Using Runtime Variables
Runtime Variables can be accessed via the**kwargs parameter in your block
function.
- integer
- string
- float
- boolean
- list
- dictionary
- set
Creating Runtime Variables
In Mage editor
You can create new global variables from the Mage UI through the “Variables” tab in the sidekick. Click the “New” button, and configure your variable’s name and value, and press Enter to save. To edit global variables, hover over the variable and click on the edit button. You can edit the variable name and/or value, and press Enter to save.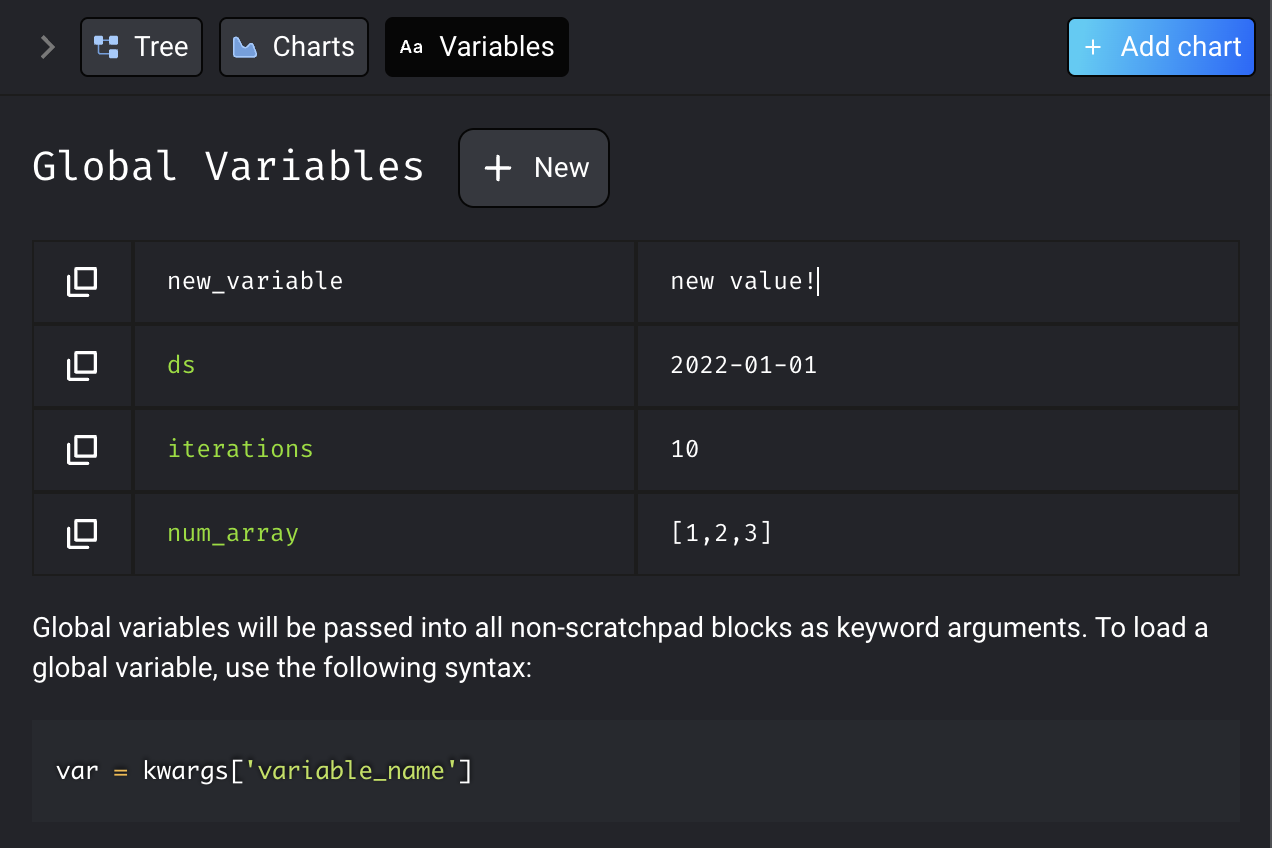
In code
You can also create pipeline-level variables in code by editing the pipeline’smetadata.yaml file.
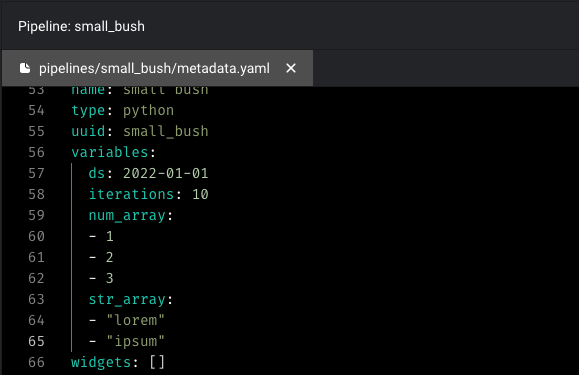 If you’d like to create environment specific pipeline variables, you can format the
If you’d like to create environment specific pipeline variables, you can format the variables arguments as follows:
ENV=dev, ENV=staging, ENV=prod which can be leveraged to indicate the execution environment.
A simple python function can then be used to access the variables:
In Python code
You can also save the variable in Python code. One example usage is to save checkpoint data.Default Runtime Variables
Mage provides some default variables to give context on the pipeline execution.execution_date: A datetime object that the pipeline is executed at.event: If the pipeline is triggered by event, theeventvariable contains the event payload.
Running Pipeline with Runtime Variables
Run from command line
You can execute your pipeline with runtime variables from the command line. First, make sure you installed the package.Run from Python script
If your pipeline is configured to use runtime variables, you can still execute your pipeline outside the code editor. Provide the runtime variables as keyword arguments tomage_ai.run():
Example - Aggregating Daily Logs
A common use of ETL pipelines is to process and analyze daily events. In the case of this example, we will create an ETL pipeline to analyze log messages from a web application. Suppose the following is an example of a log file that our web application produces.
Suppose we want to know the distribution of log types at the end of every day.
Using Mage’s runtime variables this is made a very simple task:
-
Create a data loader to load all log files modified on a specific date. We
will specify the log folder and the date to load logs from using runtime
variables which are passed to this block via the
**kwargsparameter.Note: This code ignores the edge case of a log file that spills over between days. Since the modification date is used instead of the creation date, a log file that is modified between days will only be considered in the latter day. -
Calculate the distribution of log types over this date
The result of this transformer is a new data frame that looks like below:
mage_ai.run(), providing the current date and log folder as keyword arguments:
Example - Model Rockets
Consider the following sample data tracking the launch angle (in degrees) and vertical velocity (in meters per second) of model rocket tests:
Suppose we want to convert the launch angle from degrees to radians in our
pipeline. The example below uses the
pi runtime variable (passed in through
**kwargs) to convert the degrees column of some input data frame to a radians.
This allows us to control the precision with which we want to store pi.
conversion_factor (again passed in through **kwargs), the vertical velocity
in kilometers per hour can be computed:
mage_ai.run(). Specify values for runtime variables as keyword arguments to
this function: