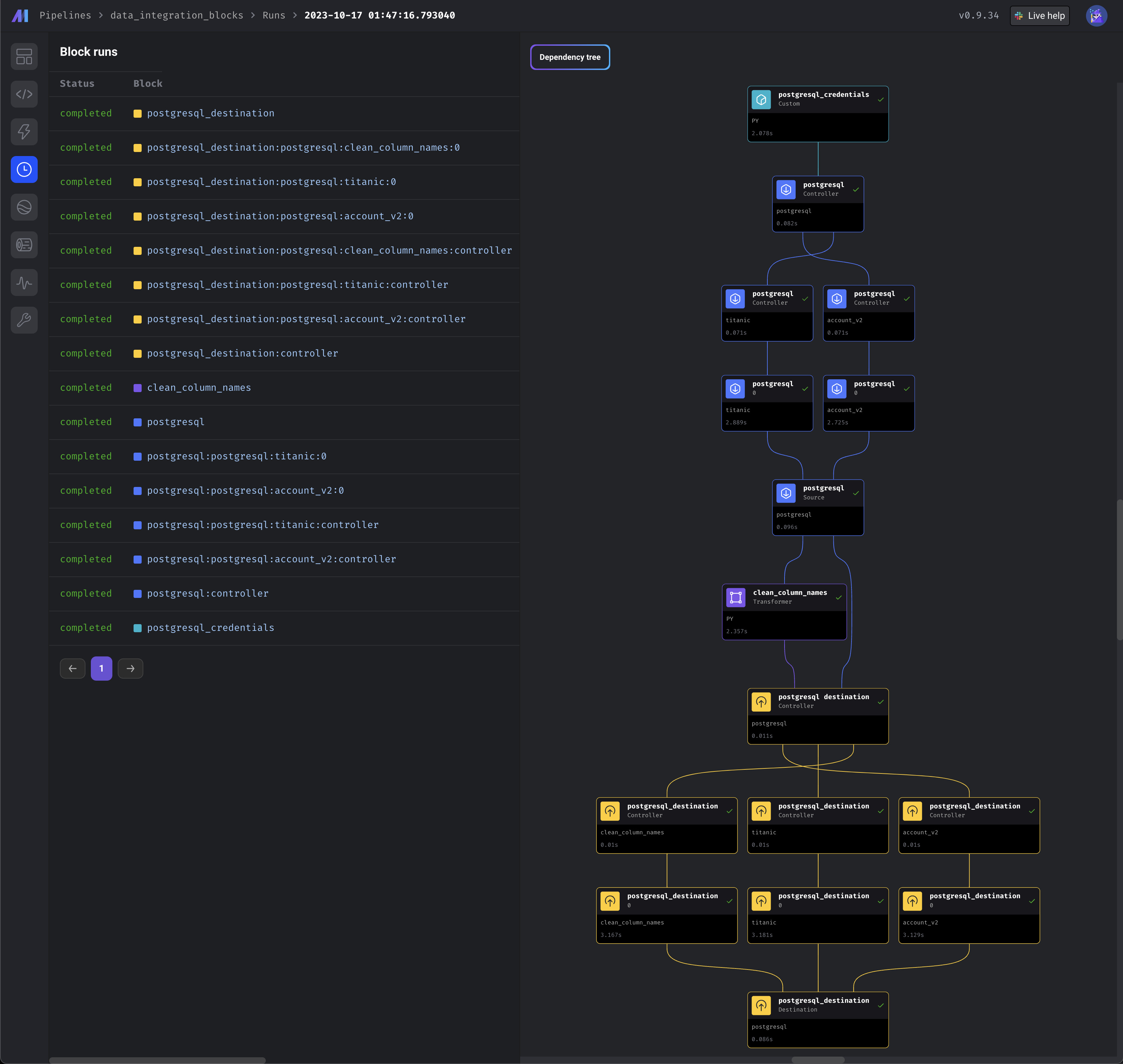
Overview
You can use a data integration source (e.g. Stripe) and/or a data integration destination (e.g. Trino) as a block in batch pipelines.Why is this important?
Combine the low-code aspect and capabilities of data integrations with the flexibility and dynamic capabilities of a batch pipeline.Example
- Use a Python data loader block to write custom code for fetching Stripe credentials.
- Use a SQL data loader block to fetch data from a table in PostgreSQL.
- Add a data integration source block to fetch data from Stripe.
- Use the output from the Python data loader block and interpolate the Stripe credentials into the data integration source block.
- Add a Python transformer block to merge, clean, and aggregate data fetched from PostgreSQL and Stripe.
- Add a data integration destination block that writes the output data from the Python transformer block and export it to SalesForce.
Features
- Use any data integration source.
- Use any data integration destination.
- Sources and destinations have capabilities of a normal Python block in a batch pipeline.
- Dynamically calculate the source and destination credentials at runtime.
- Dynamically build the source and destination catalog schema at runtime.
- Source blocks can output its fetched data to any downstream block.
- Any block can output its data to a destination block and have it exported to that destination.
- Support incremental sync
[Coming soon]Support log based sync.[Coming soon]Replicate source and destination blocks.[Coming soon]Support source and destination blocks as dynamic blocks.
How to use
-
Go to the project preferences and
enable the feature labeled
Data integration in batch pipeline.This feature requires theAdd new block v2feature to be enabled. - Create a new batch pipeline.
-
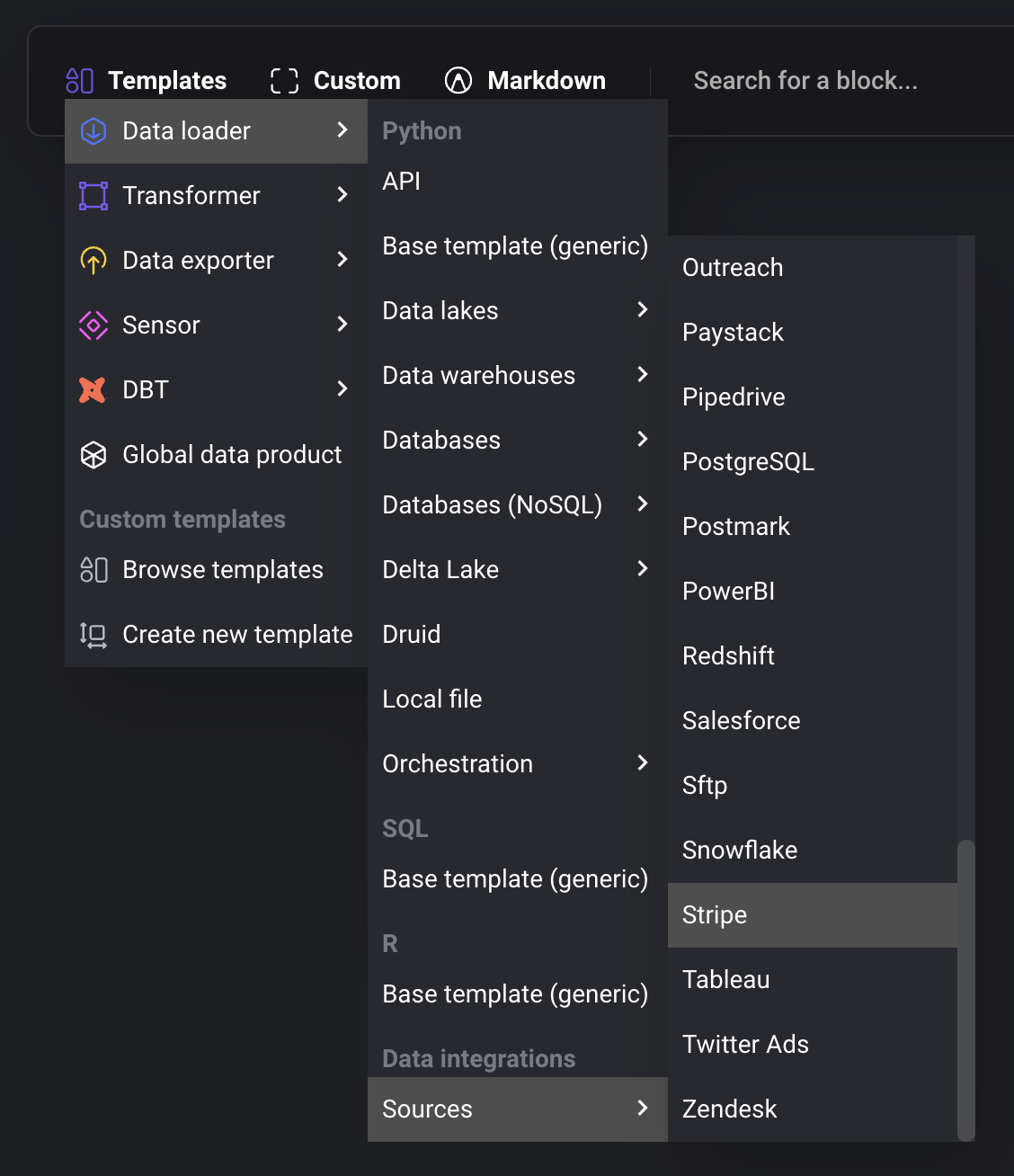
Add a new Data loader block by selecting:
- Templates →
- Data loader →
- Sources →
- Select the source to add to the pipeline.
-
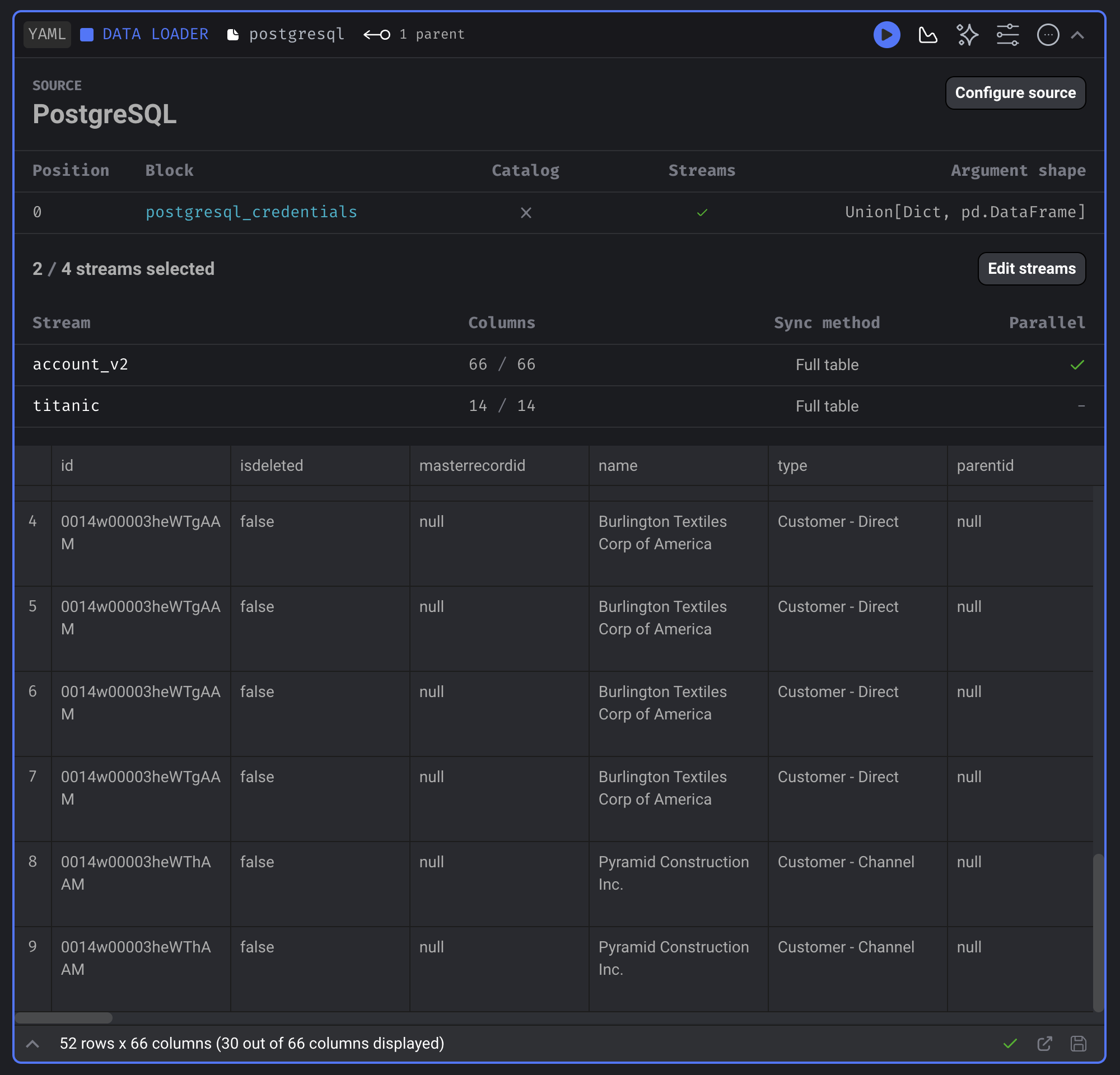
Configure the source:
- Add credentials.
- Select 1 or more streams to sync.
- Setup stream settings.
- Select 1 or more columns to sync from stream.
-
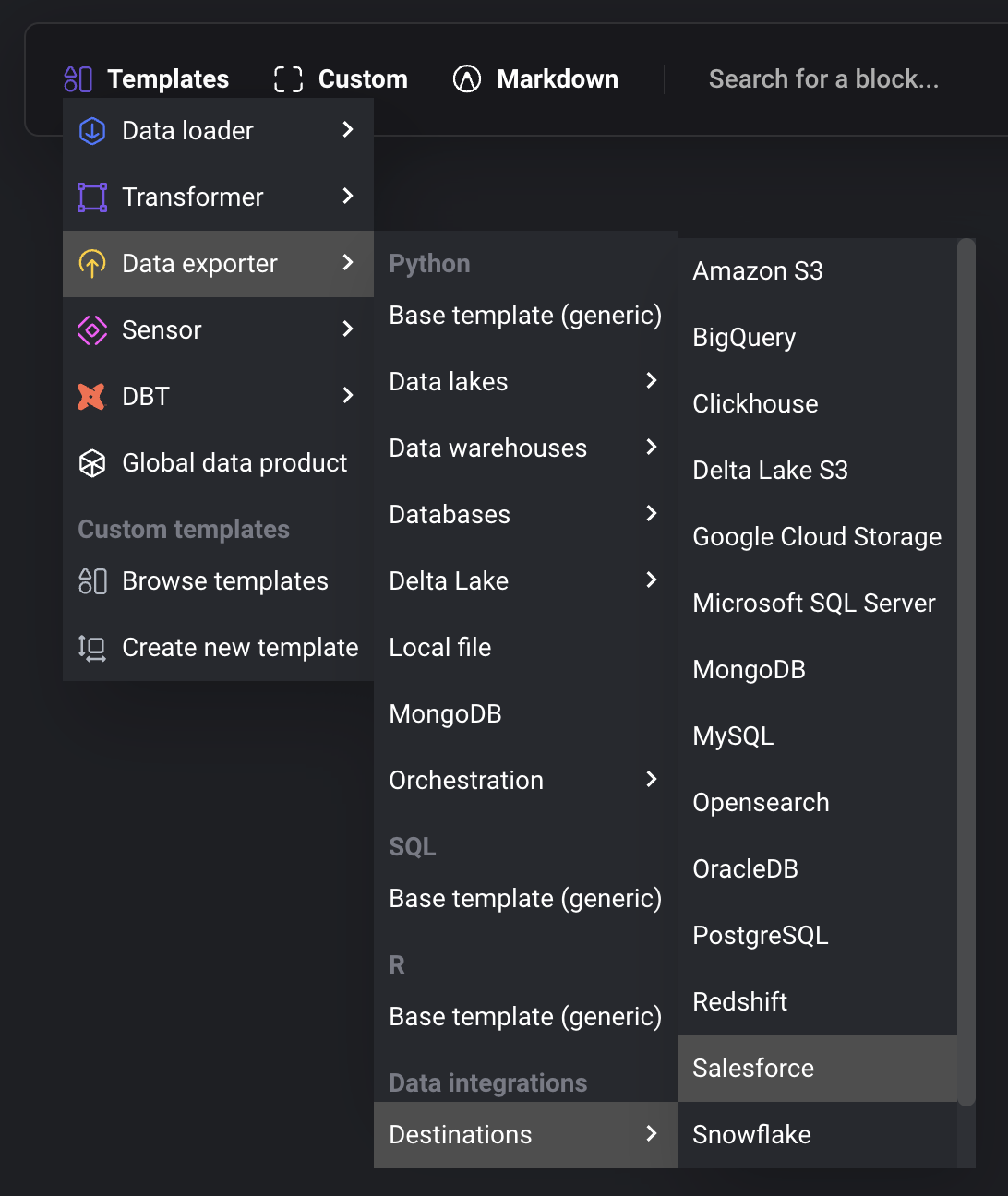
Add a new Data exporter block by selecting:
- Templates →
- Data exporter →
- Destinations →
- Select the source to add to the pipeline.
-
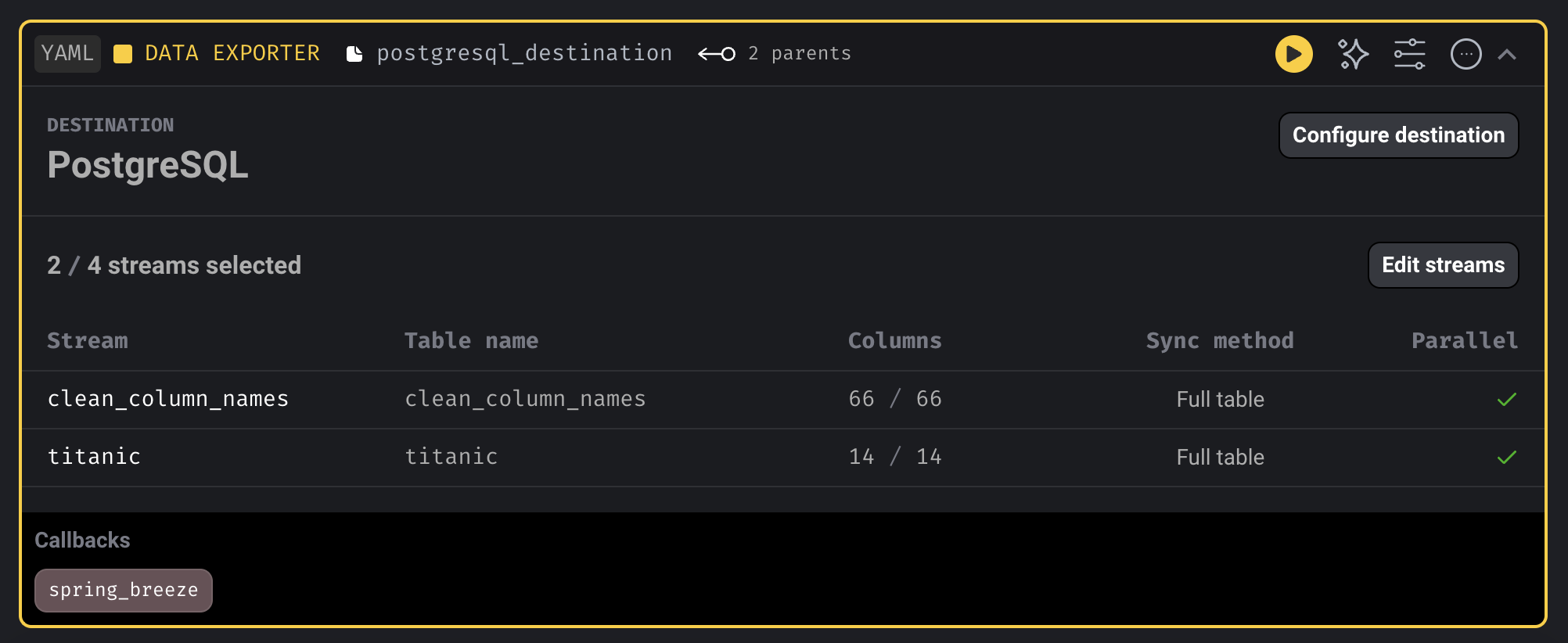
Configure the destination:
- Add credentials.
- Select 1 or more stre.ams to export.
- Setup stream settings.
- Select 1 or more columns to include in the destination table when exporting stream.
Configure source and destination
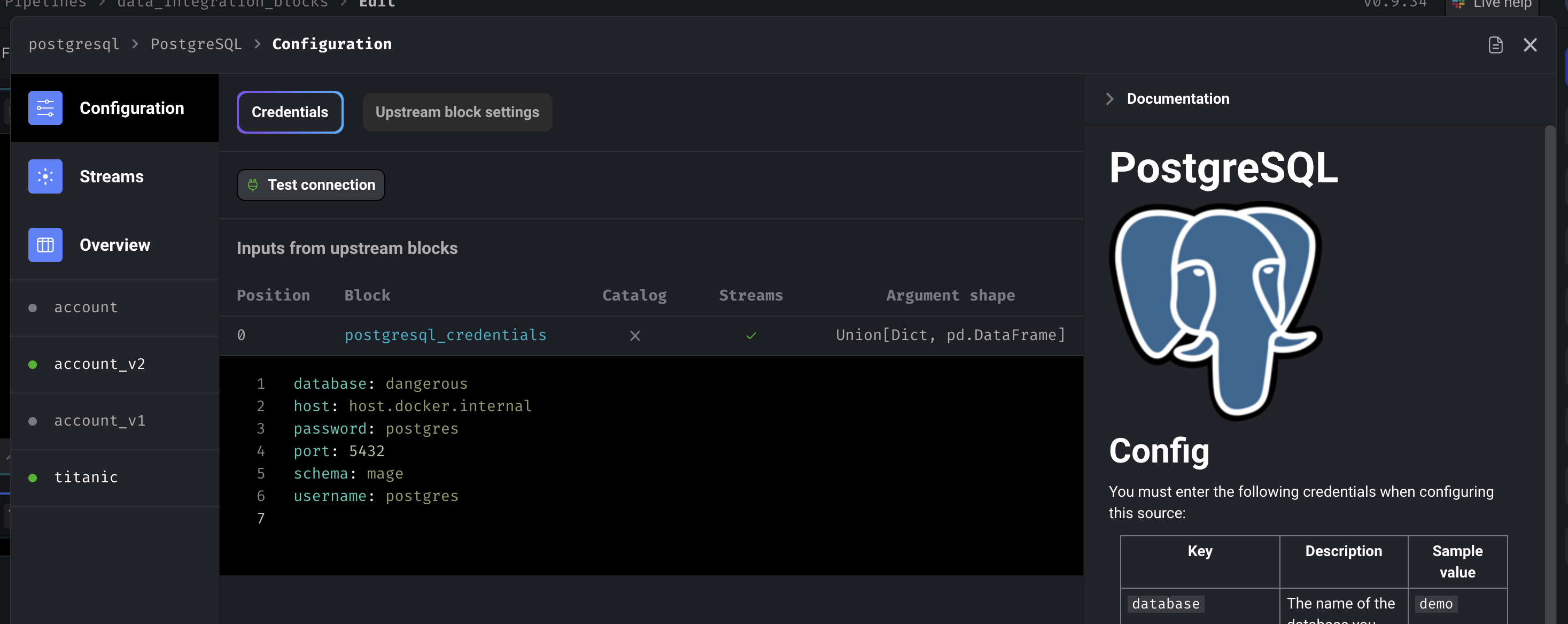
For more information on how to configure and setup a data integration source and destination, refer back to the original data integration guide.Credentials
Upstream block settings
Select streams
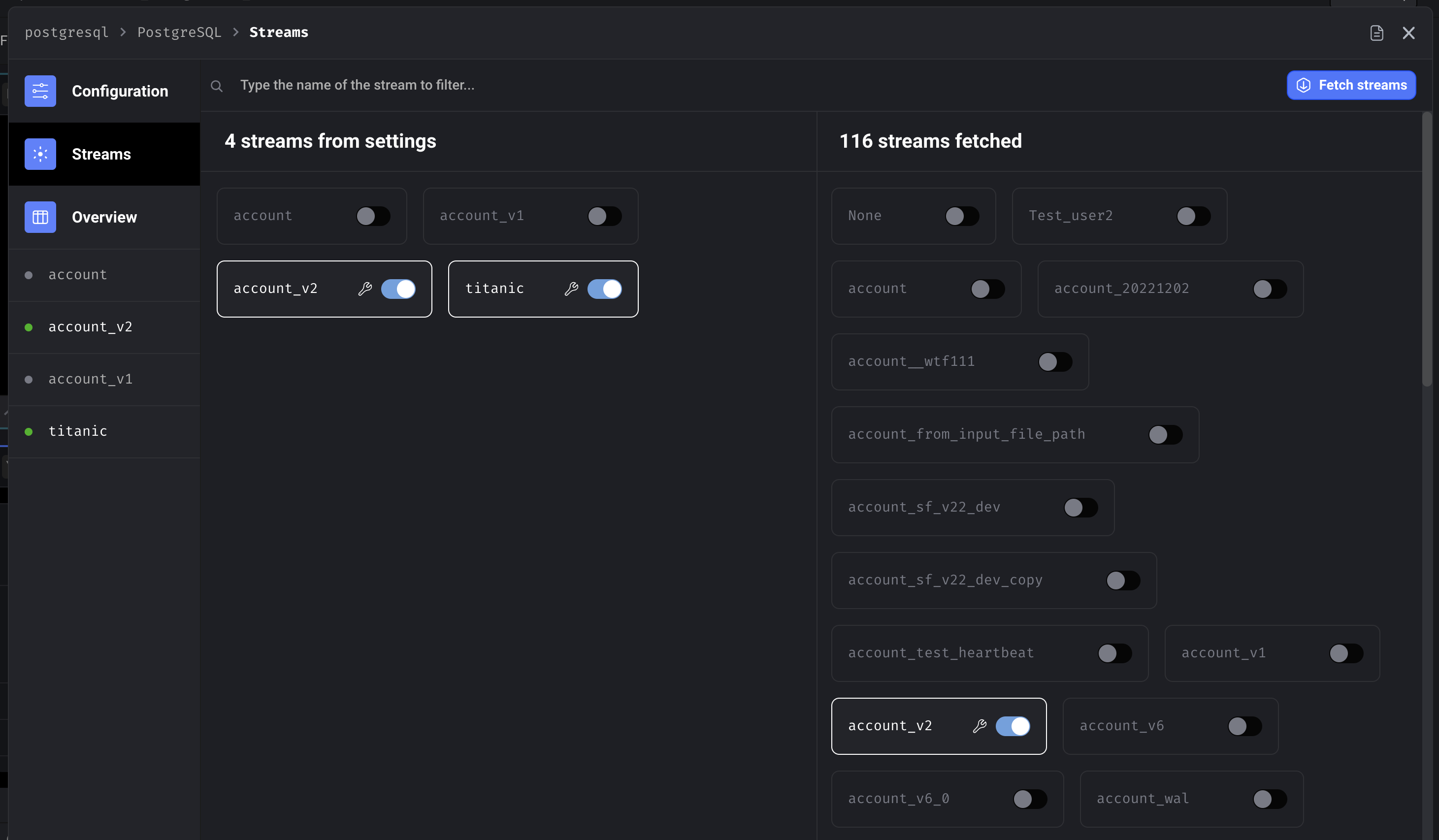
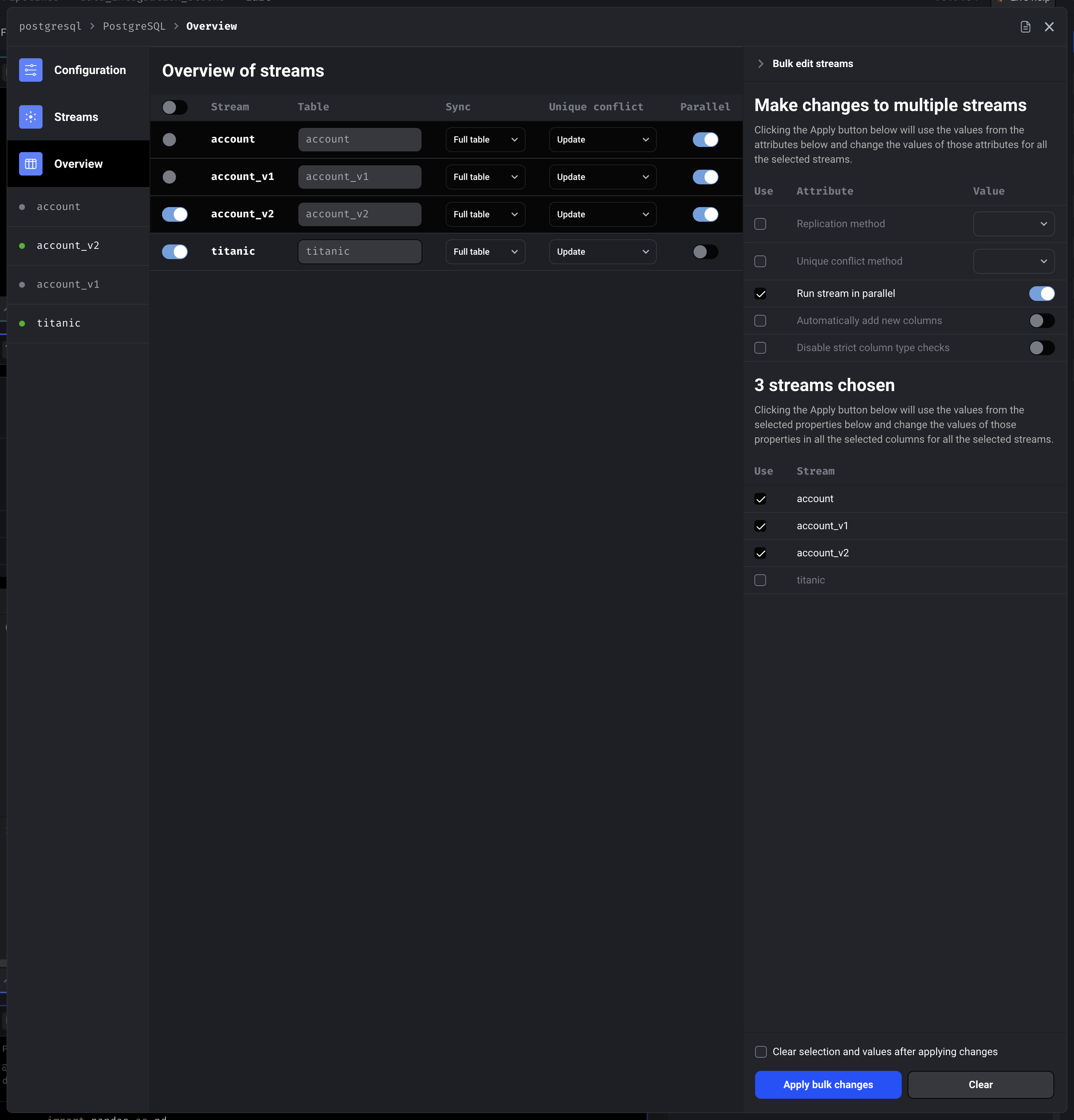
Streams overview with bulk editing
Stream detail overview
For more information on how to configure settings for a stream, refer back to the original data integration guide.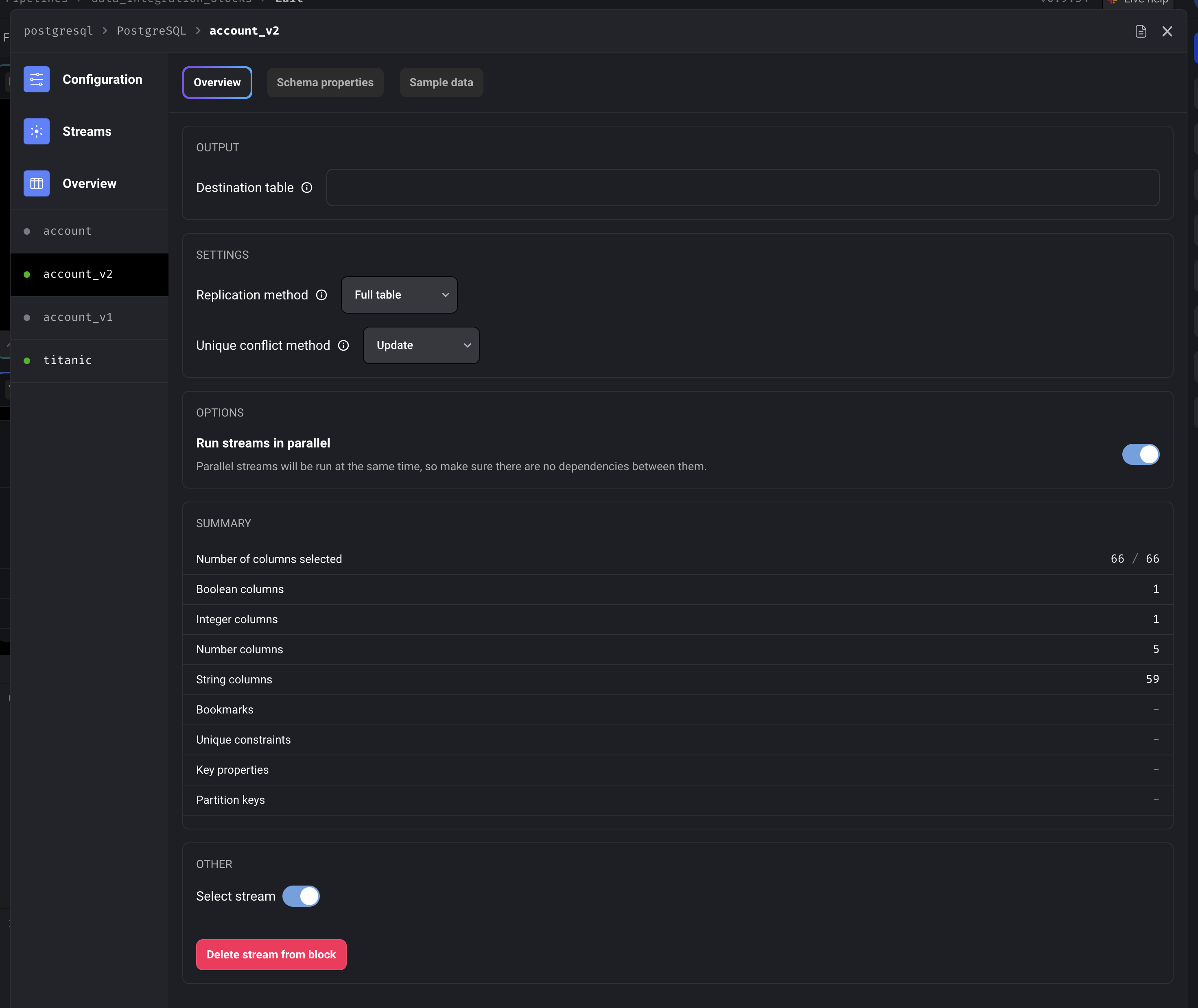
Stream detail schema properties with bulk editing
For more information on how to configure schema properties for a stream, refer back to the original data integration guide.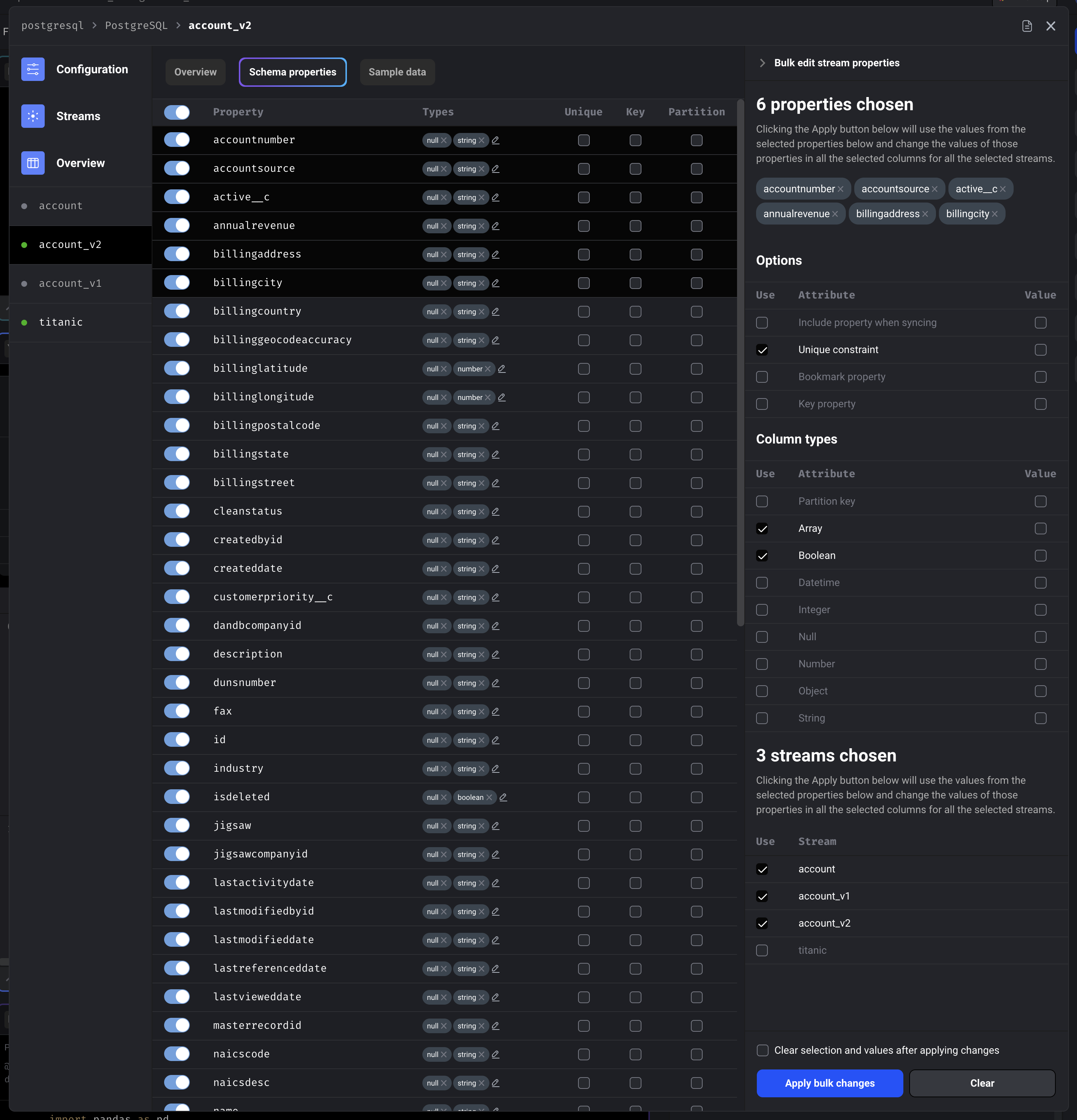
Stream detail sample data
Python blocks
When adding a data integration source or destination block to a batch pipeline, you can choose the language to be YAML or Python (default option is YAML). If you choose Python as the language, you programmatically define the following settings of the data integration:@data_integration_source
This decorated function is required.
@data_integration_destination
This decorated function is required.
@data_integration_config
This decorated function is required.
Keyword arguments inside the decorated function
The following keyword arguments are only available in the decorated function’s body for sources.@data_integration_selected_streams
This decorated function is optional.
Decorator arguments
The following arguments are only available in the decorator@data_integration_selected_streams
for sources.
Keyword arguments inside the decorated function
The following keyword arguments are only available in the decorated function’s body.@data_integration_catalog
The returned dictionary will override the catalog setup through the
user interface.
Decorator arguments
The following arguments are only available in the decorator@data_integration_catalog
for sources.
Keyword arguments inside the decorated function
The following keyword arguments are only available in the decorated function’s body.Data from upstream blocks
The data integration source and destination block can depend on upstream blocks. Those upstream blocks can pass its output data into the data integration source and destination, which then can be used as:- Input arguments to interpolate information in the credentials (or other decorated functions if source or destination block is a Python block).
- Data to be exported to a destination.
Input arguments
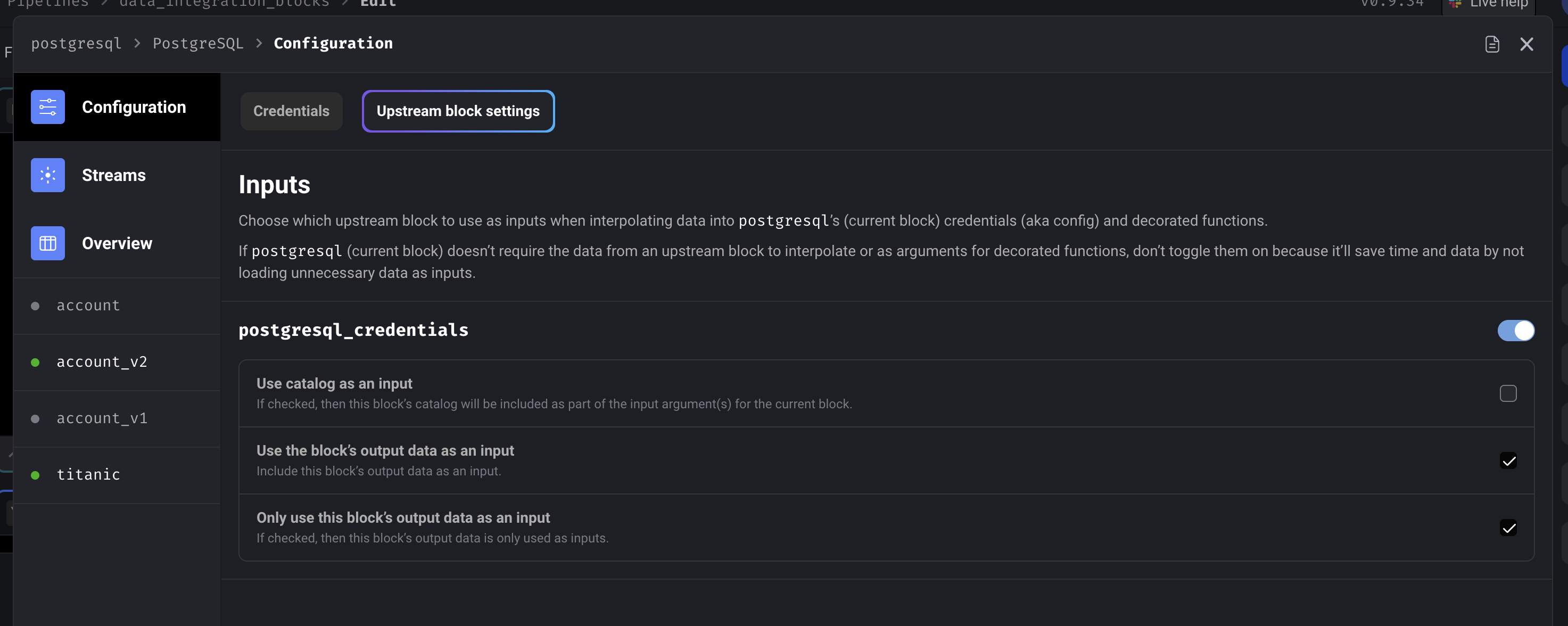
Follow these steps to use the output of an upstream block as an input:-
Open the data integration block’s configuration and click on the tab
labeled Upstream block settings.
- Toggle the name of the block you want as an input.
- Check the box labeled Use the block’s output data as an input.
Other options
Only use this block’s output data as an input
Only use this block’s output data as an input
If checked, then the upstream block’s output data is only used as inputs and won’t be ingested
and exported to the destination. This is only applicable to destination blocks.
Use catalog as an input
Use catalog as an input
If checked, then the upstream block’s catalog will be included as part of the input argument(s)
for the data integration block.
Examples using upstream data output as inputs
If you have an upstream block, namedpg_credentials, that has the following code:
YAML blocks
YAML blocks
If you have a data integration source or
destination block that depends on the above upstream block,
you can interpolate the output of the upstream block in the source or destination block’s
credentials like this:
Python blocks
Python blocks
Depending on how many upstream blocks your source or destination block uses as an input,
it’ll determine how many positional arguments are available in any of your decorated functions.
Examples using upstream block’s catalog as input
If you have an upstream block, namedtitanic_survival, that has the following code:
Here are examples on how to use the upstream block’s catalog as an input to the data integration’s
decorated functions:
Python blocks
Python blocks
Depending on how many upstream blocks your source or destination block uses as an input,
it’ll determine how many positional arguments are available in any of your decorated functions.The positional argument correlated to the upstream block that you’re using as an input
will be either a single object or a tuple. It’s a tuple if you checked the box
labeled Use catalog as an input in the data integration block’s configuration on
the tab labeled Upstream block settings.In this example, the last item in the tuple from the 1st positional argument (
e.g.
titanic_survival_data_and_catalog) contains a Python dictionary that represents
the catalog from the upstream block named titanic_survival.This catalog contains a key named streams that is a list of dictionaries containing
stream settings, metadata, and schema properties of the output data from the upstream
block titanic_survival.Here is an example of that catalog (a lot of the metadata and schema properties are omitted
from this example so that it’s not too lengthy):Data to be exported
Outputs from upstream blocks, as data to be exported, can only be used by destination blocks.
Output data from source blocks
Destination blocks don’t output any data to downstream blocks.
Shape of output data
All other types of blocks will receive the data integration source block’s output data either as a dictionary or as a list containing 2 or more dictionaries. The output data will be a dictionary if the source block is only fetching 1 stream. The output data will be a list of dictionaries if the source block is fetching 2 or more streams. The number of items in the list corresponds to the number of streams that the source block is configured to sync.Shape of dictionary
Each item in the list is a dictionary with the following keys:Sample output data
JSON format
JSON format
Load/Export stream data in parallel
For each stream in a data integration source block, you can enable that stream to have its data fetched in parallel while other streams for that source is being fetched. For each stream in a data integration destination block, you can enable that stream to have its data exported in parallel while other streams for that destination is being exported. This option can be turned on by editing a specific stream’s settings.
Incremental sync
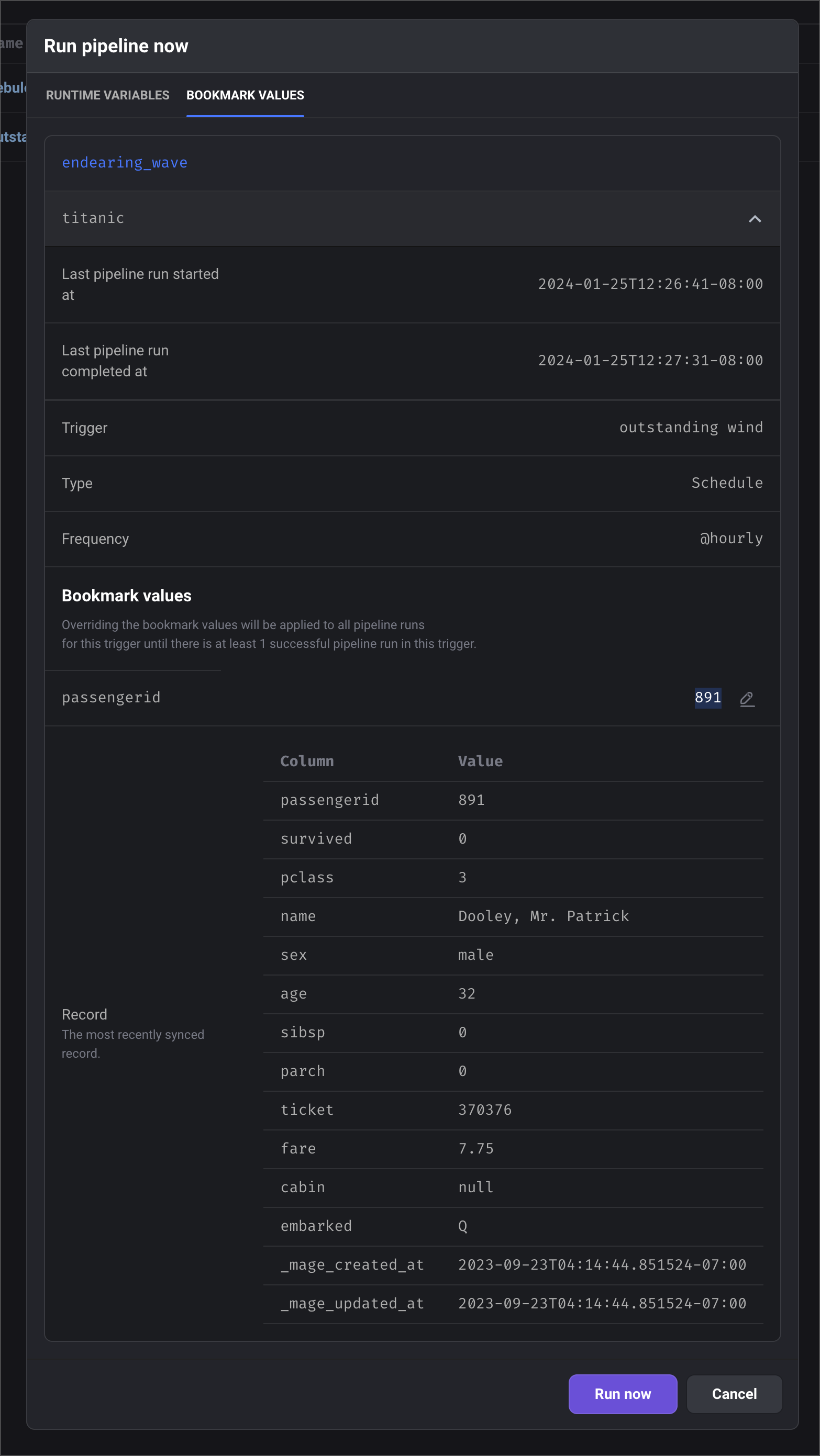
Synchronize your data incrementally after the 1st sync. When you choose 1 or more bookmark values in a stream, the value from that property will be saved after each successful sync. The next sync will use that value to compare to the next batch of records that need to be synced.Override bookmark values
If you want to change the last saved bookmark value for the next sync, you can do this in 2 ways:Trigger pipeline to run once
Trigger pipeline to run once
New trigger or edit an existing trigger
New trigger or edit an existing trigger
Example of bookmark values editor