🧙♀️ Welcome to Mage
Mage is an open-source, hybrid framework for transforming and integrating data. ✨




🦄 Make data magical
We put the fun in fun-ctional programming. Mage is a hybrid framework that combines the best of both worlds: the flexibility of notebooks with the rigor of modular code.
- Extract and synchronize data from 3rd party sources.
- Transform data with real-time and batch pipelines using Python, SQL, and R.
- Load data into your data warehouse or data lake using our pre-built connectors.
- Run, monitor, and orchestrate thousands of pipelines without losing sleep.
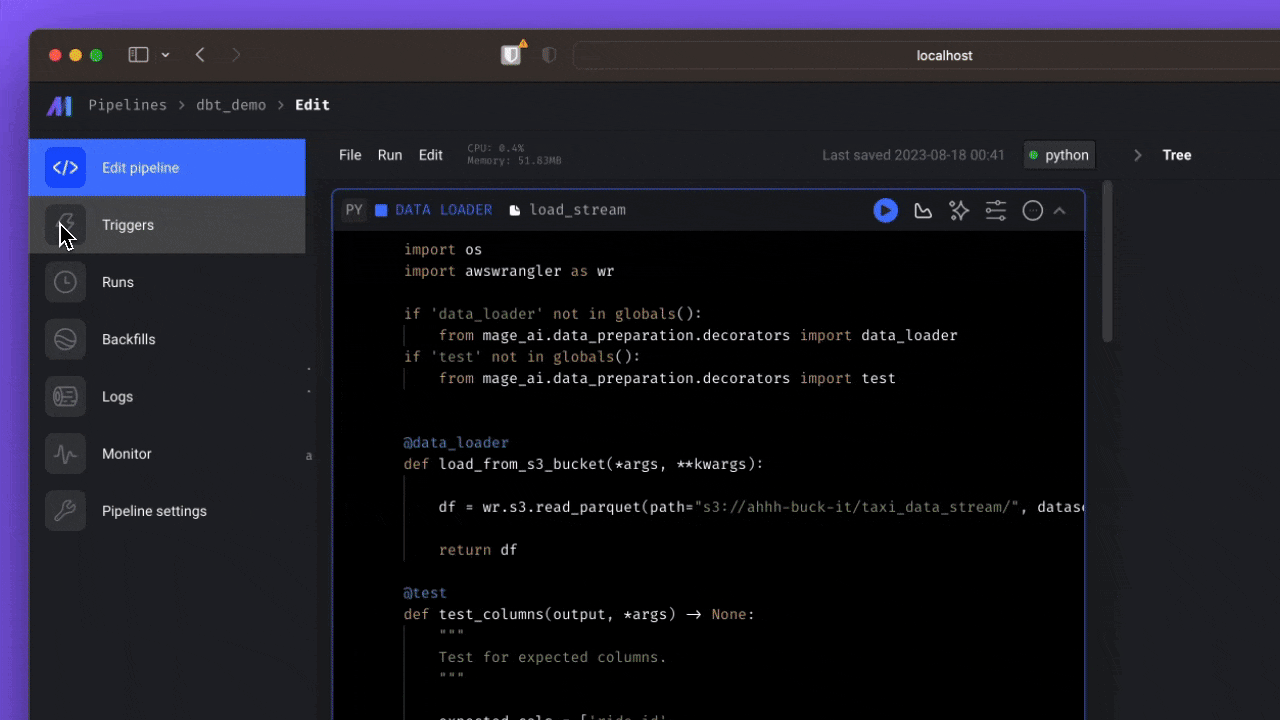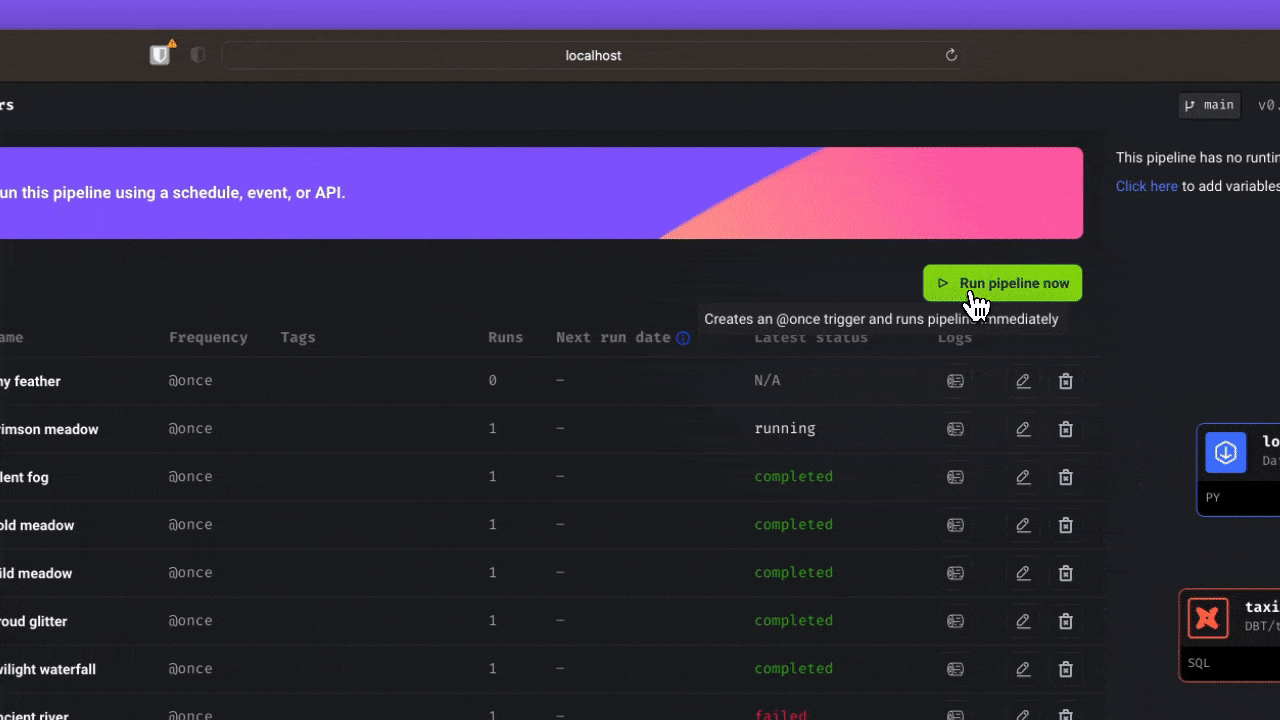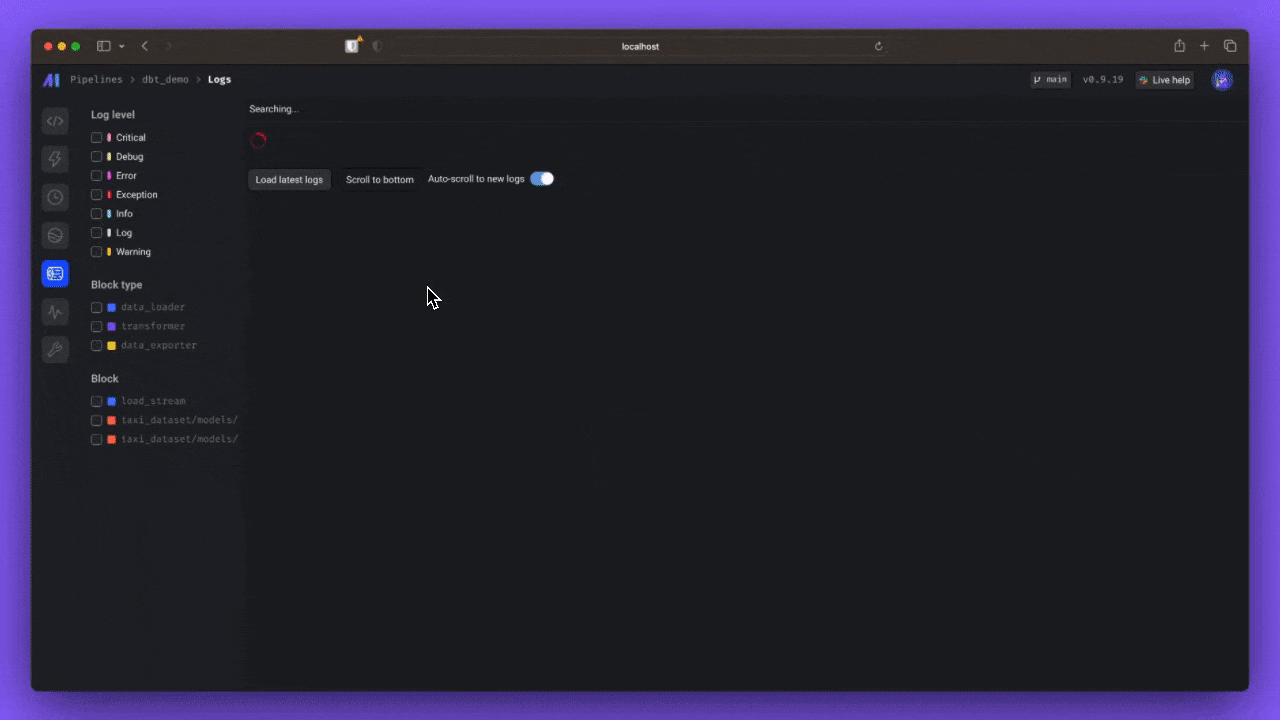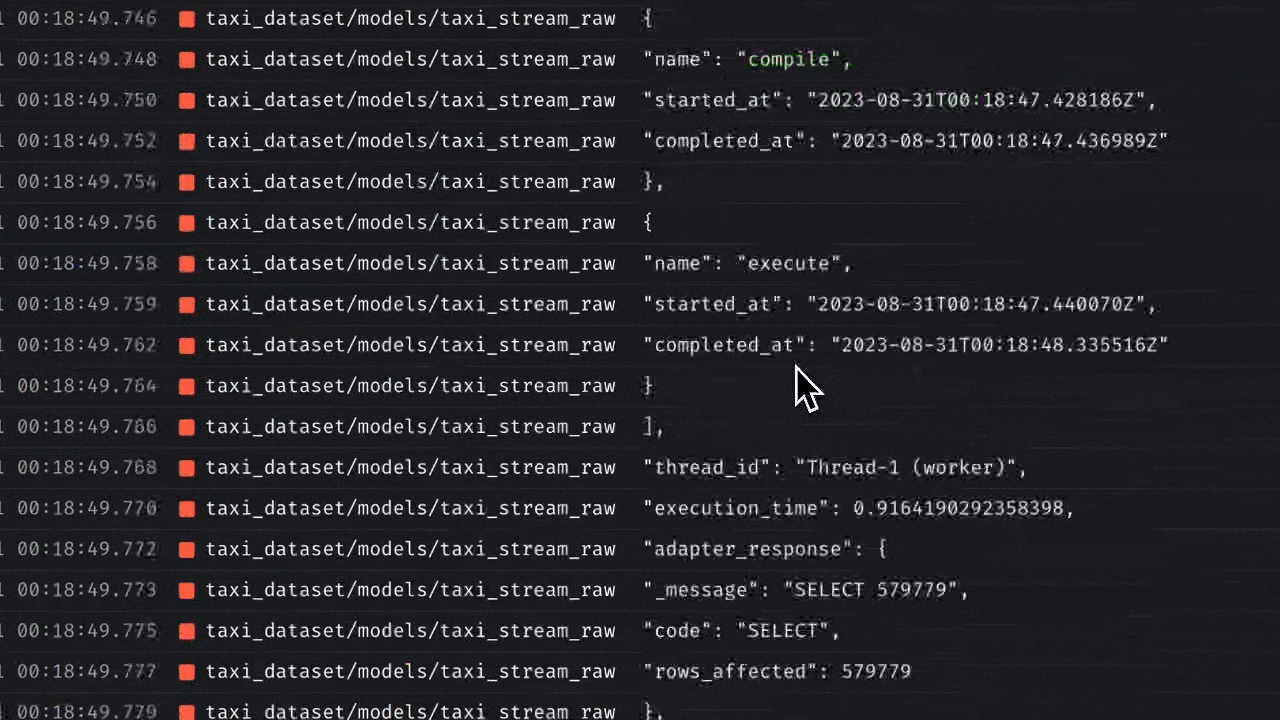
🔨 Build
Have you met anyone who loves developing in Airflow? That’s why we designed an easy developer experience that you’ll enjoy.
- Simple developer experience: Start developing locally with a single command or launch a dev environment in your cloud using Terraform.
- Language of choice: Write code in Python, SQL, or R in the same pipeline for ultimate flexibility.
- Engineering best practices built-in: Every step in your pipeline is a standalone file with modular code that’s reusable and testable. No more DAGs with spaghetti code 🍝.
- Bring your favorite tools: Write dbt models, use your favorite IDE, track changes with Git, and much much more.

🔍 Preview
Don’t waste time waiting for your DAGs to finish testing. Get instant feedback from your code every time you run it.
- Interactive code: Immediately see results from your code’s output with an interactive notebook UI.
- Data is a first-class citizen: Each block of code in your pipeline produces data that can be versioned, partitioned, and cataloged for future use.
- Collaborate on cloud: Develop collaboratively on cloud resources, version control with Git, and test pipelines without waiting for an available shared staging environment.

🚀 Launch
Don’t have a large team dedicated to Airflow? Mage makes it easy for a single developer or small team to scale up and manage thousands of pipelines.
- Fast deploy: Deploy Mage to AWS, GCP, or Azure with only 2 commands using maintained Terraform templates.
- Scaling made simple: Transform very large datasets directly in your data warehouse or through a native integration with Spark.
- Observability: Operationalize your pipelines with built-in monitoring, alerting, and observability through an intuitive UI.
🔮 Features
| 🎶 | Orchestration | Schedule and manage data pipelines with observability. |
| 📓 | Notebook editor | Interactive Python, SQL, & R editor for coding data pipelines. |
| 🏗️ | Data integration | Synchronize data from 3rd party sources to your internal destinations. |
| 🚰 | Streaming | Ingest and transform real-time data. |
| 🧱 | dbt | Build, run, and manage your dbt models with Mage. |
🏔️ Core design principles
Every user experience and technical design decision adheres to these principles.
| 💻 | Easy developer experience | Open-source engine that comes with a custom notebook UI for building data pipelines. |
| 🚢 | Engineering best practices | Build and deploy data pipelines using modular code. No more writing throwaway code or trying to turn notebooks into scripts. |
| 💳 | Data as a first-class citizen | Designed from the ground up specifically for running data-intensive workflows. |
| 🪐 | Scaling made simple | Analyze and process large data quickly for rapid iteration. |
🛸 Core abstractions
These are the fundamental concepts that Mage uses to operate.
| 🏢 | Project | Like a repository on GitHub; this is where you write all your code. |
| 🪈 | Pipeline | Contains references to all the blocks of code you want to run, charts for visualizing data, and organizes the dependency between each block of code. |
| 🧱 | Block | A file with code that can be executed independently or within a pipeline. |
| 🤓 | Data product | Every block produces data after it’s been executed. These are called data products in Mage. |
| ⏰ | Trigger | A set of instructions that determine when or how a pipeline should run. |
| 🏃♂️ | Run | Stores information about when it was started, its status, when it was completed, any runtime variables used in the execution of the pipeline or block, etc. |
👨👩👧👦 Community
Individually, we’re a mage.
🧙 Mage
Magic is indistinguishable from advanced technology. A mage is someone who uses magic (aka advanced technology).
Together, we’re Magers!
🧙♂️🧙 Magers (
/ˈmājər/)A group of mages who help each other realize their full potential! Join us on Slack.
✨ This documentation & project are brought to you by the following magical individuals (learn more about contributing here):
🪪 License

Was this page helpful?