- Under the data loader block you just added, click the button
dbt model, then click the optionSingle model. - In the file browser that pops up, click the file of the dbt model you want to add to your pipeline.
- In the
dbt profile targetinput field, enter the name of the dbt connection profile (e.g.dev) that you want to use when running the selected dbt models.
Depending on upstream blocks
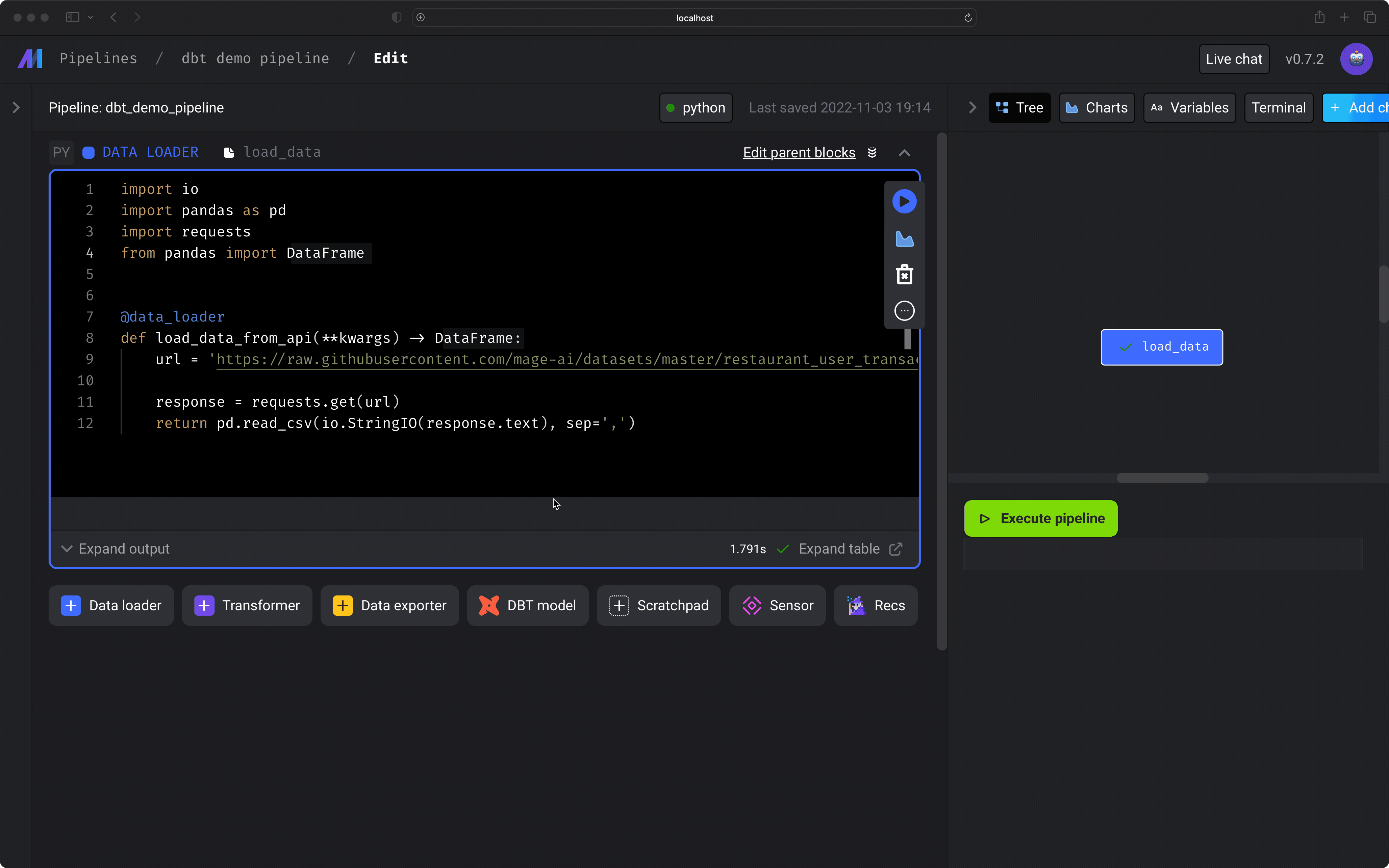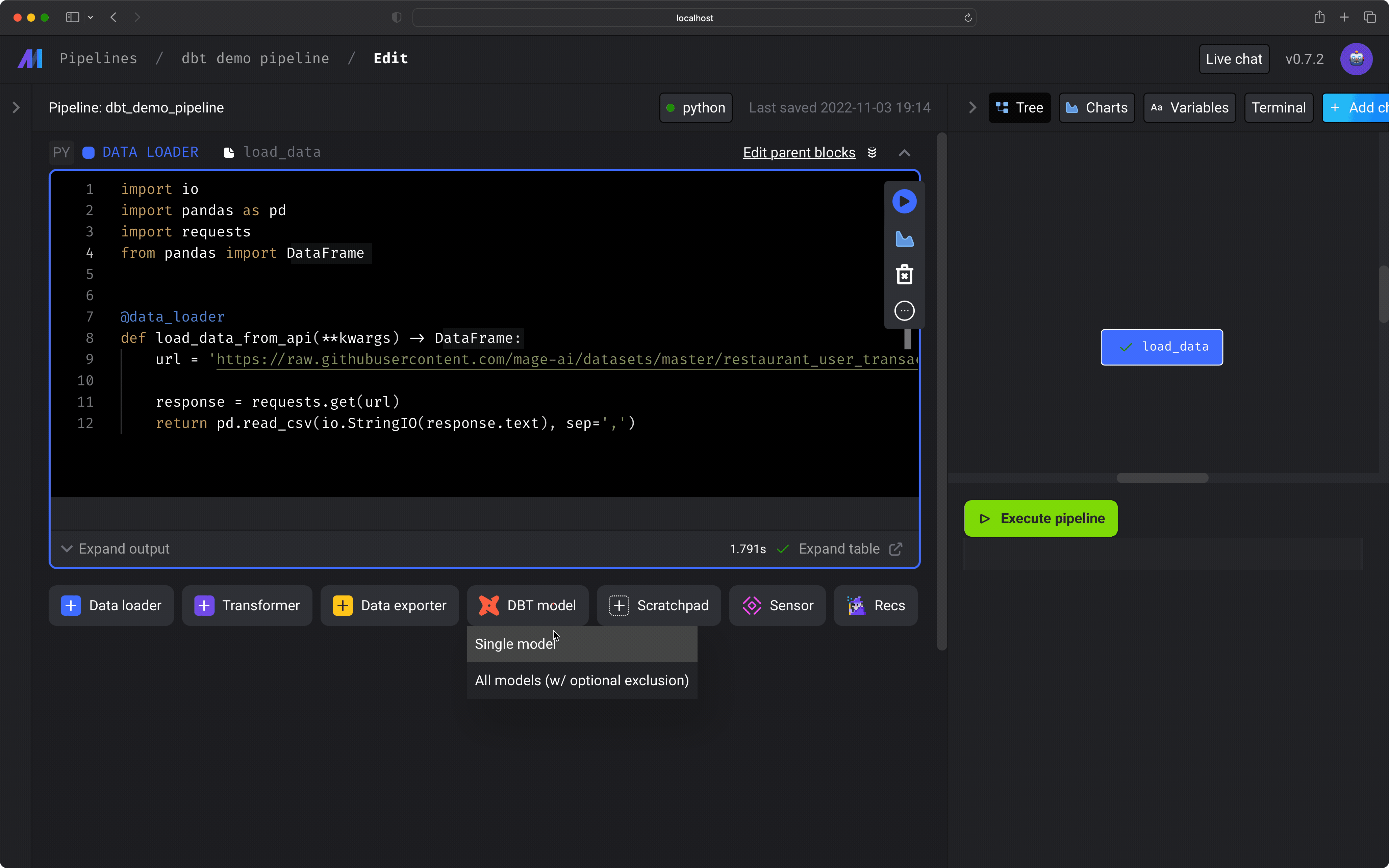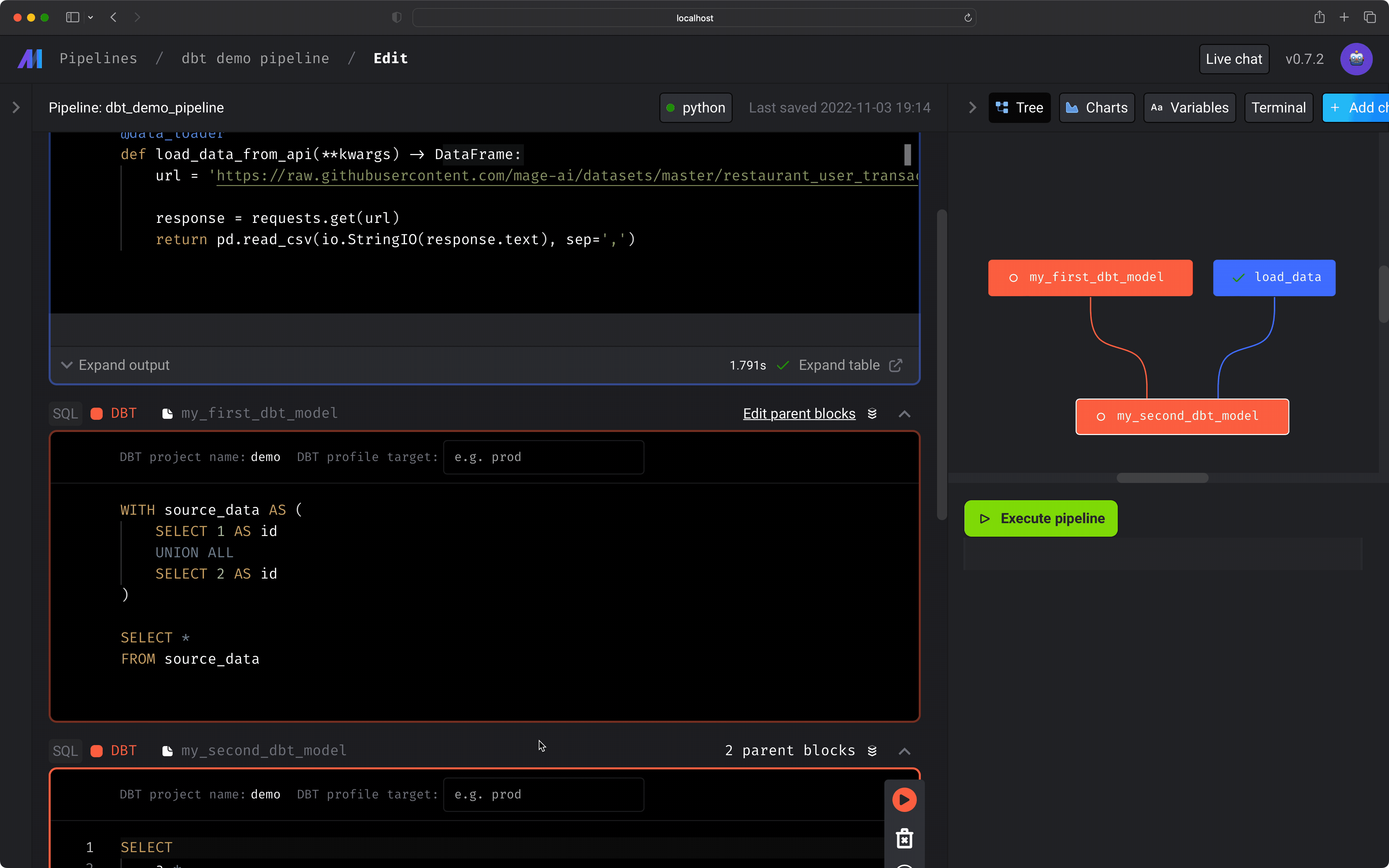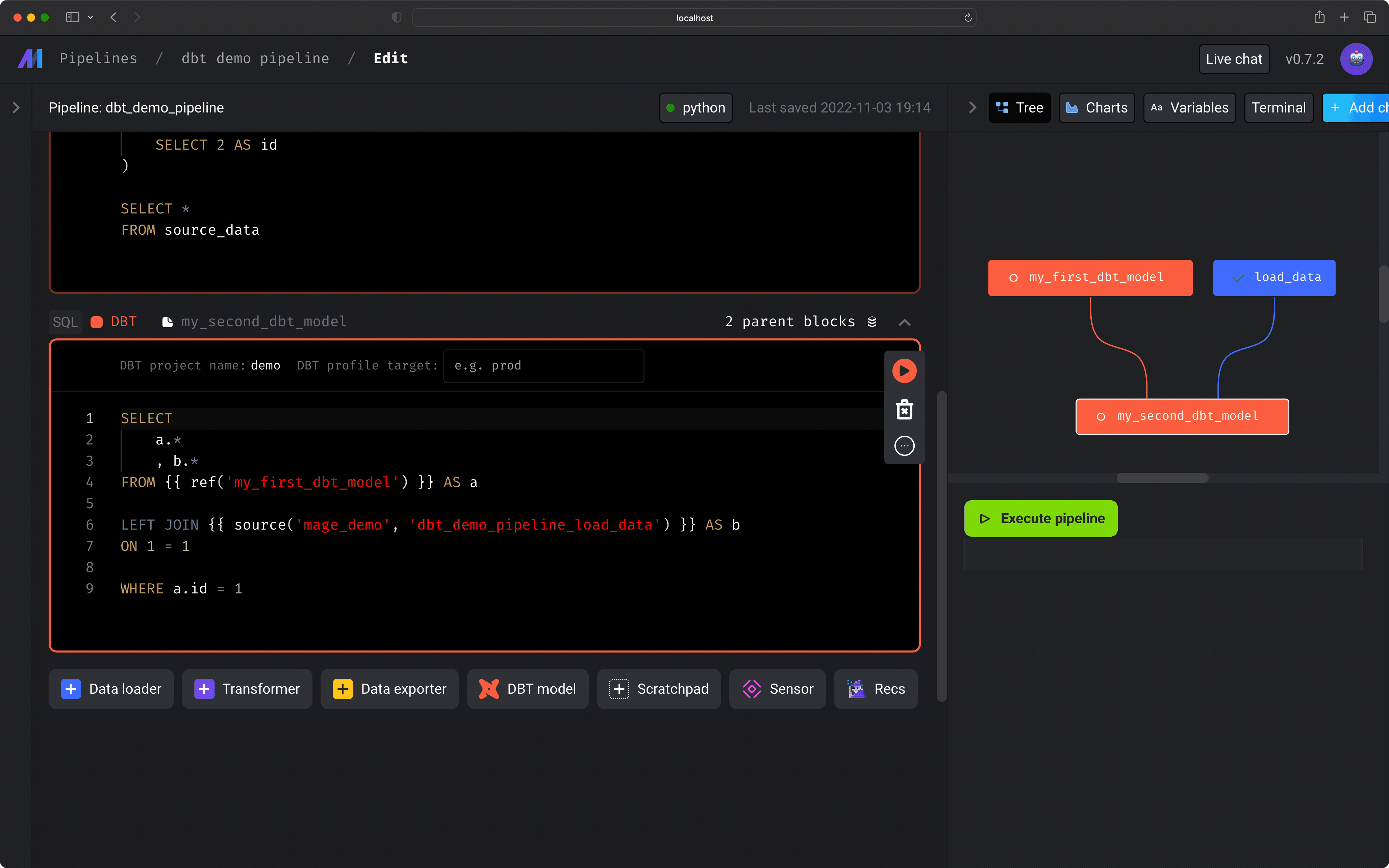
If your dbt model references other models, those models will also be added to the current pipeline as upstream blocks. Once you’ve added 1 or more dbt models to your pipeline, you can set its dependencies on other blocks. The dbt model won’t run until all upstream blocks have successfully been completed.Preview dbt model results
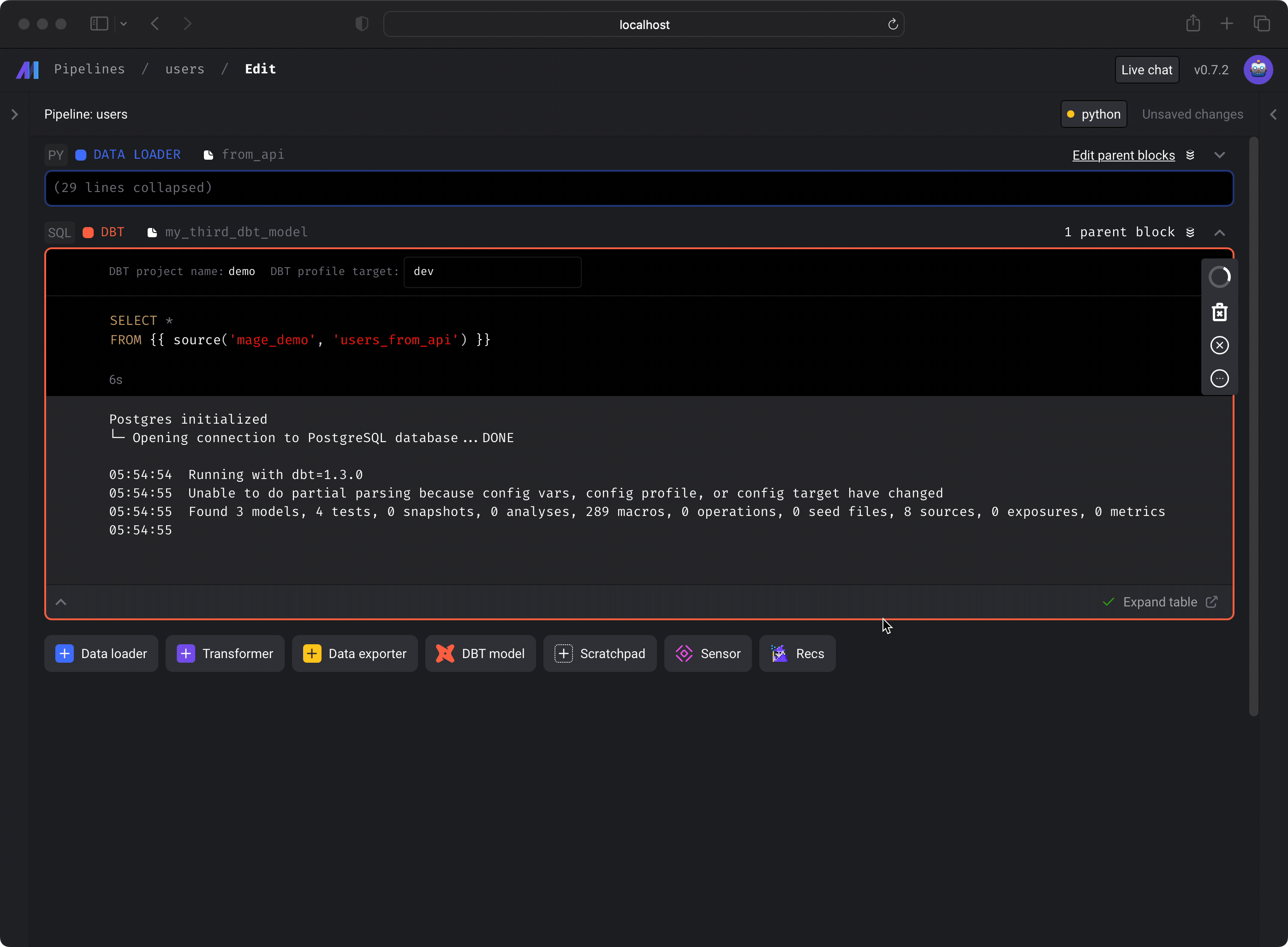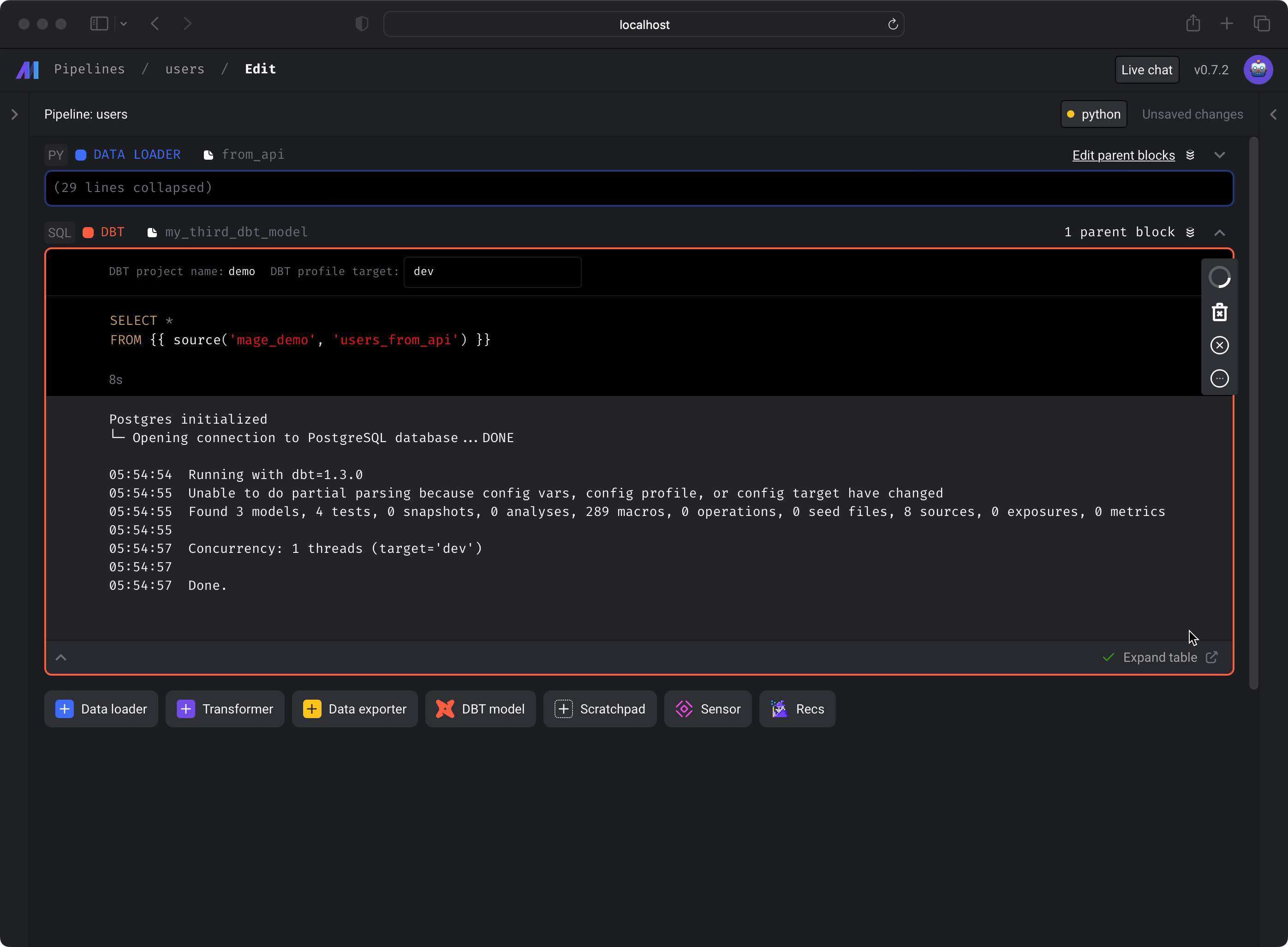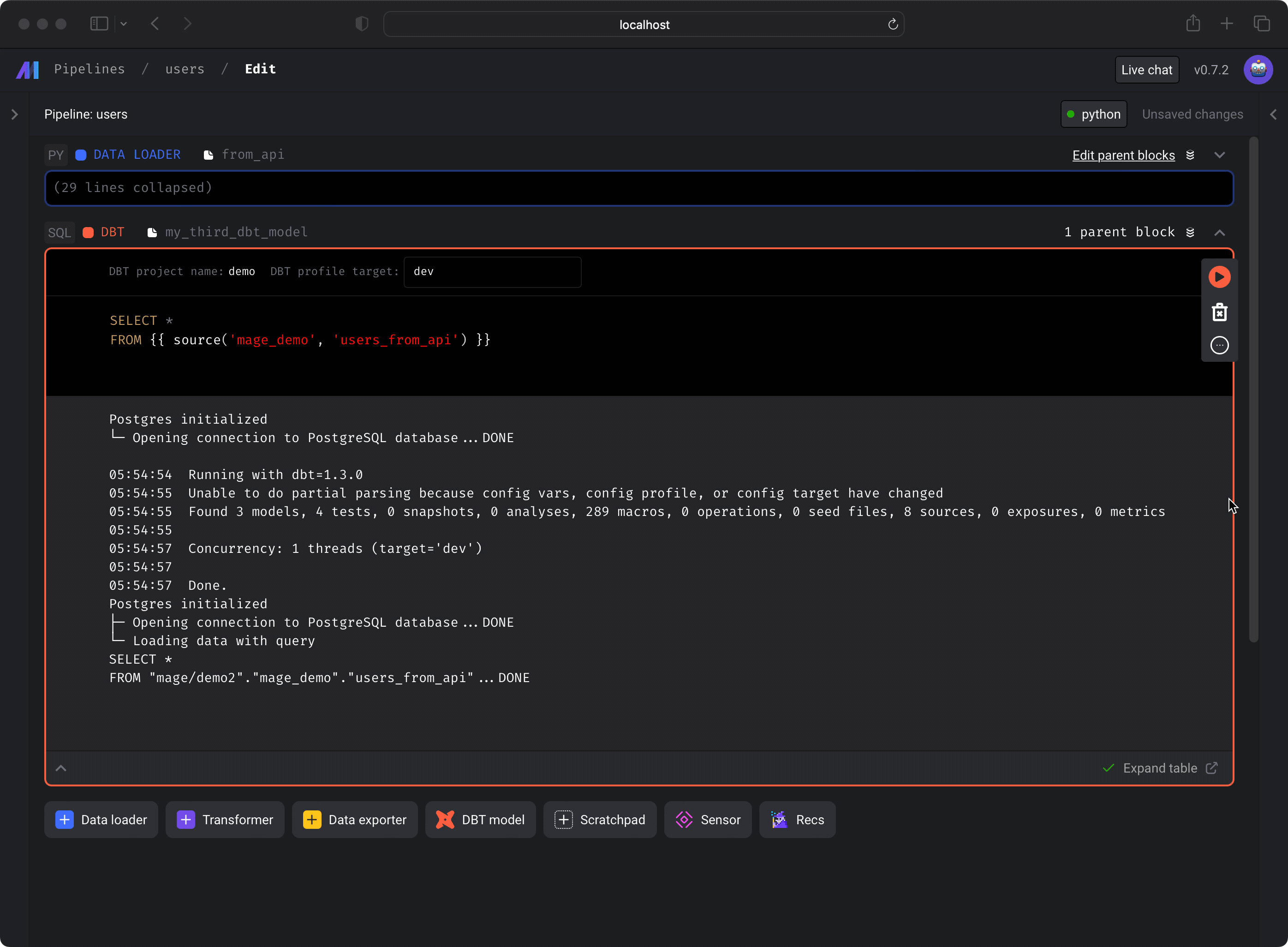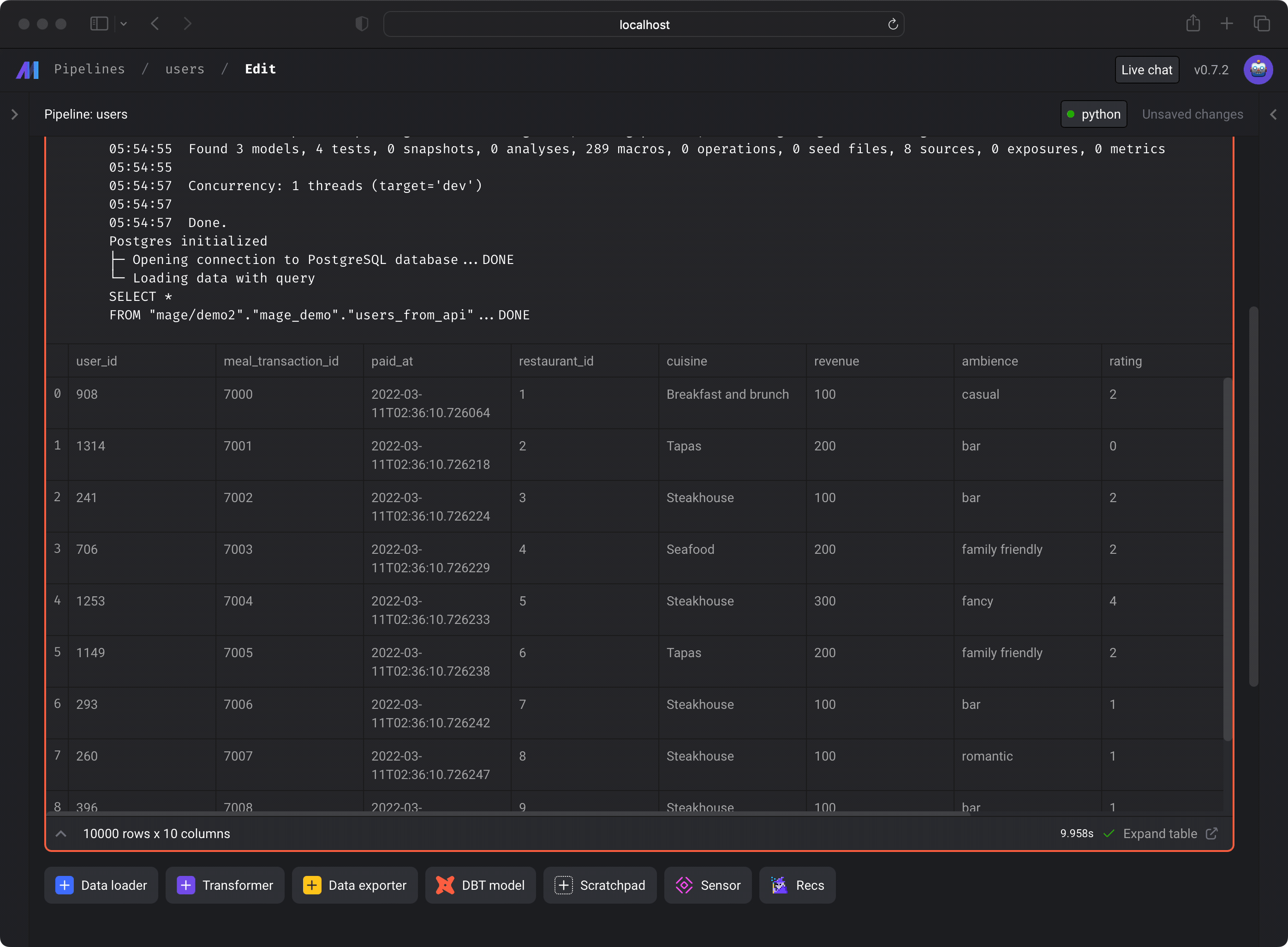
You can run a dbt model block and see the results of the SQL query. Under the hood, Mage is runningdbt compile for that
single model, then executing the compiled SQL query in the data source from your
dbt project’s
connection profile
target.
Pipeline execution run
When pipeline is triggered and executes, it’ll run each dbt model block using thedbt run
command.
Variable interpolation
You can add variables specific to your pipeline. These variables are accessible in each block of your pipeline. In addition, all the environment variables are accessible within the SQL query using thevar syntax.
SQL statement
Within the SQL query in a dbt model block, you can access these variables using thevar syntax. To learn more, read
dbt’s documentation.
For example:
ds is defined as part of the runtime
variables for the pipeline.
Upstream block output
You can also use the output from an upstream Mage block inside a dbt SQL model withblock_output. This is useful when a Python, SQL, or dynamic block decides
which value the dbt model should query, filter, or materialize.
For example, an upstream data loader named select_city can return a record:
parse to return a scalar value that is valid SQL.
Mage only hydrates block_output(...) before invoking dbt. Other dbt Jinja such
as {{ config(...) }}, {{ ref(...) }}, and {{ source(...) }} is left for dbt
to compile. Hydrated dbt SQL is written to an isolated temporary copy of the dbt
project for each execution, so concurrent runs of the same model do not overwrite
the source model file or read another run’s interpolated SQL.
Adding variables when running a YAML dbt block
In addition to interpolating variables described above, you can define variables directly in the dbt code block if it is a YAML dbt code block (i.e. not a SQL dbt block) by following these steps:- In the Pipeline Editor, add a dbt model by selecting on the
All models (w/option exclusion)option from the dropdown when clicking on thedbt modelbutton for adding a block. - For the newly added code block, you should see that is
YAMLtype indicated in the top left corner of the block. - On the same line as your
--selector--excludesyntax, add the--varssyntax with the variables you want to include. Note: Putting the--varssyntax on a separate line may cause issues. - Format the variables like a JSON object, so there should be double quotes around the keys and string values. Single quotes surrounding the variables object are optional.
- You can interpolate global or environment variables using double brackets around the variable name. See below for examples.