Run
-
Under the data loader block you just added, click the button
dbt model, then click the optionAll models. -
In the
dbt project nameinput field, enter the name of the dbt project that contains the models you want to build and run (e.g.demo). -
In the
dbt profile targetinput field, enter the name of the dbt connection profile (e.g.dev) that you want to use when running the selected dbt models. -
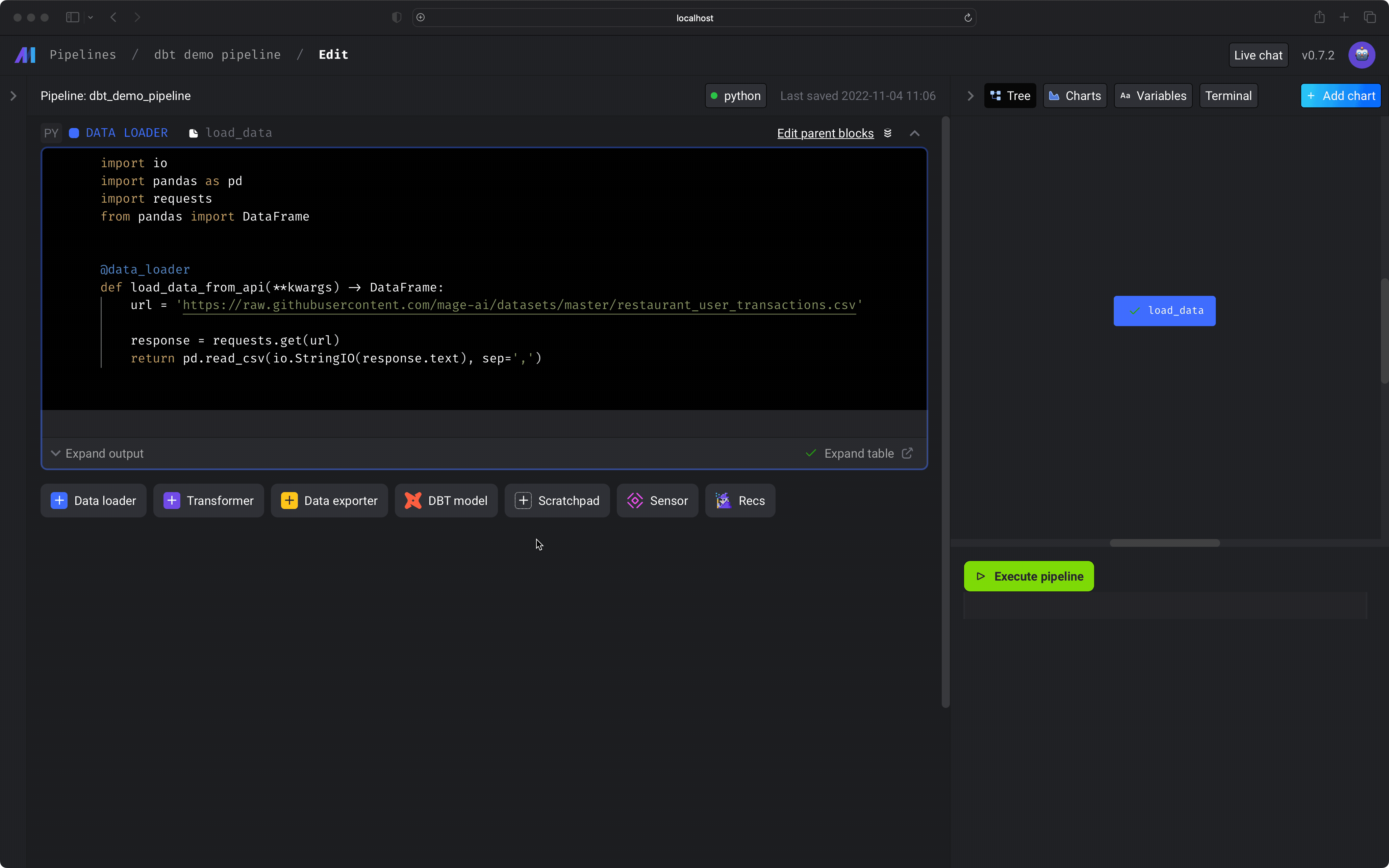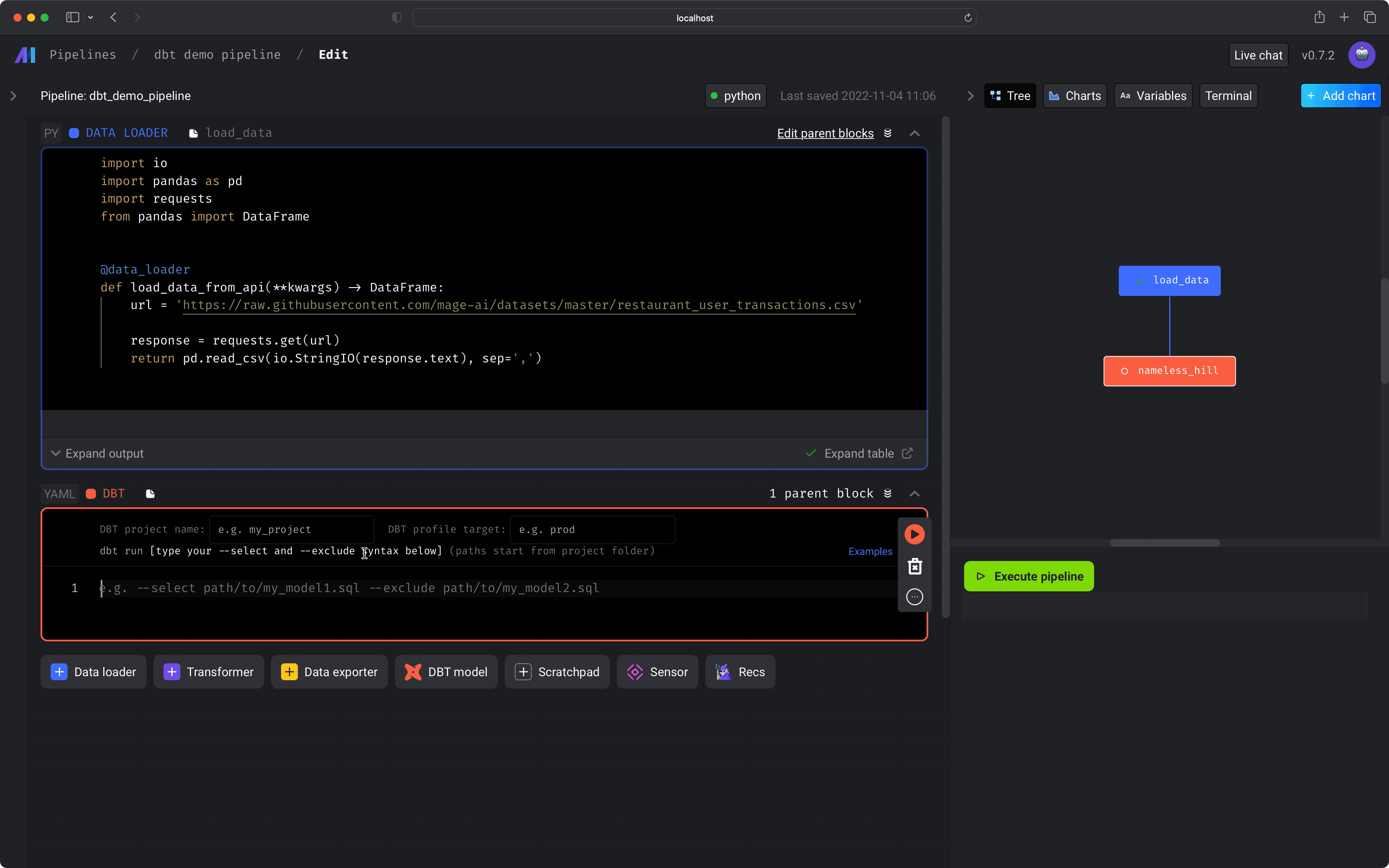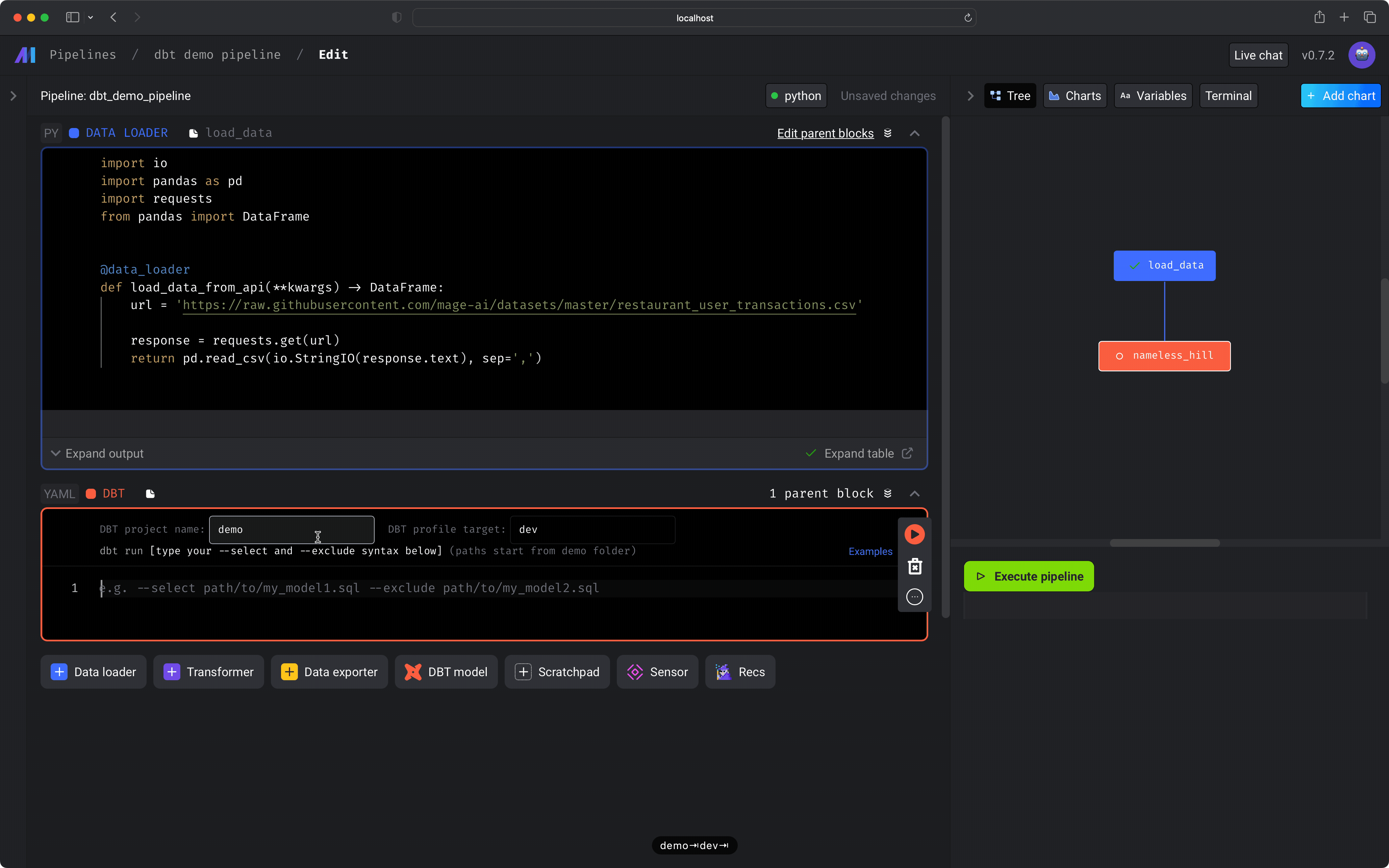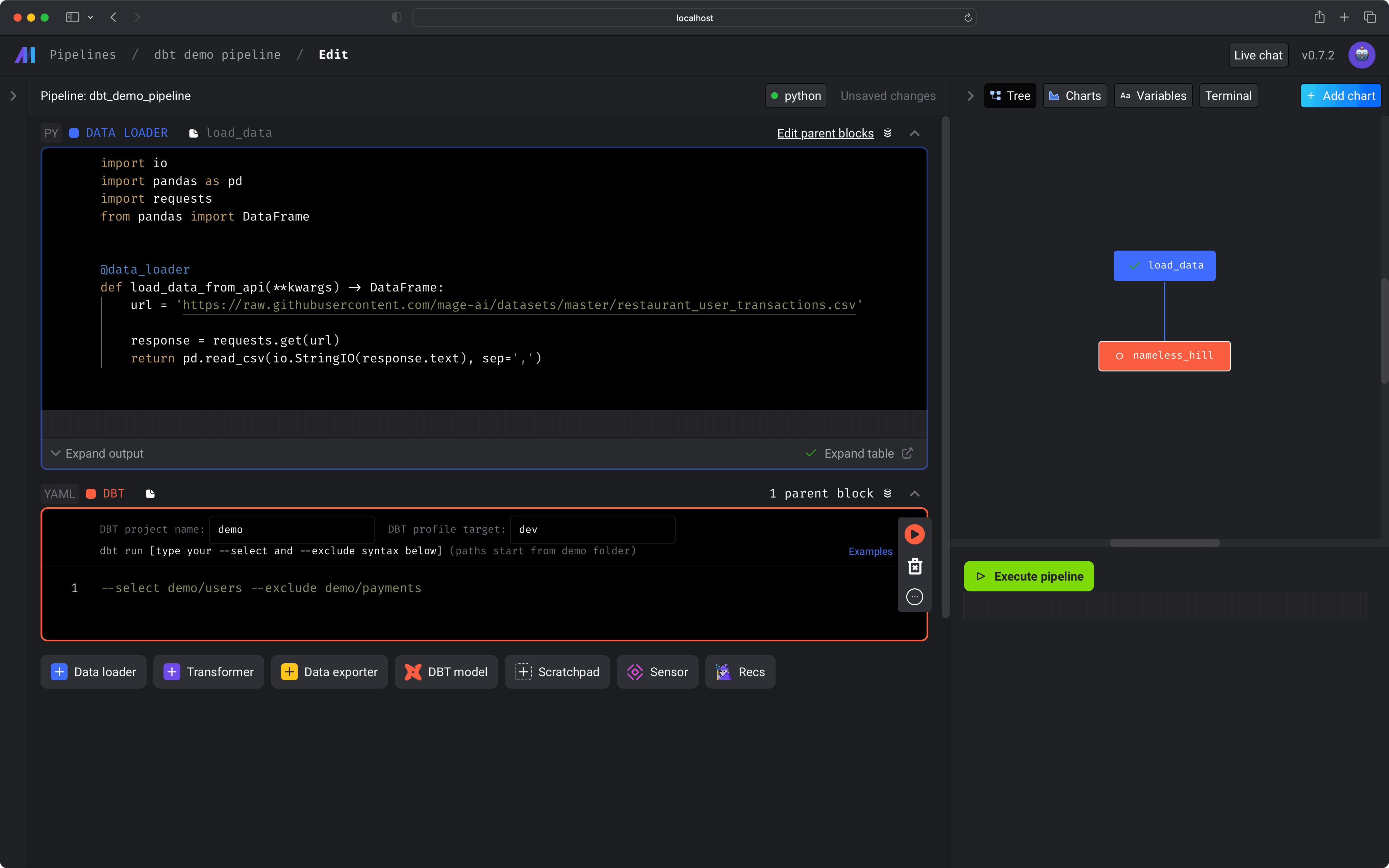
In the text area of the code block, write the models you want to select or
exclude using dbt’s
--selectand--excludeflags and syntax. For more information on the--selectand--excludesyntax, read dbt’s documentation. For example:
Variables
Add additional variables to yourdbt command by writing the following in your block’s code:
Interpolate values
Interpolate values in the block’s code using data from:- Upstream block output
- Variables
- Global variables
- Pipeline variables
- Runtime variables
- Environment variables
Upstream block output
Use the data from 1 or more upstream block’s output by using theblock_output function.
block_uuid
The UUID of the upstream block to get data from.
If argument isn’t present, data from all upstream blocks will be fetched.
parse
A lambda function to parse the data from an upstream block’s output.
If the parse argument isn’t present, then the fetched data from the upstream block’s output
will be interpolated as is.
Arguments
-
dataIf theblock_uuidargument isn’t present, then the 1st argument in the lambda function is a list of objects. The list of objects contain the data from an upstream block’s output. The positional order of the data in the list corresponds to the current block’s upstream blocks order. For example, if the current block has the following upstream blocks with the following output:load_api_data:[1, 2, 3]load_users_data:{ 'mage': 'powerful' }
-
variablesA dictionary containing pipeline variables and runtime variables.
Example
Withblock_uuid
block_uuid
Variables
Interpolate values from a dictionary containing keys and values from:- Global variables
- Pipeline variables
- Runtime variables