
Project
A Mage project forms the basis for all the work you do in Mage. It contains the code for your data pipelines, blocks, and other project-specific data. You can think of it like a GitHub repo— it can even track your file history, too. Check out our detailed project structure docs for more info.Pipeline
A pipeline contains references to all the blocks of code you want to run, charts for visualizing data, and organizes the dependency between each block of code. Each pipeline is represented by a YAML file (here’s an example) in thepipelines folder under the Mage project directory.
 Pipelines can be filtered, tagged, and grouped by various properties. See our docs page for more info.
Pipelines can be filtered, tagged, and grouped by various properties. See our docs page for more info.
Block
A block is a file with code that can be executed independently or within a pipeline. Together, blocks form a Directed Acyclic Graph (DAG), which we call pipelines. A block won’t start running in a pipeline until all its upstream dependencies are met. There are 8 types of blocks.- Data loader
- Transformer
- Data exporter
- Scratchpad
- Sensor
- dbt
- Extensions
- Callbacks
[project_name]/transformers/.
Sensor
A sensor is a block that continuously evaluates a condition until it’s met or until a period of time has elapsed. If there is a block with a sensor as an upstream dependency, that block won’t start running until the sensor has evaluated its condition successfully. Sensors can check for anything. Examples of common sensors check for:-
Does a table exist (e.g.
mage.users_v1)? -
Does a partition of a table exist (e.g.
ds = 2022-12-31)? -
Does a file in a remote location exist (e.g.
S3)? - Has another pipeline finished running successfully?
- Has a block from another pipeline finished running successfully?
- Has a pipeline run or block run failed?
transform_users has finished running successfully for the current execution
date:
This example is using a helper function called
check_status that handles the
logic for retrieving the status of a pipeline run for transform_users on the
current execution date. You can optionally pass block uuid and hours
parameters to check_status to check the status of a block run or within a
interval of time.Data product
Every block produces data after it’s been executed. These are called data products in Mage. Data validation occurs whenever a block is executed. Additionally, each data product produced by a block can be automatically partitioned, versioned, and backfilled. Some examples of data products produced by blocks:- 📋 Dataset/Table in a database, data warehouse, etc.
- 🖼️ Image
- 📹 Video
- 📝 Text file
- 🎧 Audio file
Trigger
A trigger is a set of instructions that determine when or how a pipeline should run. A pipeline can have 1 or more triggers. There are 3 types of triggers:- Schedule
- Event
- API
Schedule
A schedule-type trigger will instruct the pipeline to run after a start date and on a set interval. Currently, the frequency pipelines can be scheduled for include:- Run exactly once
- Hourly
- Daily
- Weekly
- Monthly
- Every N minutes (coming soon)
Event
An event-type trigger will instruct the pipeline to run whenever a specific event occurs. For example, you can have a pipeline start running when a database query is finished executing or when a new object is created in Amazon S3 or Google Storage. You can also trigger a pipeline using your own custom event by making aPOST
request to the http://localhost/api/events endpoint with a custom event
payload.
Check out this
tutorial on how
to create an event trigger.
API
An API-type trigger will instruct the pipeline to run after a specific API call is made. You can make a POST request to an endpoint provided in the UI when creating or editing a trigger. You can optionally include runtime variables in your request payload.Run
A run record stores information about when it was started, its status, when it was completed, any runtime variables used in the execution of the pipeline or block, etc. Every time a pipeline or a block is executed (outside of the notebook while building the pipeline and block), a run record is created in a database. There are 2 types of runs:Pipeline run
This contains information about the entire pipeline execution.Block run
Every time a pipeline is executed, each block in the pipeline will be executed and potentially create a block run record.Log
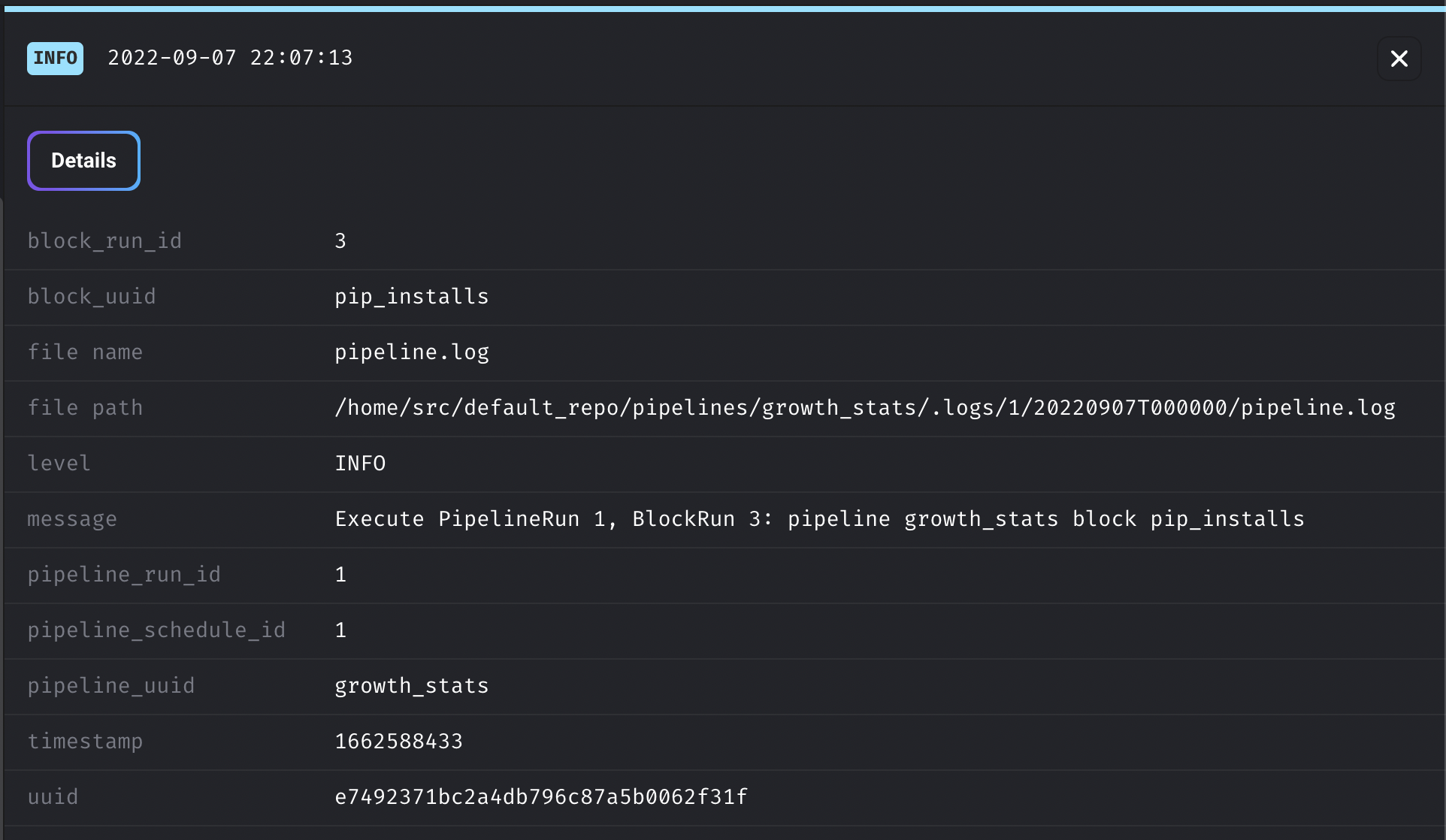
A log is a file that contains system output information. It’s created whenever a pipeline or block is ran. Logs can contain information about the internal state of a run, text that is outputted by loggers orprint statements in blocks, or errors and stack traces
during code execution.
Here is an example of a log in the
Data pipeline management UI:
 Logs are stored on disk wherever Mage is running. However, you can configure
where you want log files written to (e.g. Amazon S3, Google Storage, etc).
Logs are stored on disk wherever Mage is running. However, you can configure
where you want log files written to (e.g. Amazon S3, Google Storage, etc).