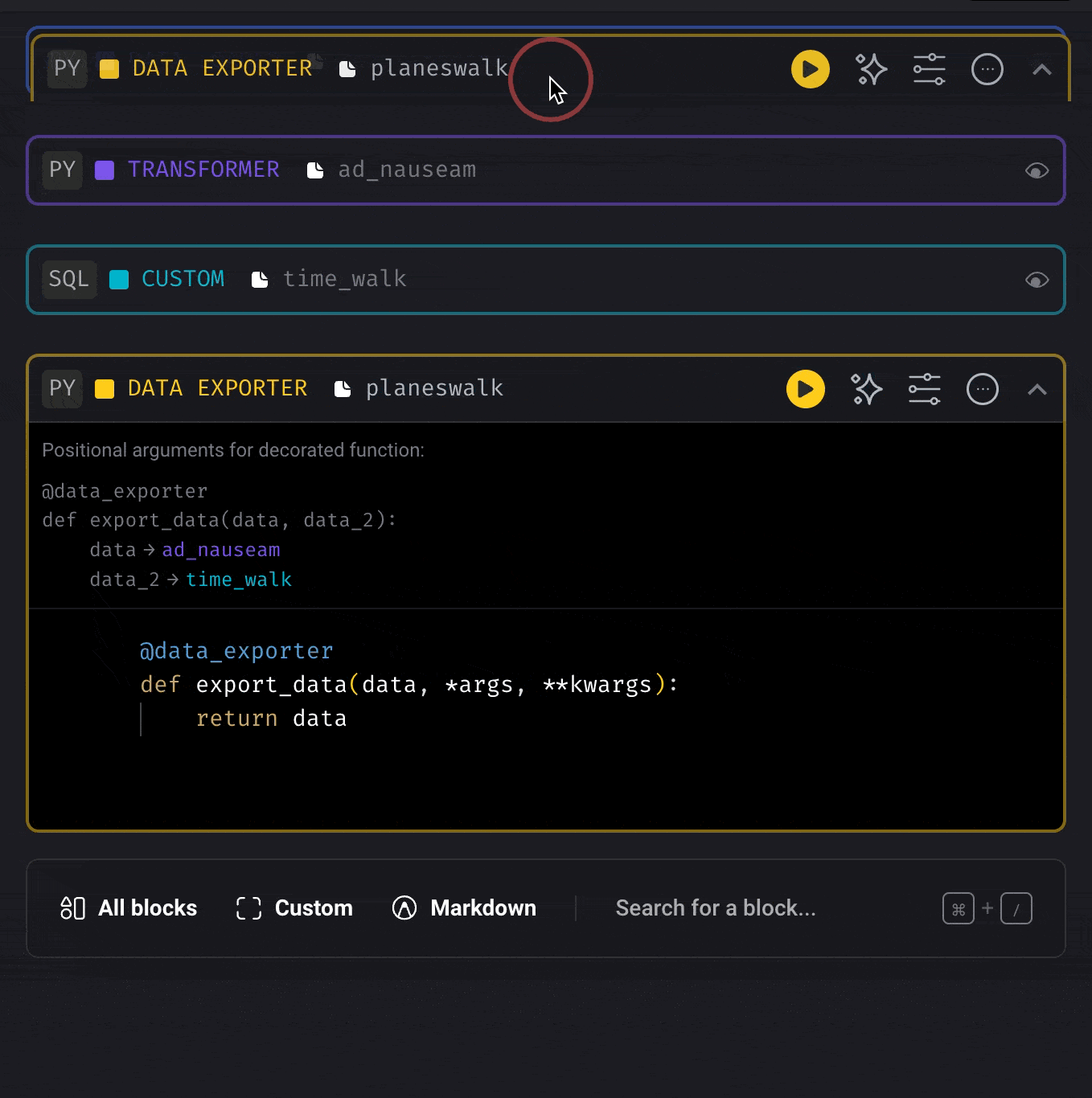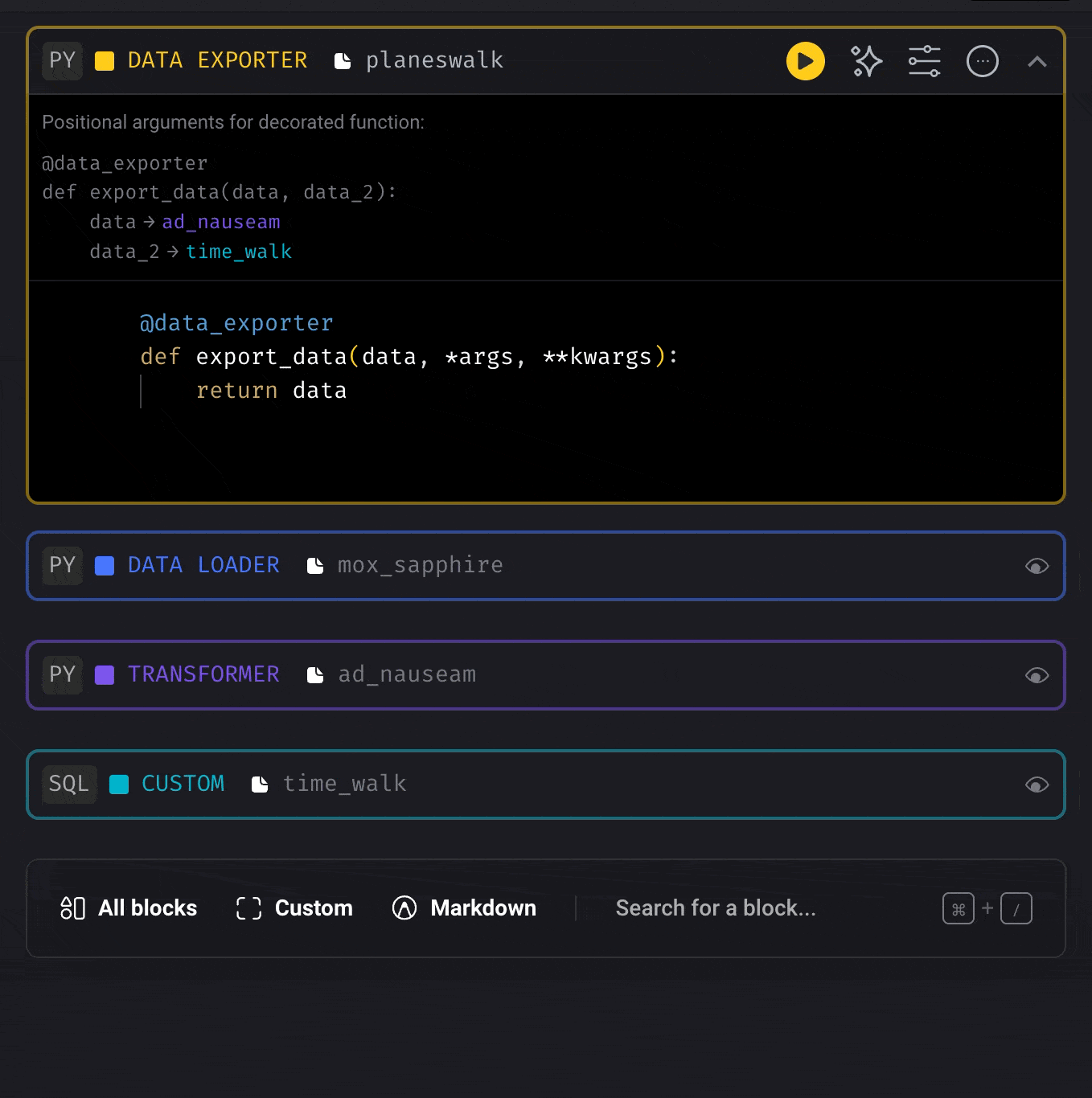
Re-arrange the order of blocks
Re-arrange the order of blocks
Drag a block and move it up or down by dropping it on another block.
Filter files to the current pipeline
Filter files to the current pipeline
When editing a pipeline, open the Files tab and use the selector above the search box
to switch between All Files and This pipeline only. The
This pipeline only filter shows repo-backed files related to the current pipeline,
including pipeline metadata and configuration files, trigger configuration, referenced block
source files, and supporting project configuration such as
io_config.yaml,
metadata.yaml, and requirements.txt. Runtime data and log files
are not included.Block visibility tab
Block visibility tab
Use the Visibility tab to hide blocks in the notebook. Hidden blocks are collapsed,
and you can click a hidden block to expand it again. This can help optimize vertical screen
space while writing code.
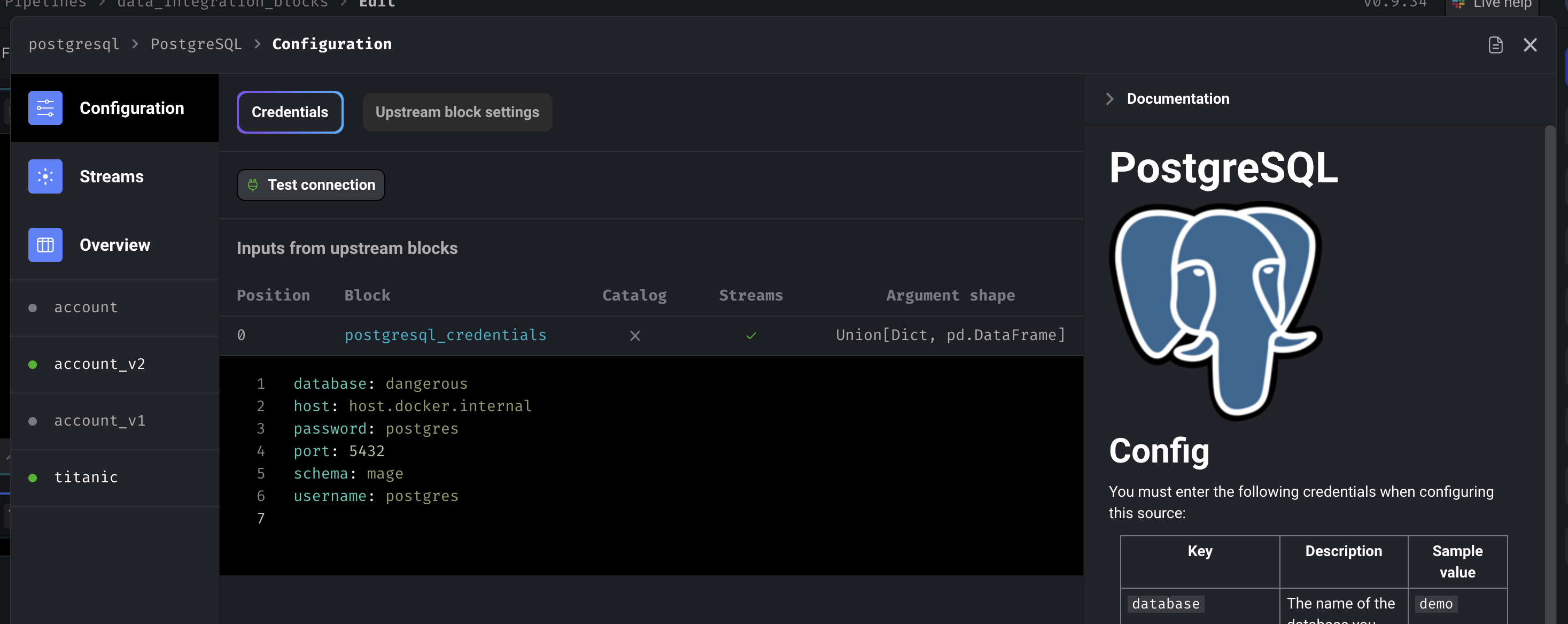
Pre-built data integrations for 3rd party sources
Use AI to write code for you
A line of code you don’t write is a line of code you never have to debug. Use AI to generate the code for you.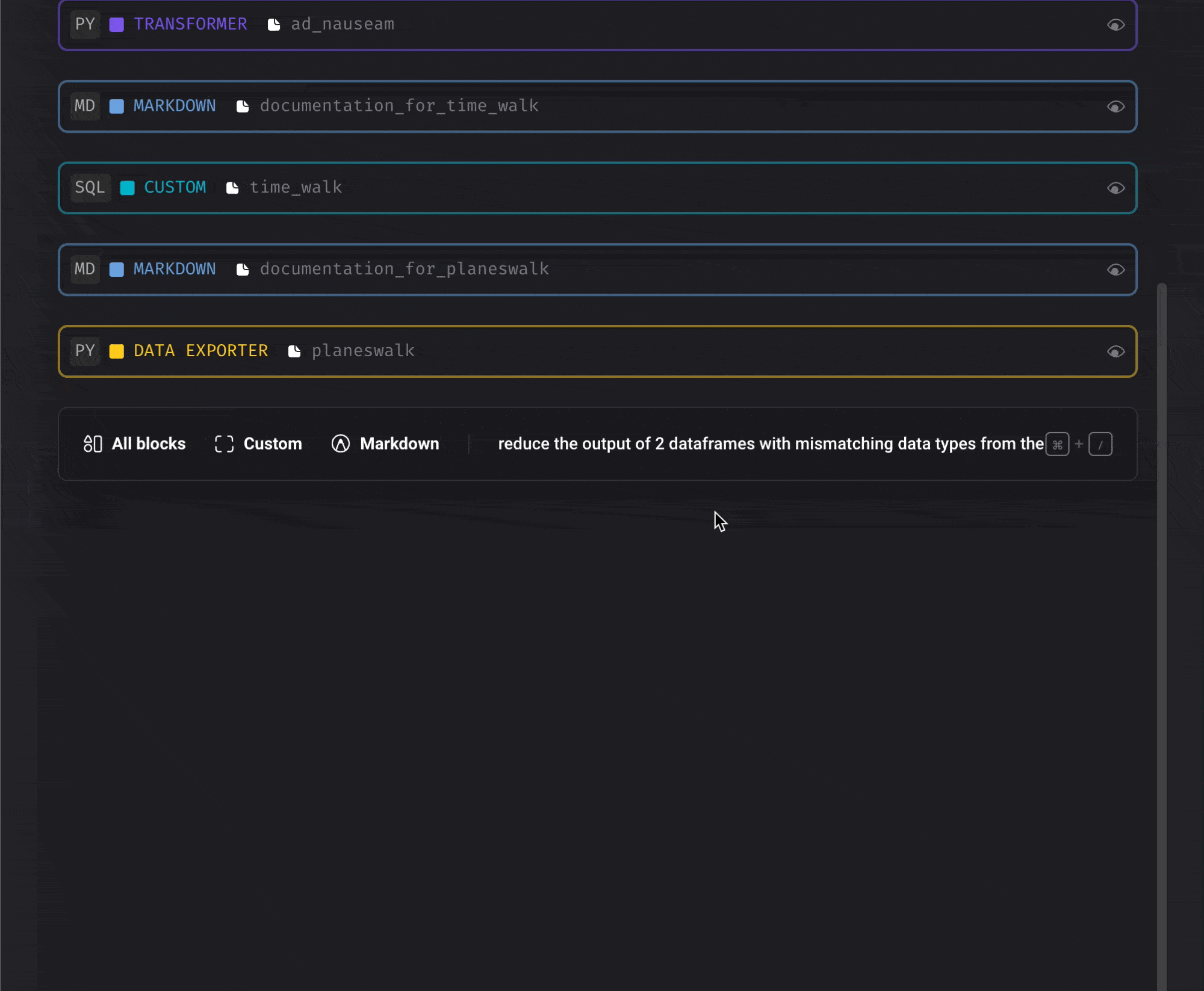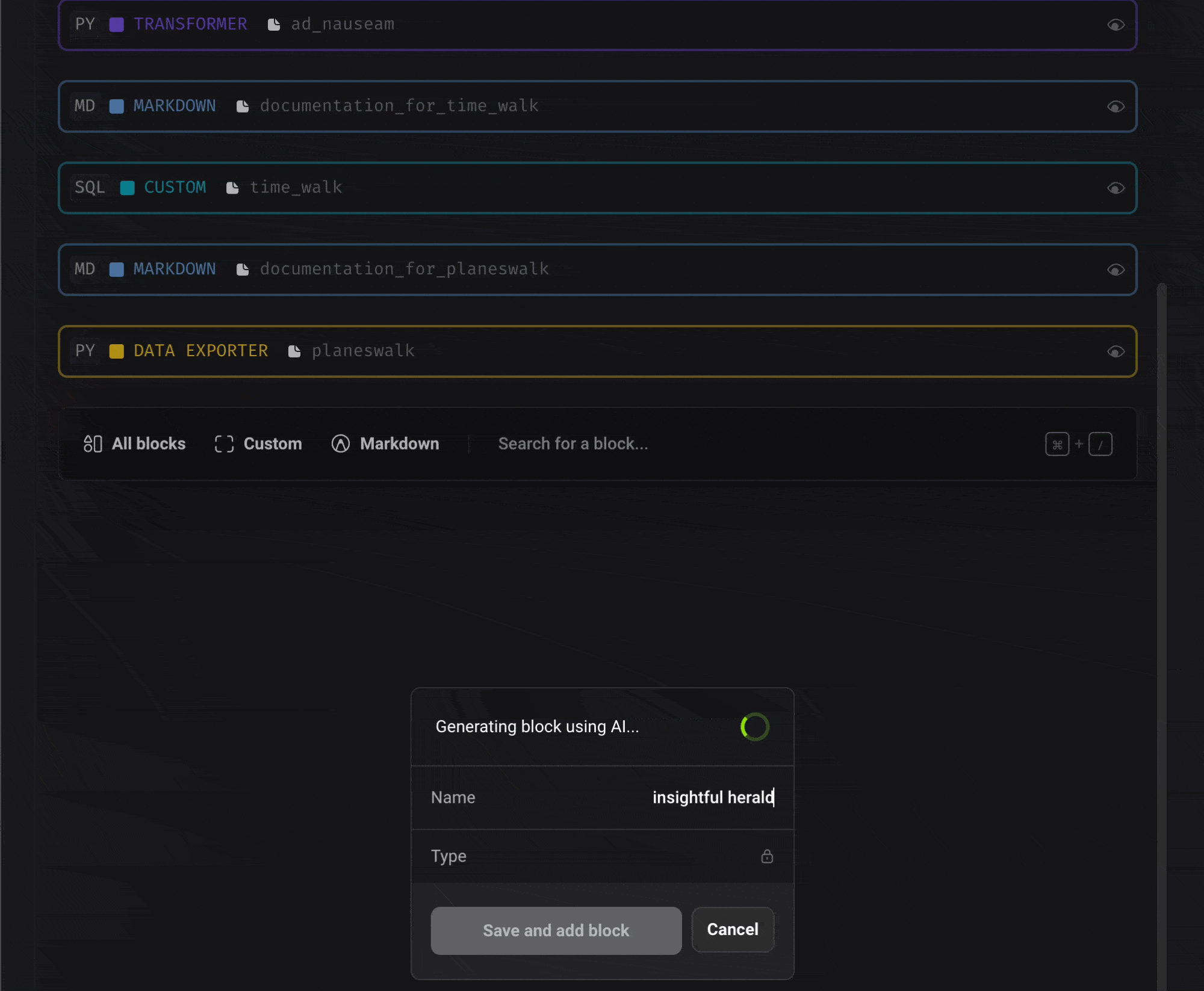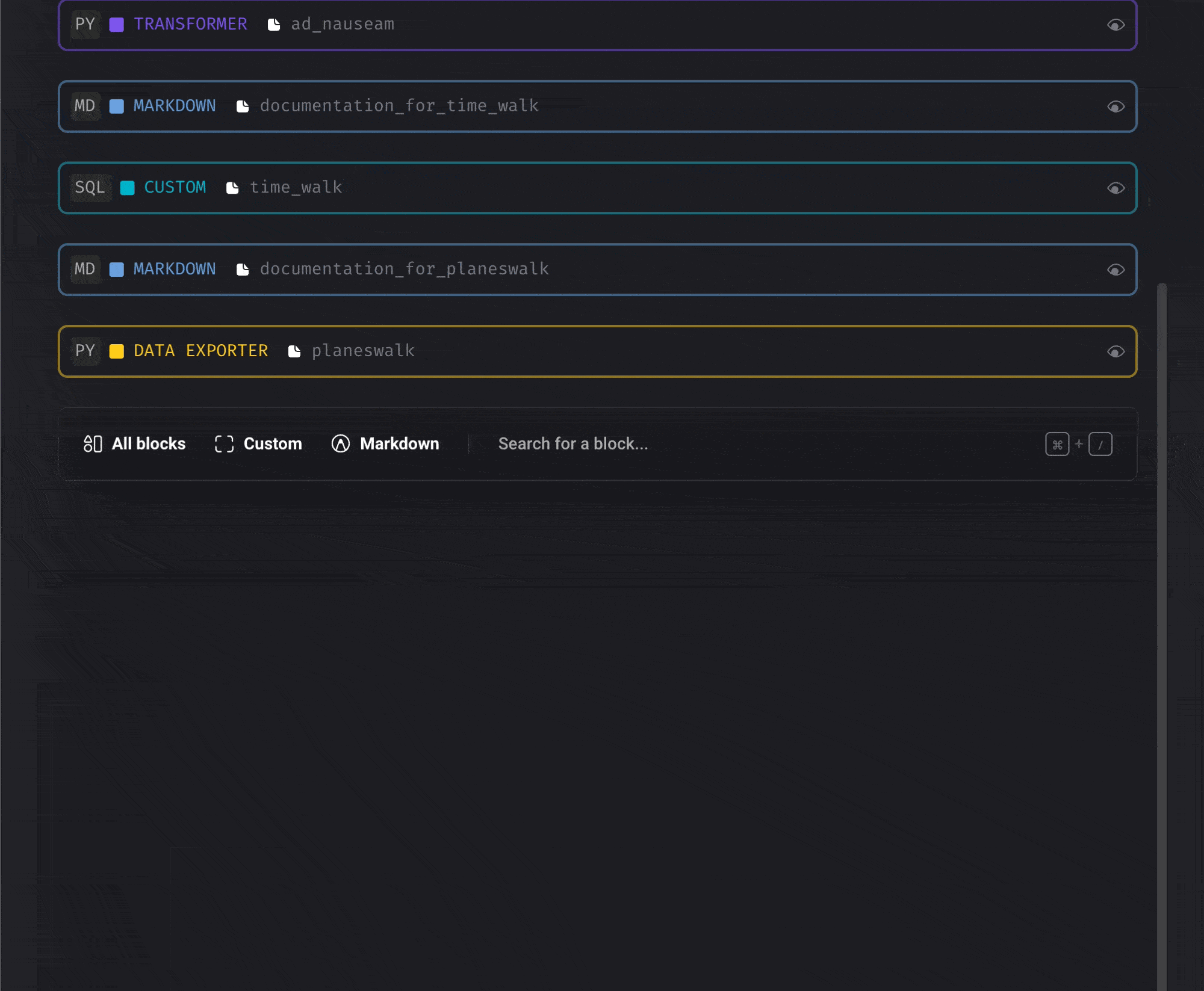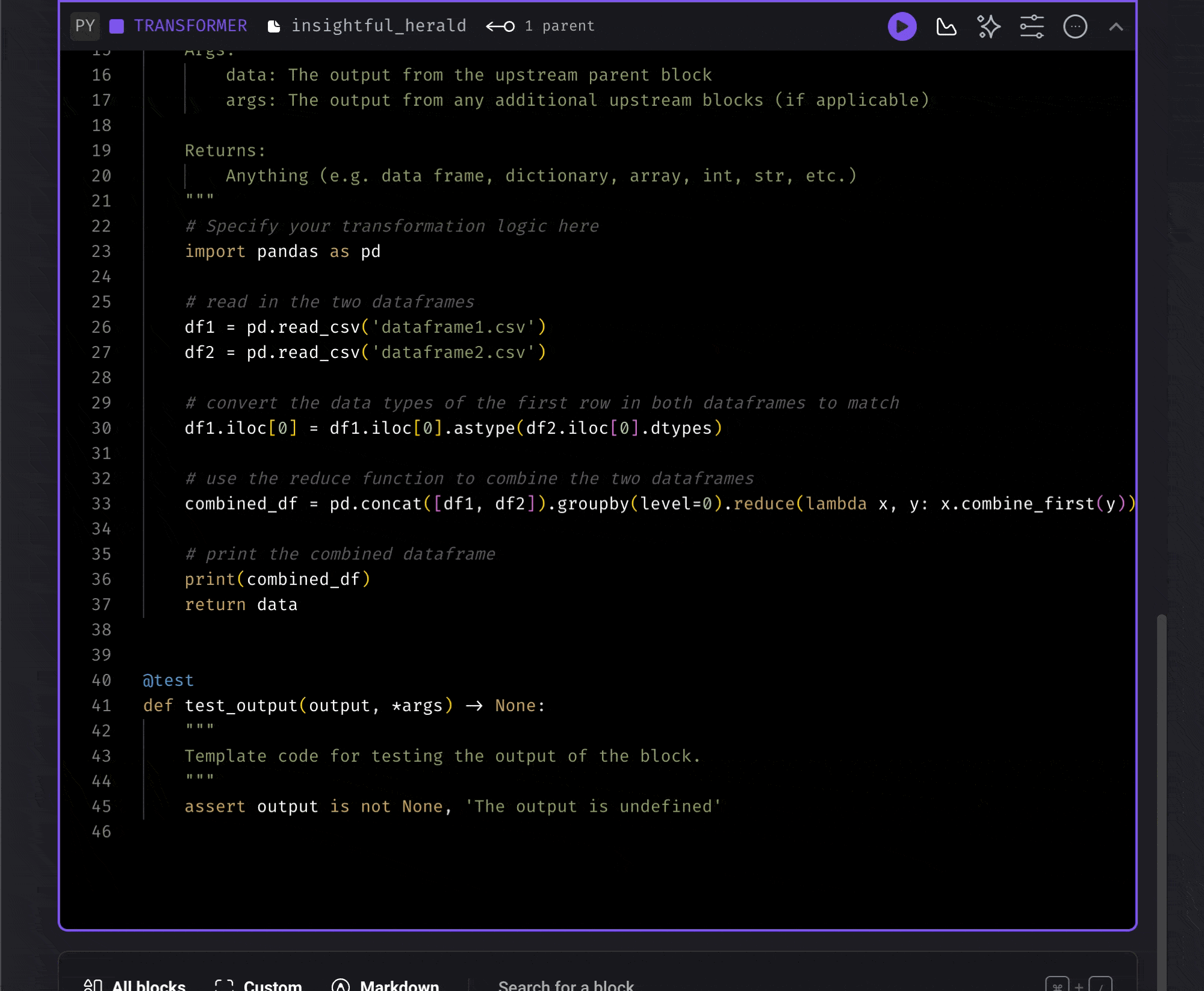
Document and comment code (AI)
“Work smart, not hard.” Let the robots document your code so you can focus on the fun and creative side of coding.Document the code from a block
Document the code from a block
Write comments inline with the code
Write comments inline with the code
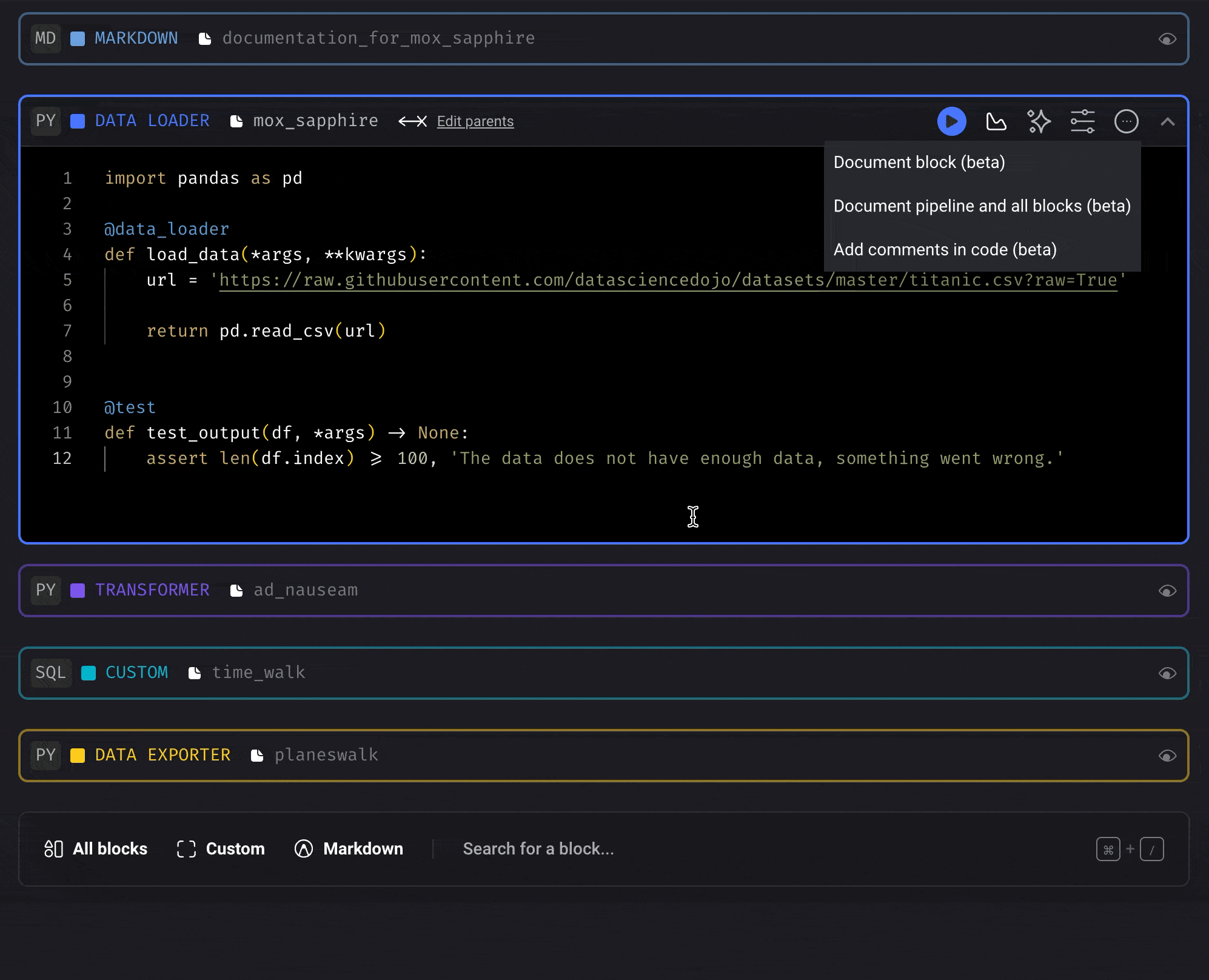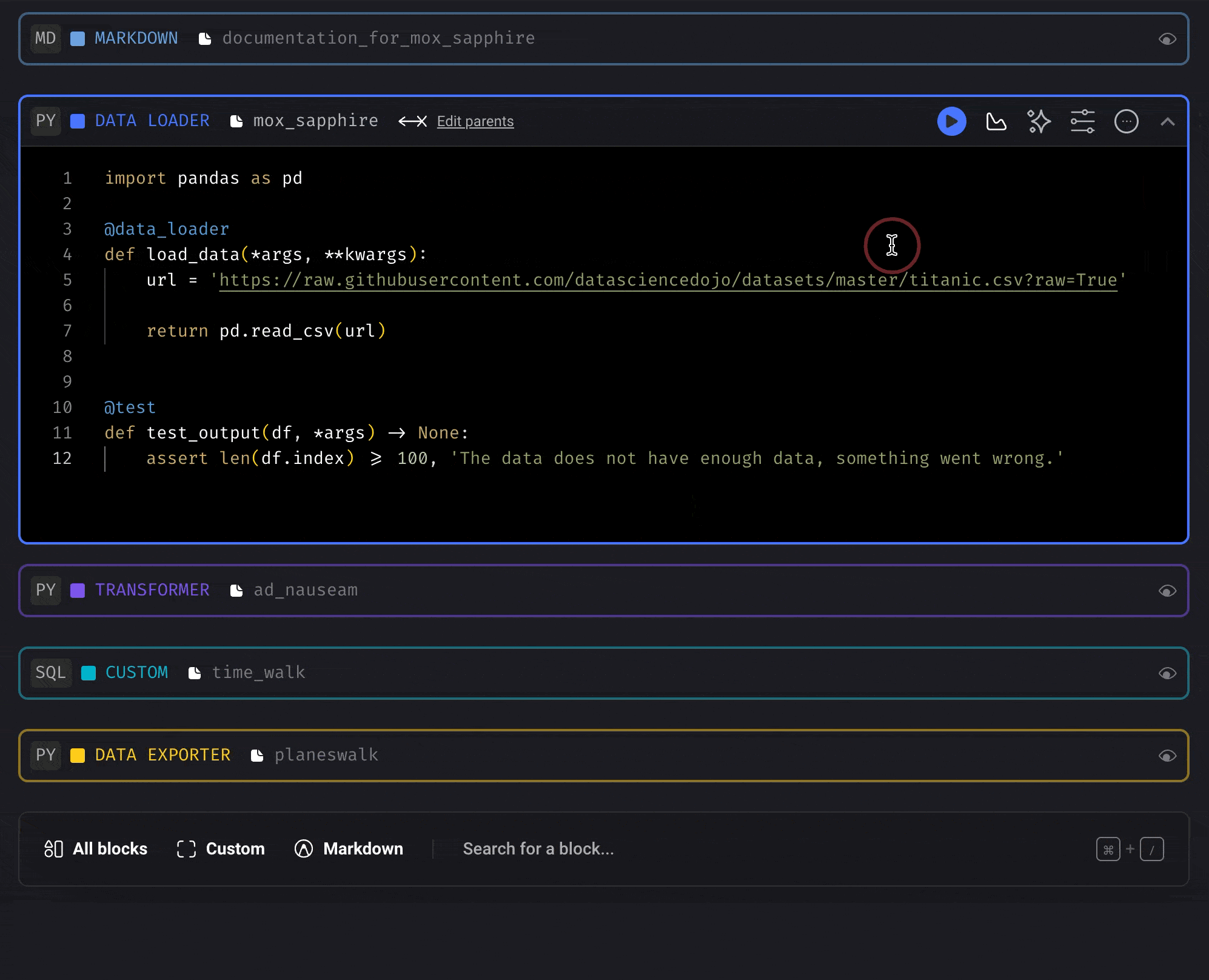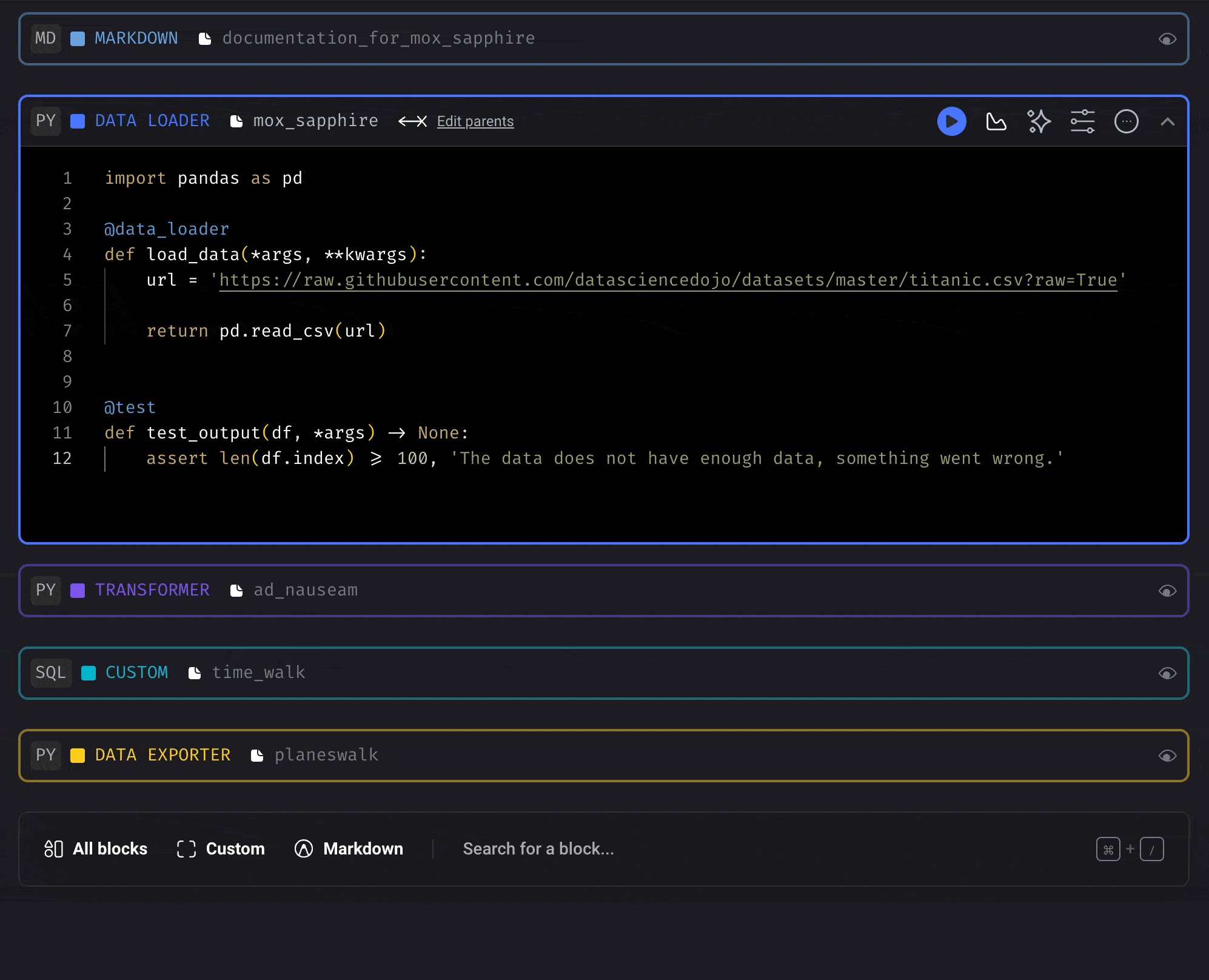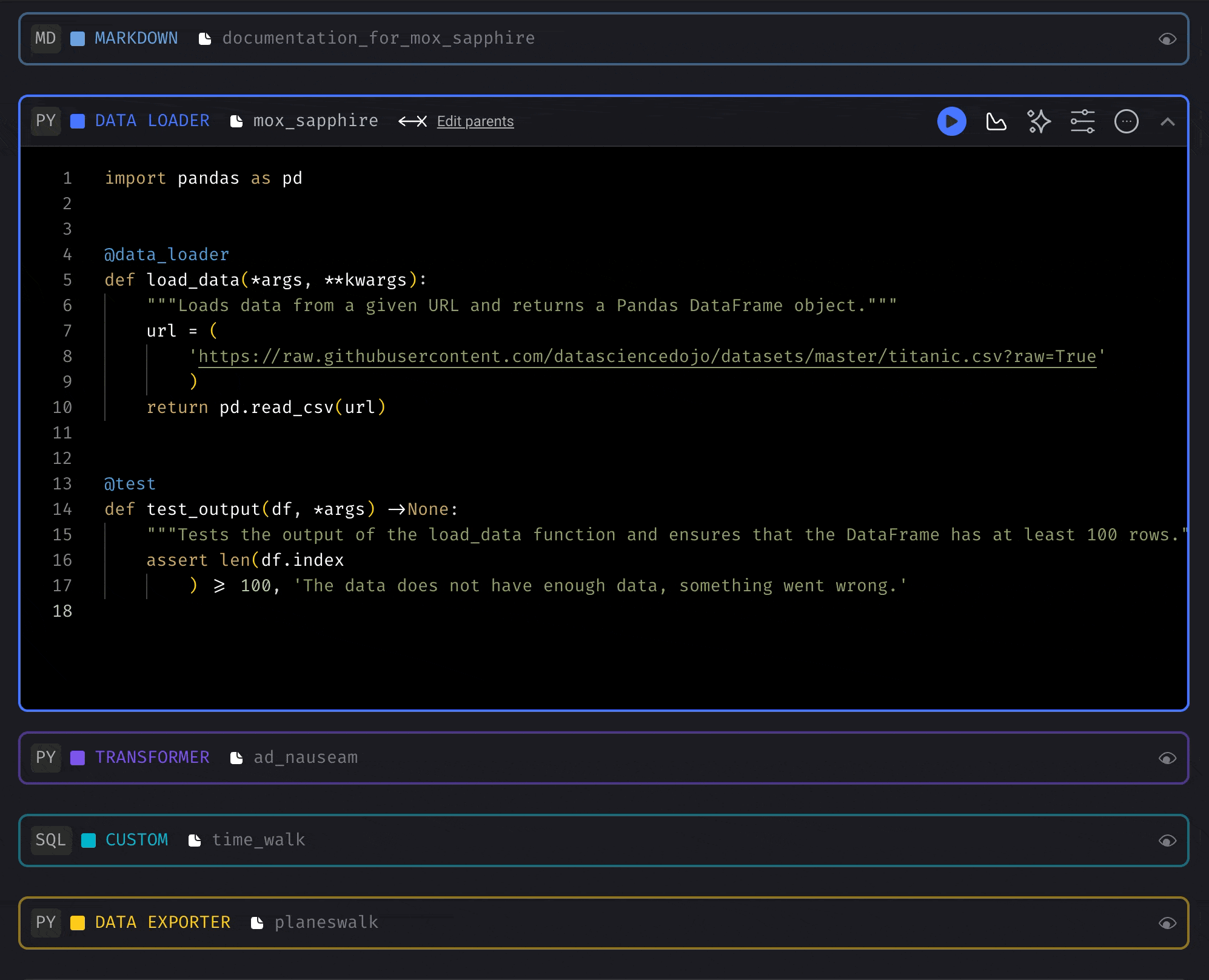
Document the entire pipeline and each block in it
Document the entire pipeline and each block in it
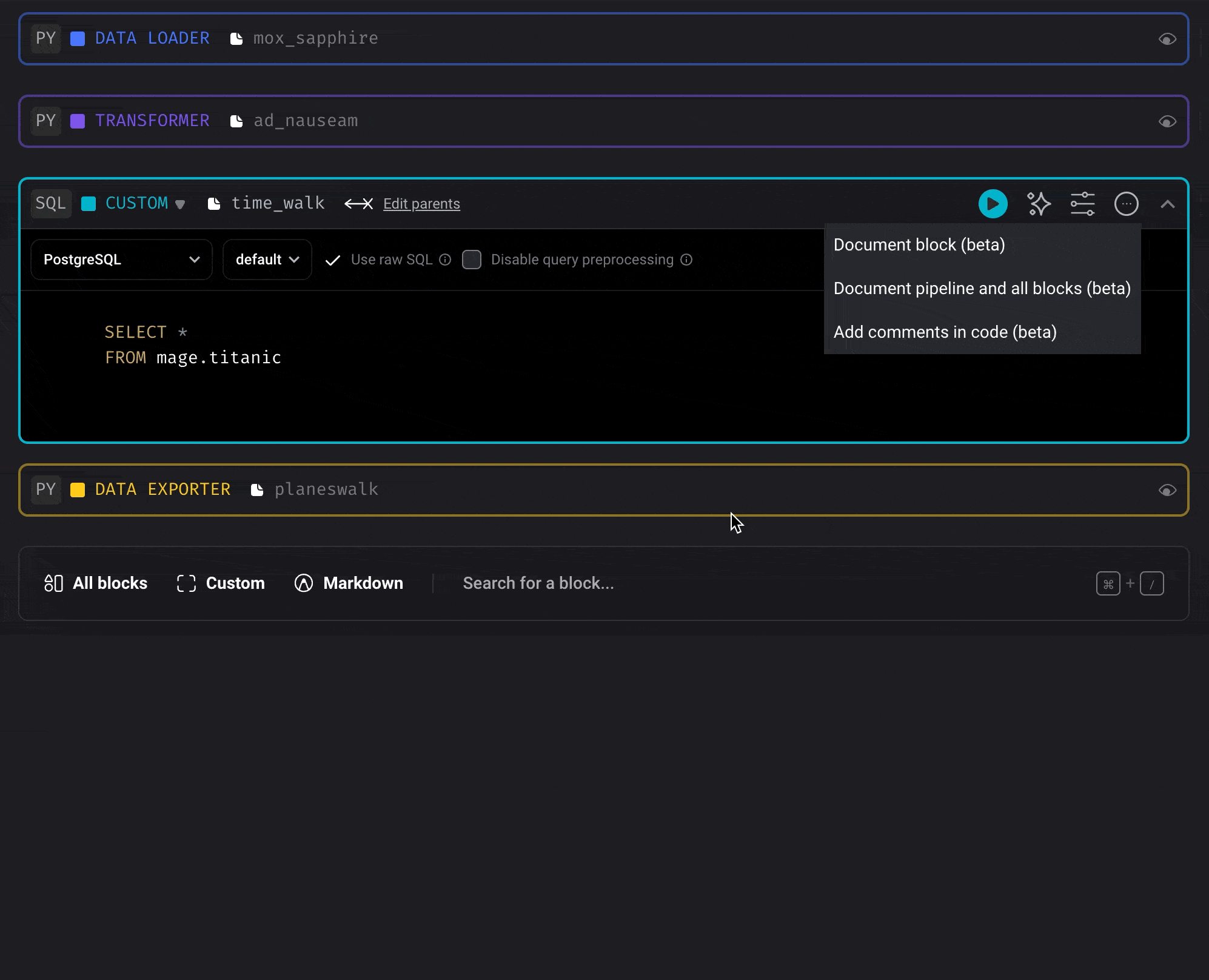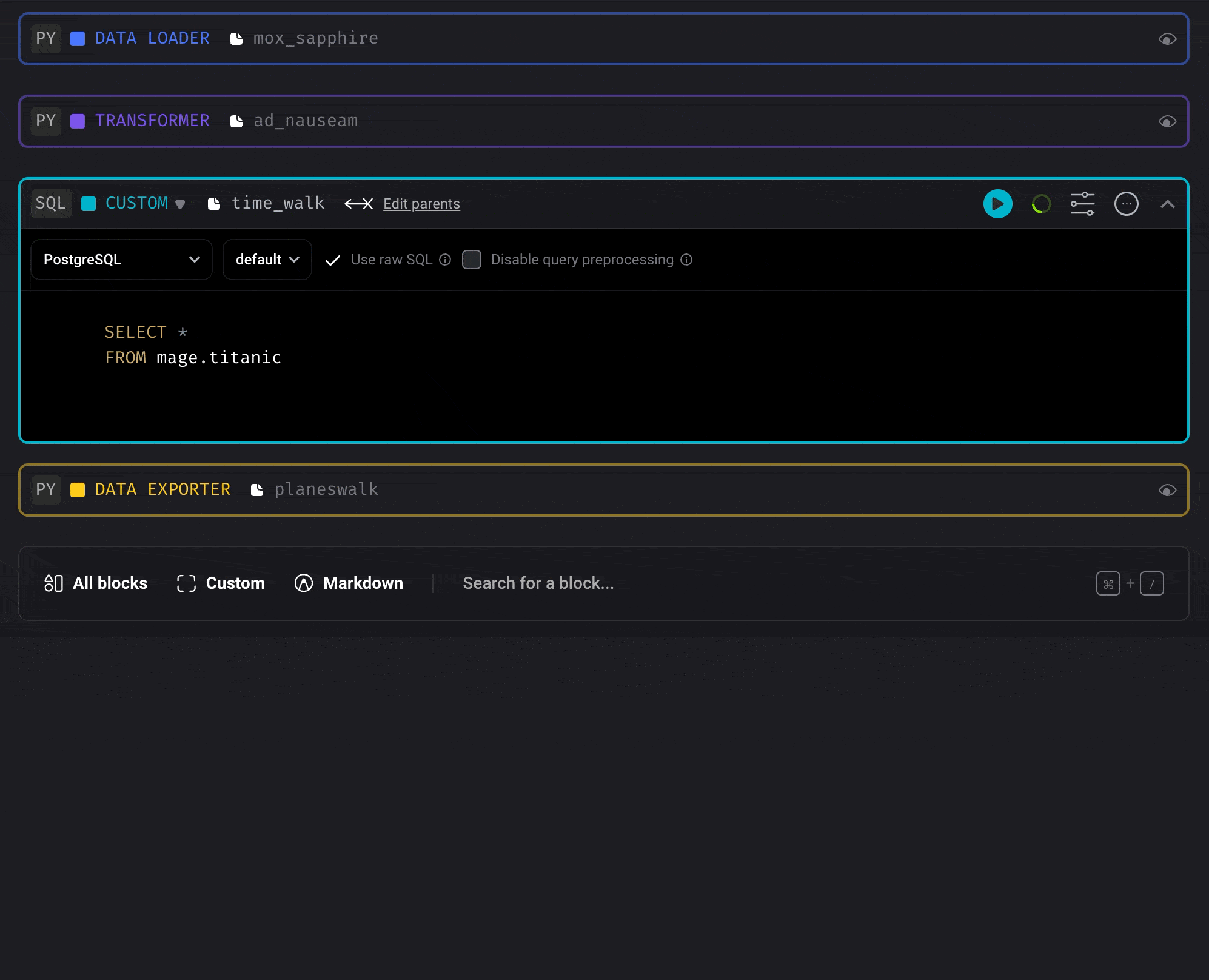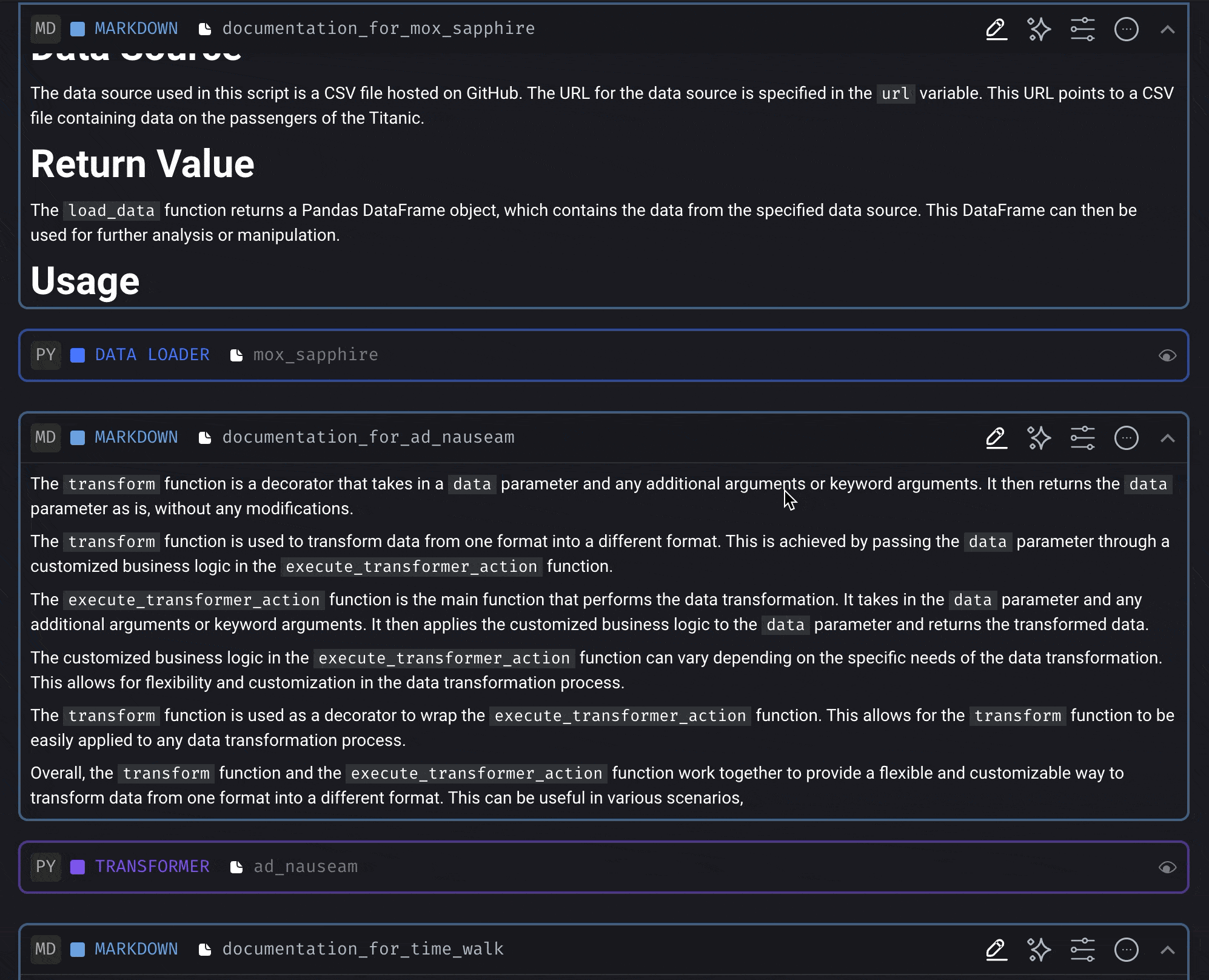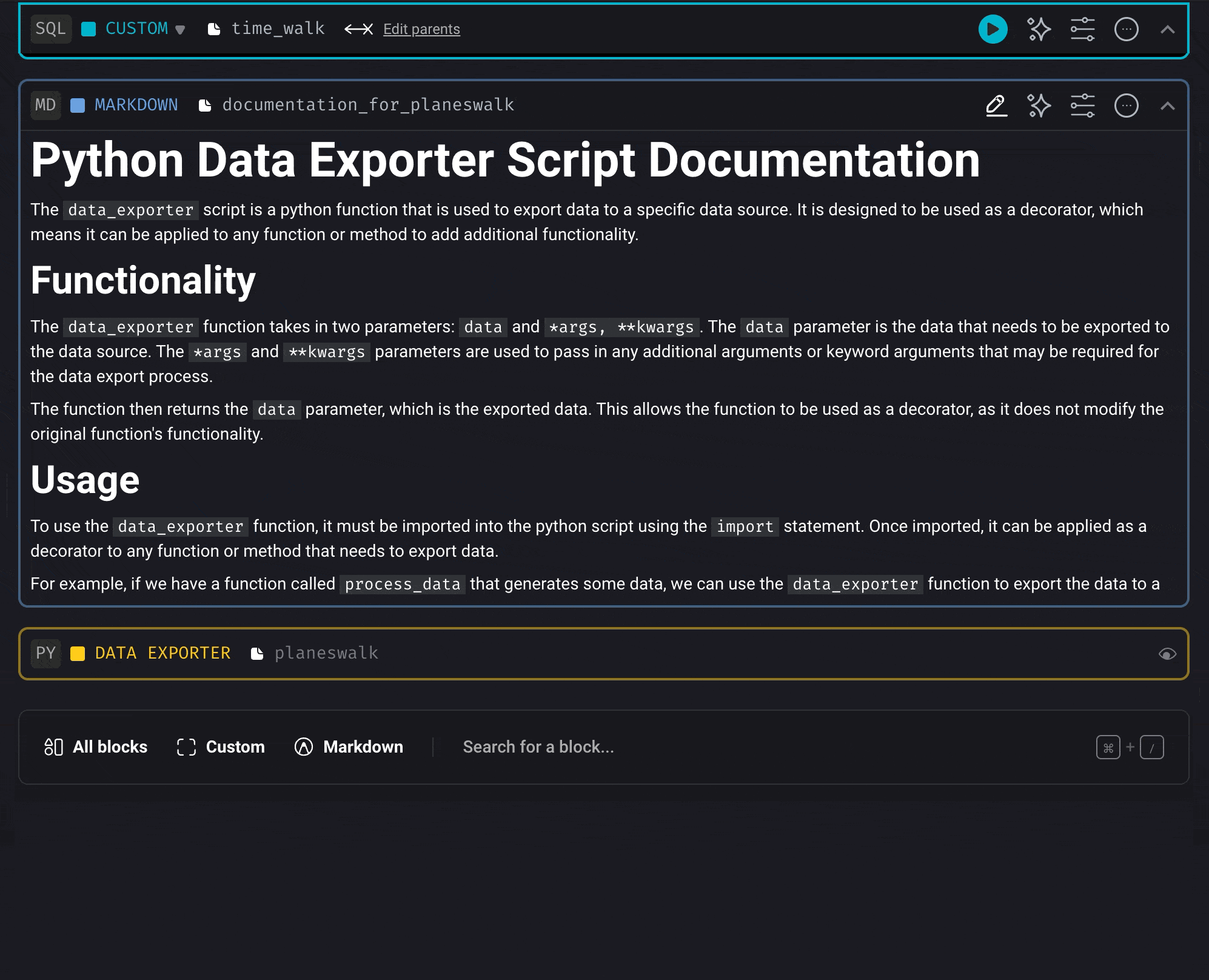
Block upgrades
Enhance your code with these quick power-ups:Recursively dynamic code made simple
Recursively dynamic code made simple
Replicate the code of an existing block
Replicate the code of an existing block
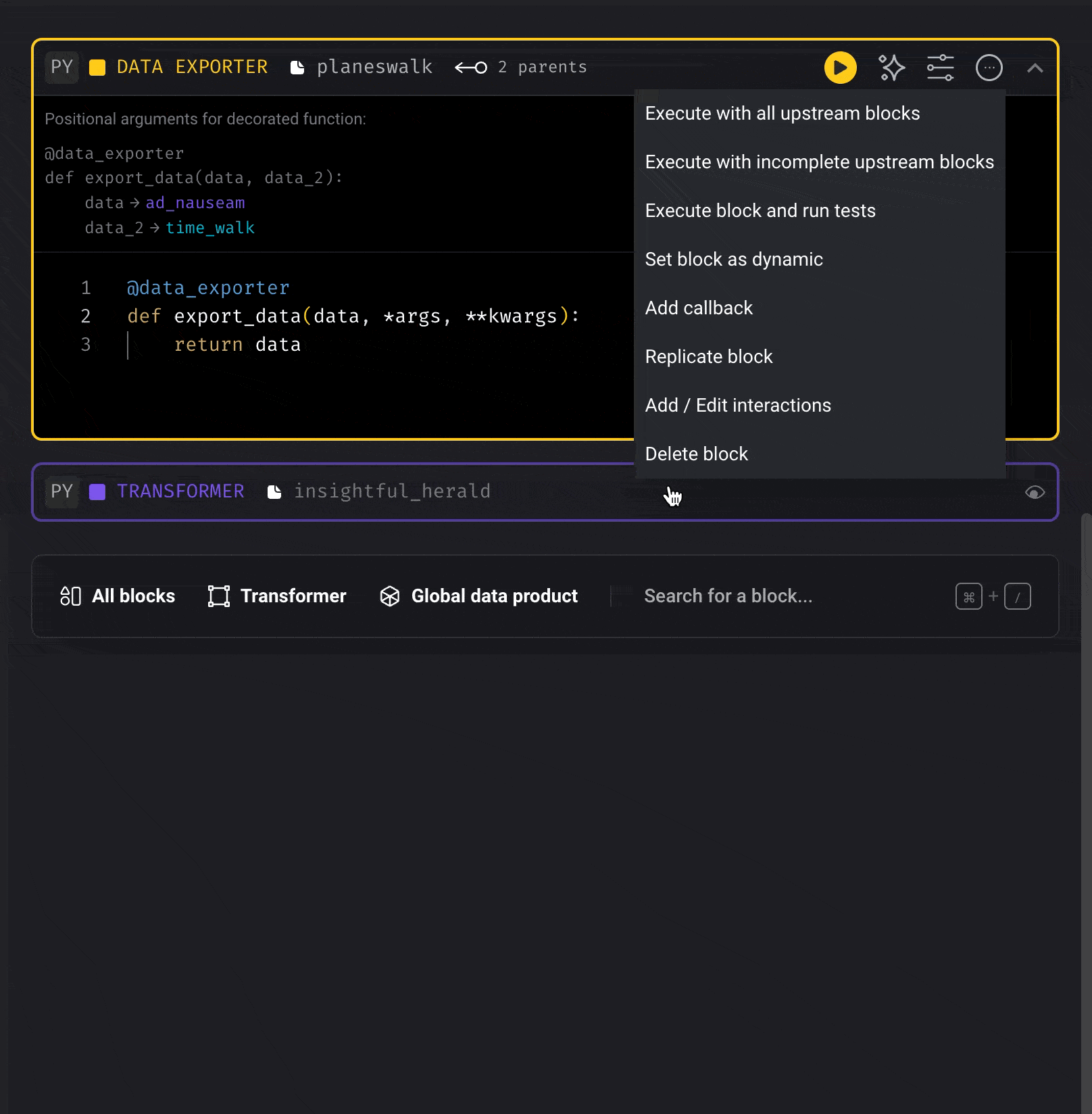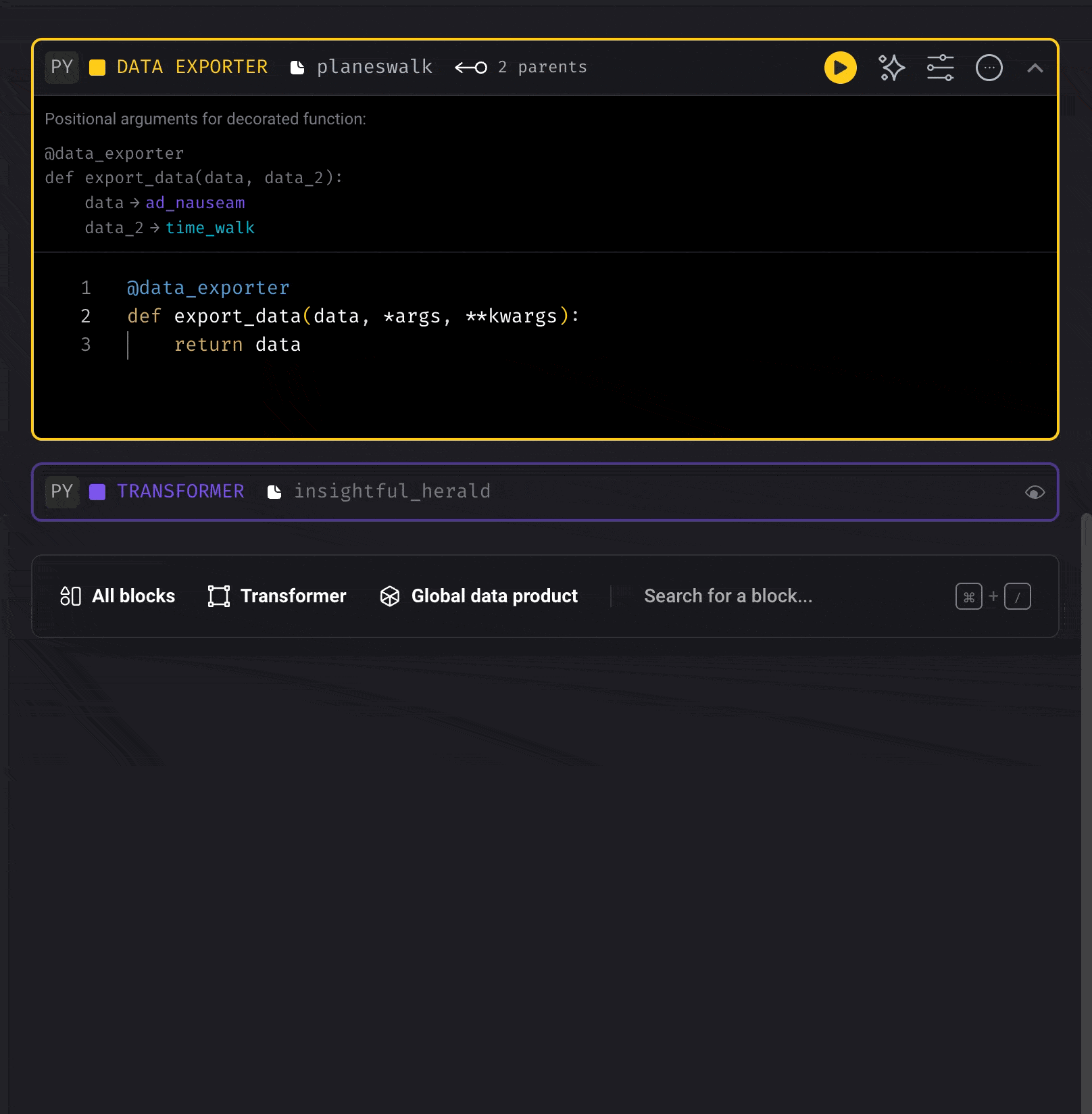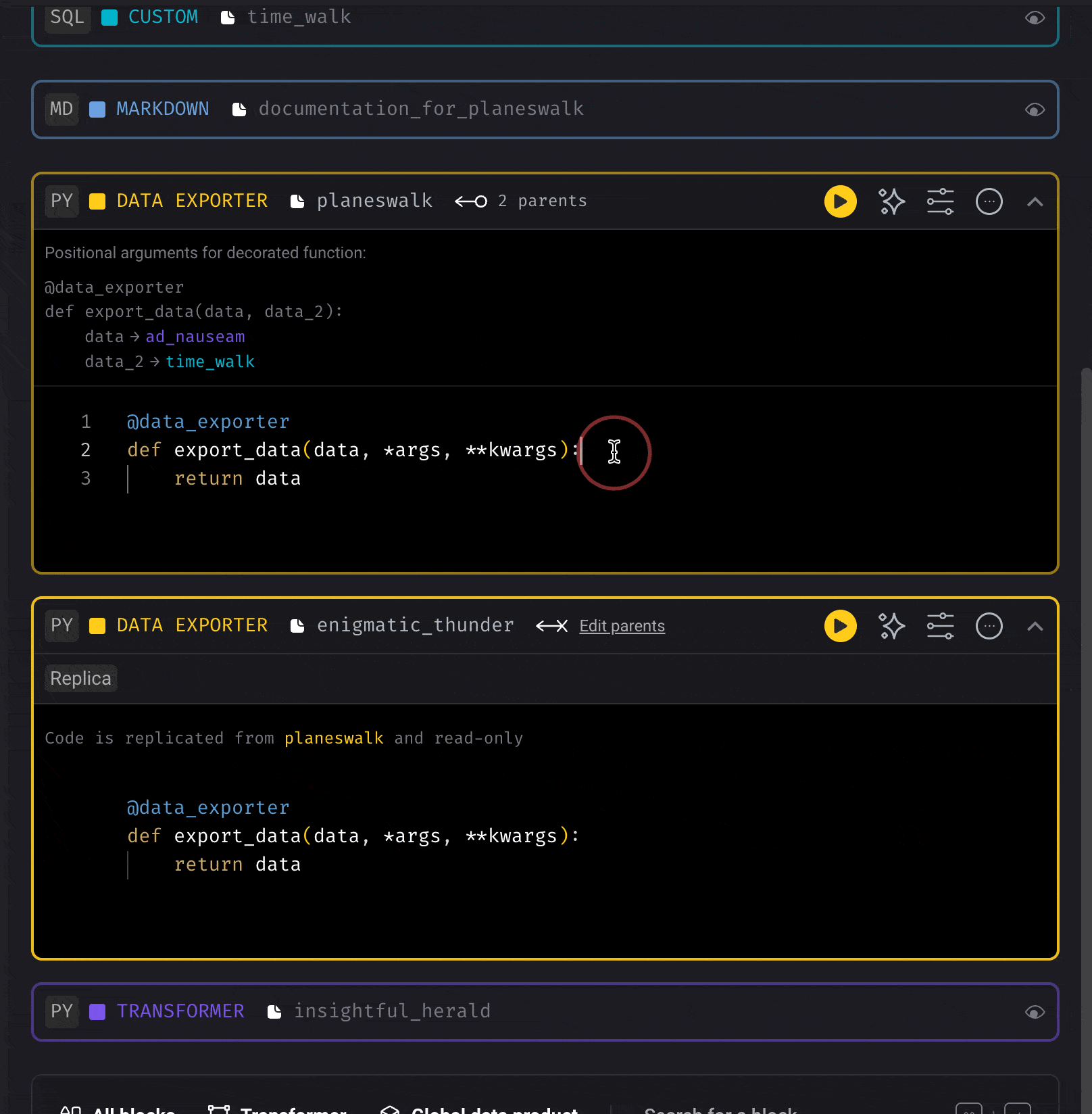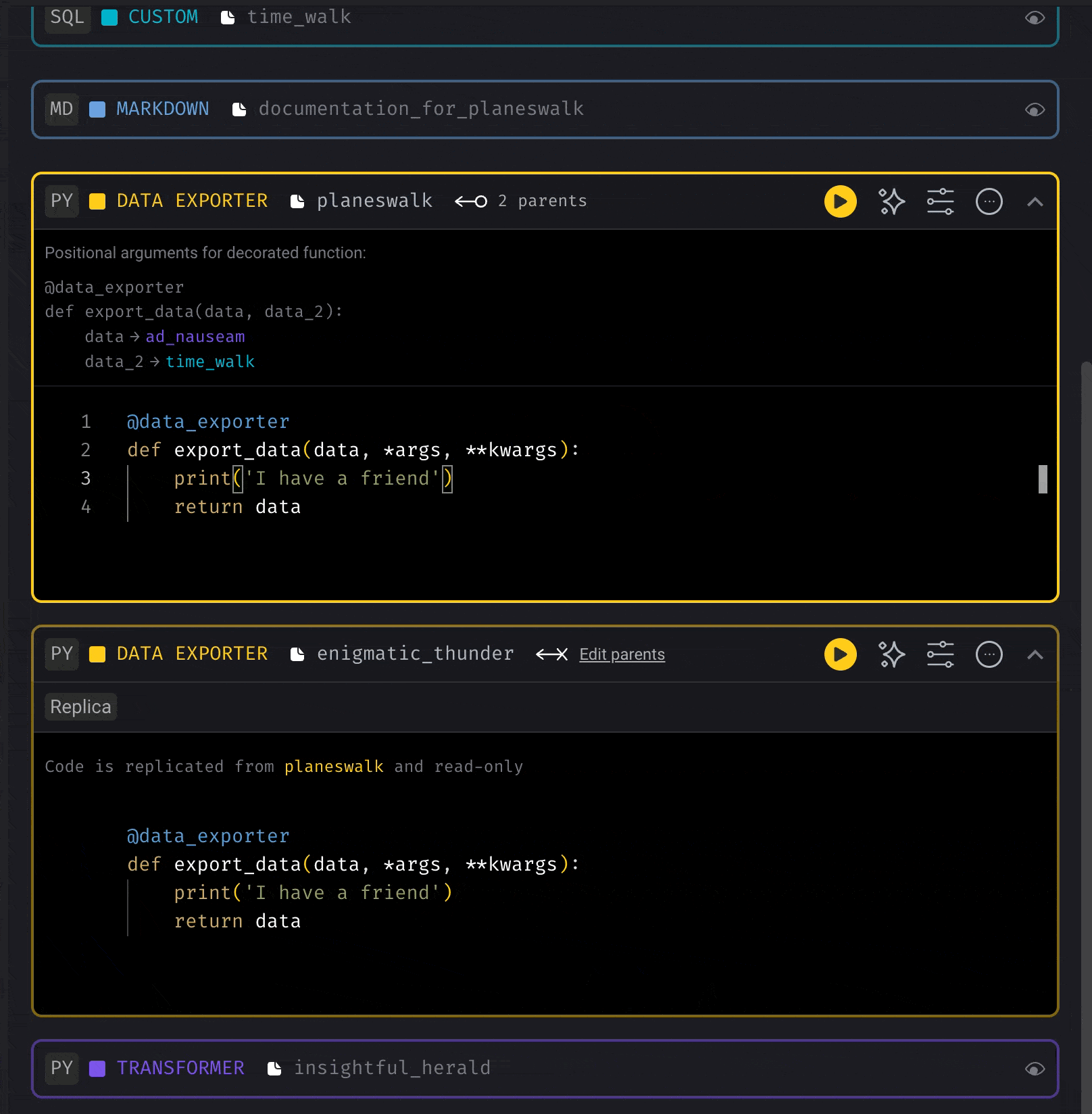
Conditionally execute code
Conditionally execute code
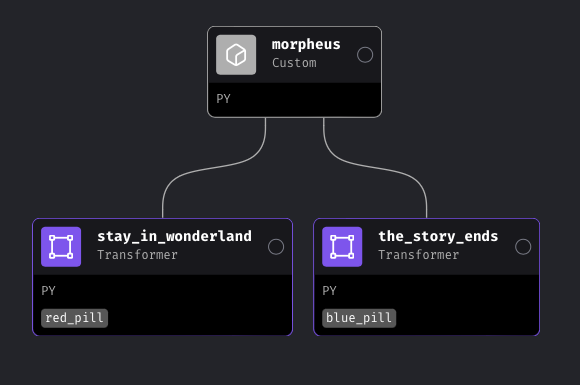
Callbacks
Callbacks
A callback block is associated to another block.
When the parent block succeeds or fails, the callback block functions are executed.Read more here
Add new block v2
An improved experience for adding new blocks to your pipeline in the Pipeline Editor (/pipelines/[pipeline_uuid]/edit), which allows you to
search for existing block files and use data integration blocks inside of
a standard (batch) pipeline.
Code and output side-by-side view
Run code and see its output right next to where you’re writing. This makes it so that you don’t have to keep scrolling down every time you make a code change and want to see its results. For table outputs, click a column header to sort the preview or use the filter icon beside the header to filter rows by column value. These controls are temporary preview tools and don’t change the underlying block output.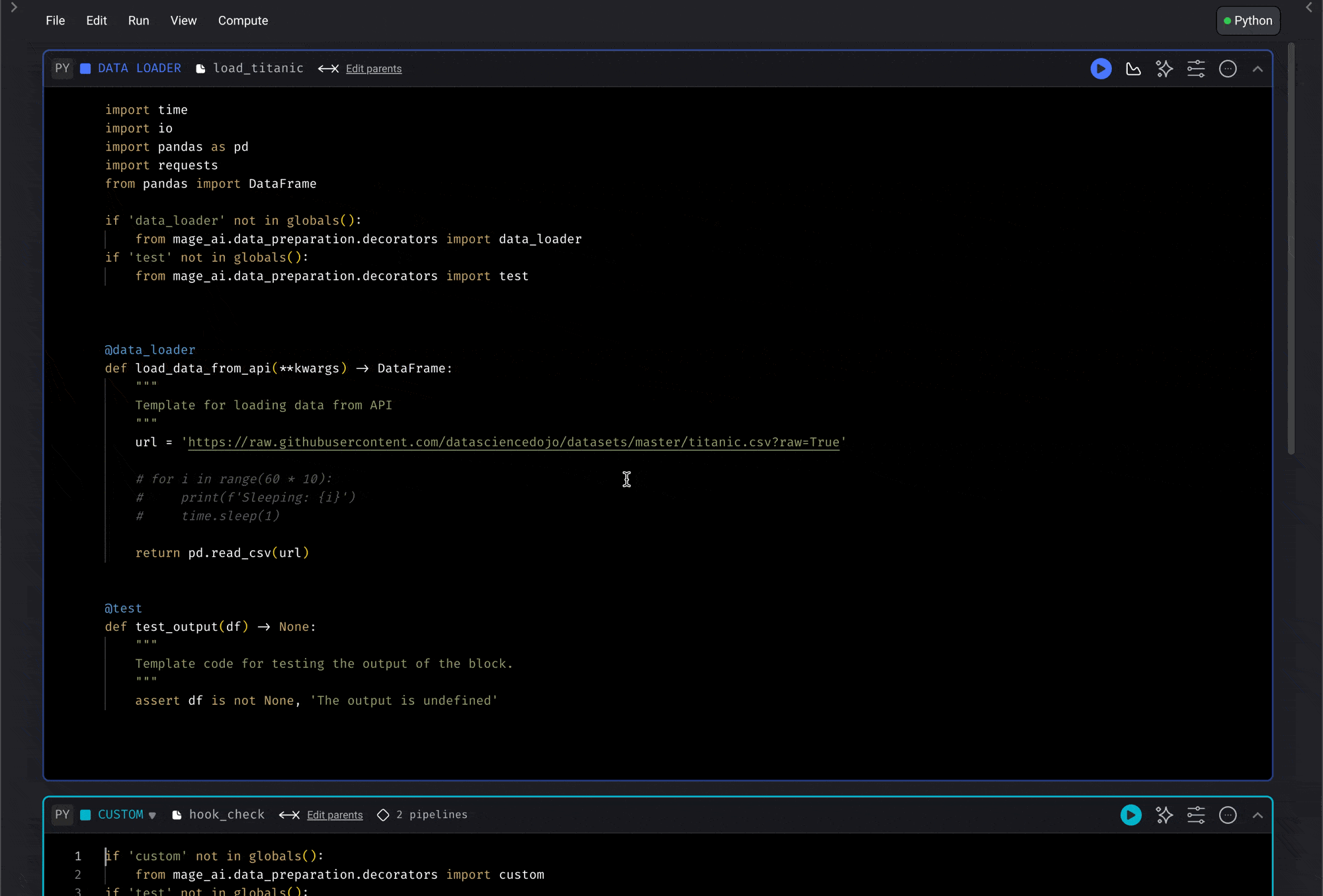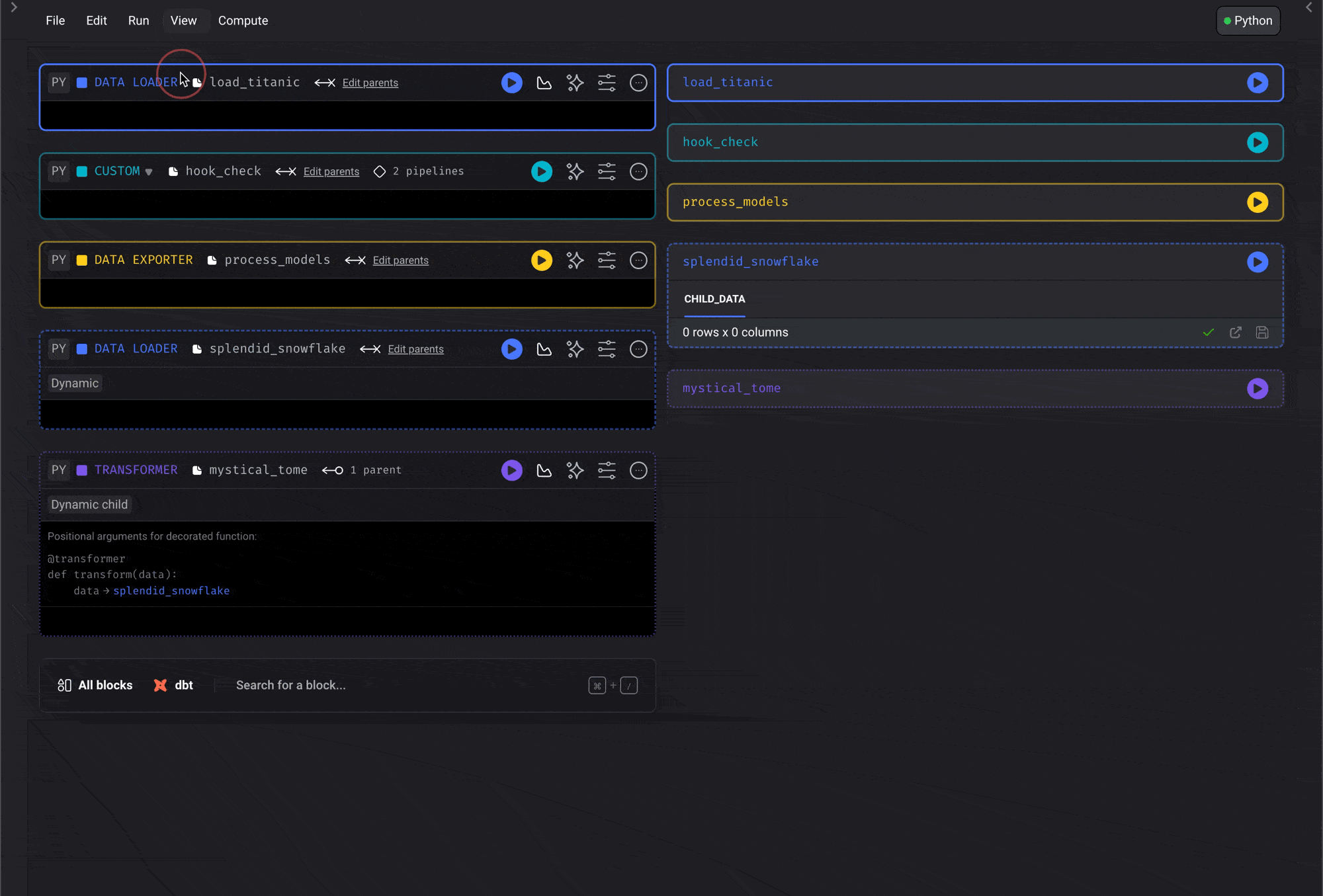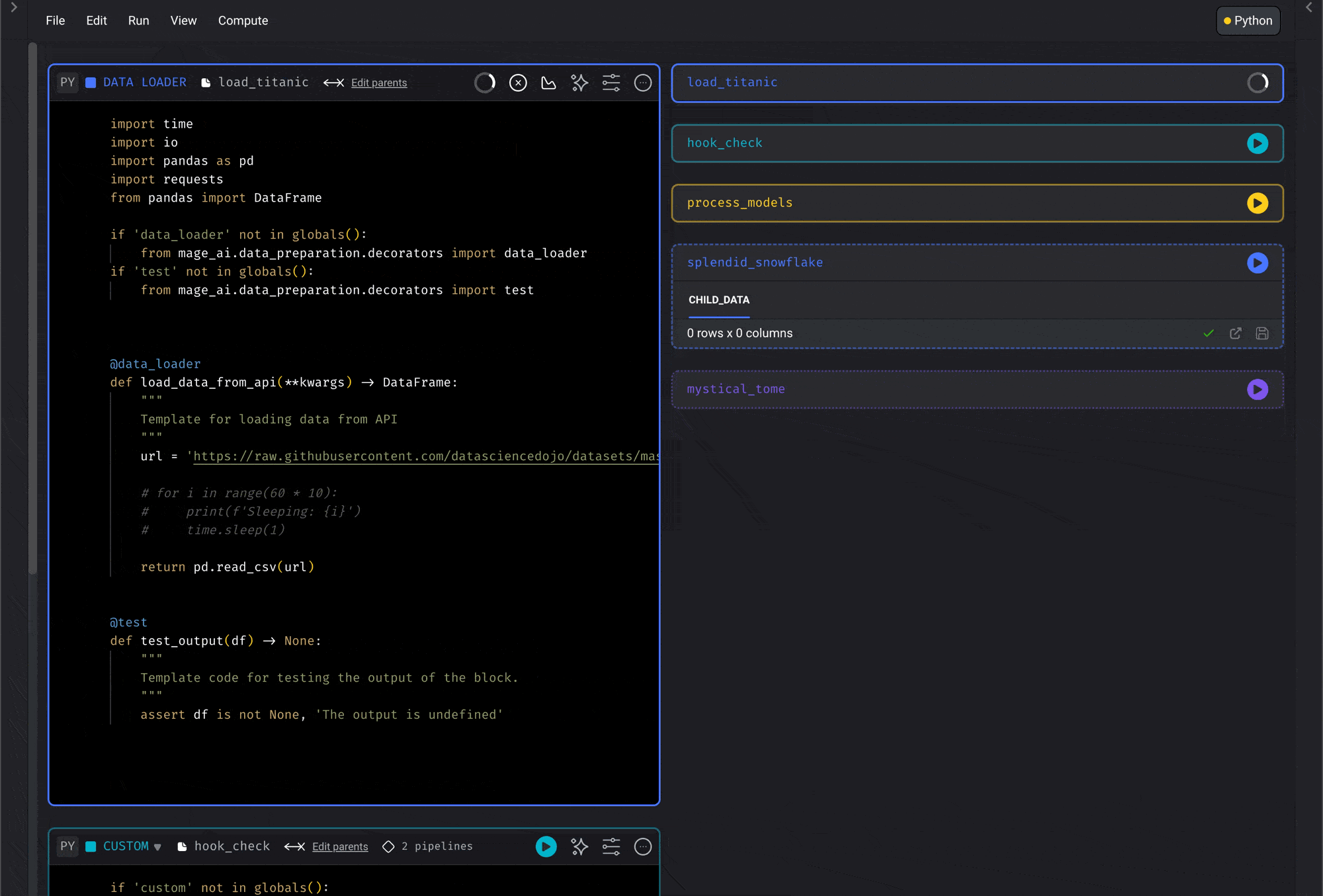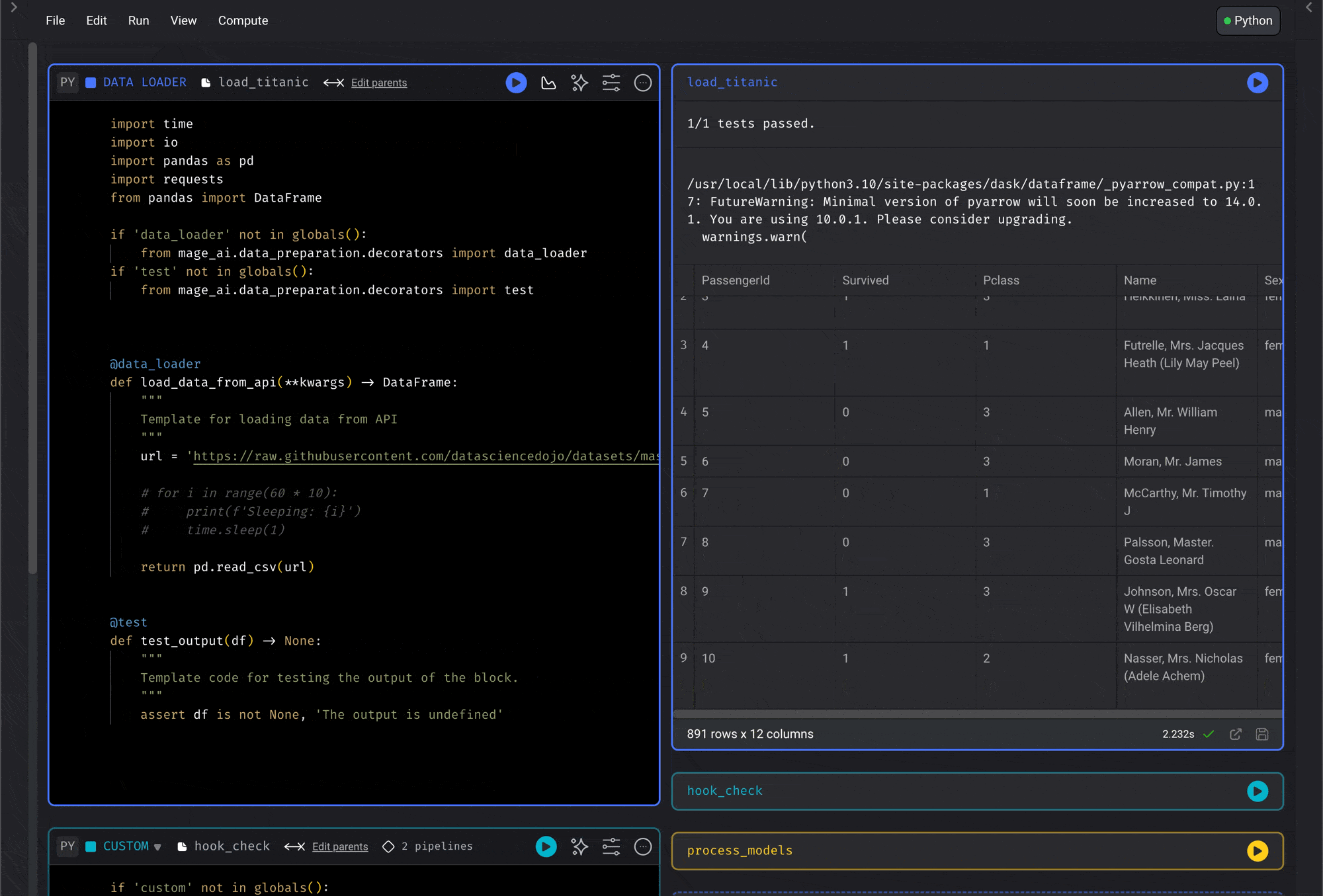
- Go to your project settings.
- Enable the feature named Notebook block output split view.
- Open the edit view of a pipeline.
- Under the header menu named View, click the option Show output next to code.
Check out this demo for a quick overview
Check out this demo for a quick overview