Requires version
0.8.93 or greater.condition_failed.
An example condition
Take the following example: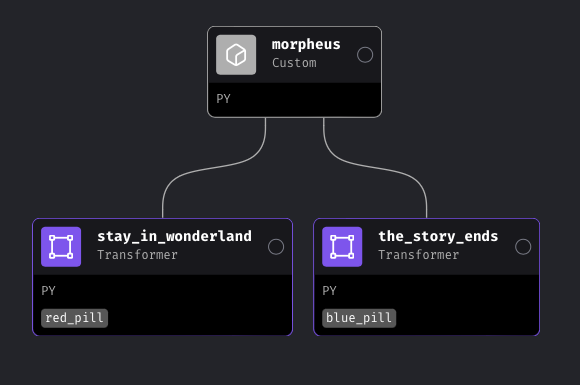
morpheus block returns a variable— pill, which is either red or blue. Both downstream blocks have conditionals associated with them. The red_pill block will only execute if pill is red, and the blue_pill block will only execute if pill is blue.
Here’s what the conditionals look like for each:
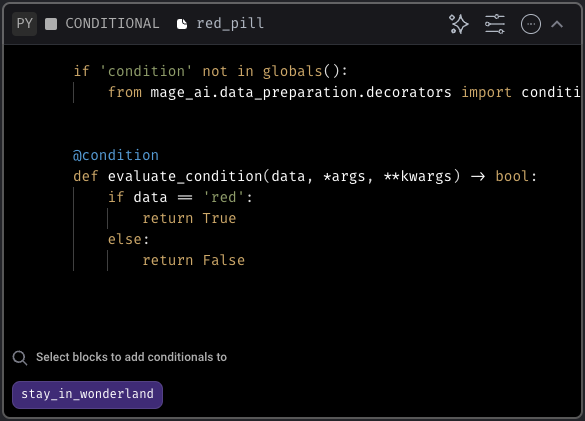
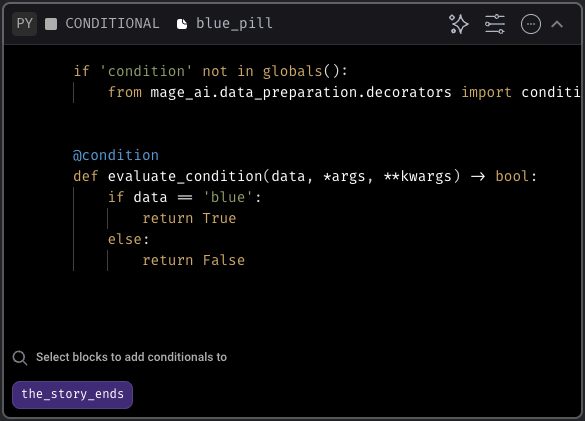
pill=red, the red_pill block will execute, and the blue_pill block will not. Additionally, any downstream blocks of the blue_pill block will not execute.
Add conditionals to your pipeline
Conditional blocks are “add-on blocks” in Mage— that means they’re added through the side panel on the right in the pipeline editor.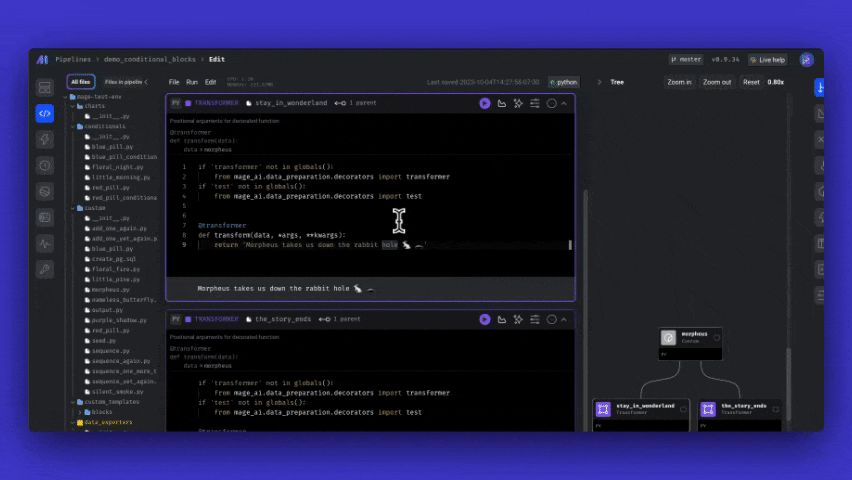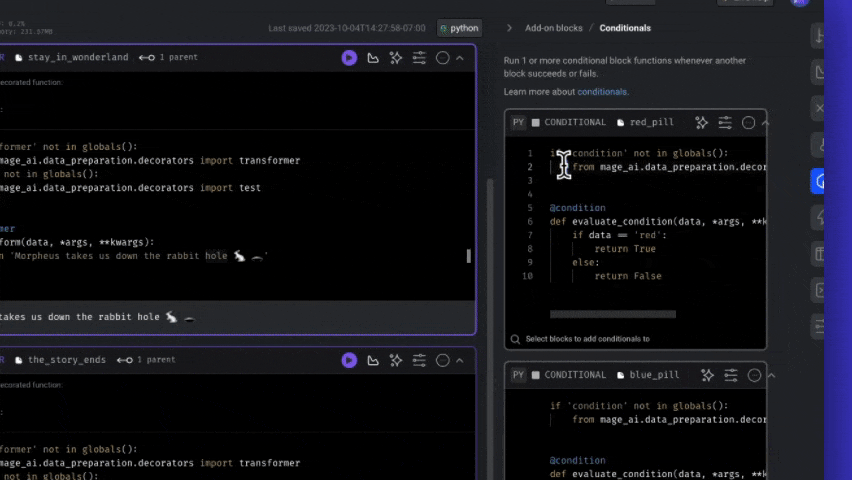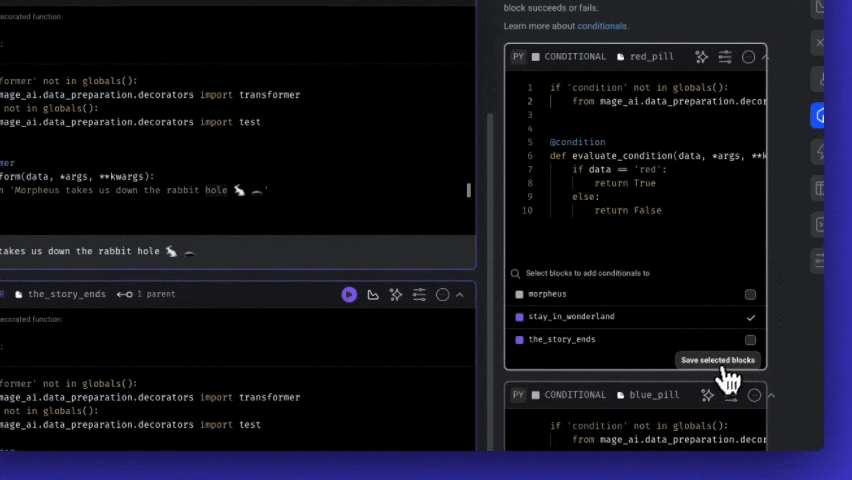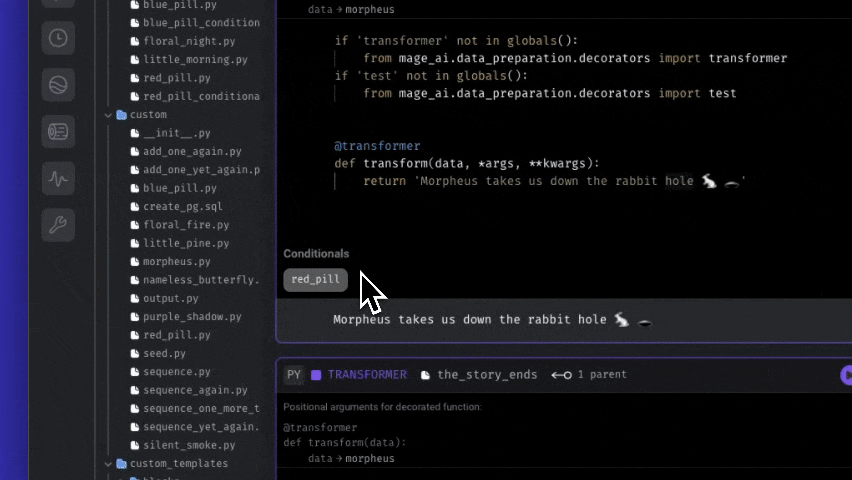
- On the right side of the page, expand the side panel by hovering, click the Add-ons icon in the navigation.
- Click the button Conditionals.
- Click the button + Conditional block.
- In the conditional block’s code, add a function that returns a boolean value. Be sure it’s decorated with
@condition. - Select the magnifiying class icon at the bottom of the block to associate your conditional with a block.